
Search engines remain an integral component of any marketing strategy, potentially driving the kind of traffic that other channels simply can’t. If you’re neglecting to optimize your content for Google and other platforms, you’re going to have a much harder time achieving your marketing goals, short- and long-term.
Consider the impact Google has on your website based on usage: Today, Google handles more than 13.7 billion daily searches, with the average person using this platform alone three to four times per day. Understanding how the search engine crawls, classifies, and decides which content is relevant is critical if you want to improve your search rankings and by extension, drive traffic to your site and increase sales.
In this article, Senior SEO Strategist, Eric Solomon, will go over the basic inner workings of the search engines to help you understand all of the elements at play when it comes to ranking your content–or burying it a few pages in.
What You’ll Learn:
- How search engines work
- How search engine algorithms work
- The Role of User Experience and Intent in Search Engine Results
- Keeping Content Fresh: How Search Engines Update Results
- Advanced Search Engine Concepts: AI, Automation, and the Future
What Is a Search Engine?
To start with, let’s explain search engines in simple terms: A search engine is a web-based software that allows users to conduct searches for all types of website content. Users can search for everything from brands and products to places and people, with engines returning the most relevant results based on intent and the reputability of the source.
How Do Search Engines Work?
Most search engines operate on a three-stage process:
- Crawlers sift through websites to identify fresh information and updates
- Search engines then collect, categorize, and index content to expand their information databases
- Engines rank individual pages and sites based on relevance to someone’s query based on how well the source matches the term and the search intent behind it
To help explain search engines and how they operate, let’s walk through a little scenario:
A developer for an ecommerce website publishes a product page, complete with a product title header, image, and a description, with other on-page SEO elements like relevant keywords related to the product.
Google’s search crawler eventually finds that page, possibly with the help of an XML sitemap, allowing it to “understand” what’s on the page and index it in search results, enabling visibility on the engine.
Then, people entering searches related to that product could come across this product page in various results, including traditional organic search results, featured snippets, rich results, or AI-generated results like Google’s AI Overviews.
Let’s get into greater depth about how search engines operate.
What Occurs First When a Search Engine Operates?
What does the inner working of search engines look like from the start?
Well, it all begins with the initial query. A user enters a search term into the engine before it uses an algorithm to find the most relevant results for the user.
After entering this term, the search engine goes through a process to present the results that match the query the closest.
My Expert Insights into How Search Engines Work
We use them every day, but how do search engines work? In short, the inner workings of search engines involve crawling, indexing, and ranking websites while returning the most relevant results to users.
By writing great content and organically optimizing it with keywords, backlinks, structured data, and other critical components, you’ll gain and maintain a competitive edge more easily.
Having learned how search engines work and how to optimize effectively for them, I’ve seen our clients here at Ignite Visibility thrive with strong SEO campaigns.
One of our clients, a quick service food and beverage franchise, went from attracting low-quality leads and insufficient conversions to a 106% increase in quality leads, a 40% rise in organic conversions, and a 29% growth in total lead volume, all thanks to a highly targeted SEO campaign.
With the right approach to SEO knowing search engine basics, you’ll be able to experience these kinds of benefits with your strategy.
Now, let’s explore more about how an internet search works and what occurs first when a search engine operates.

The 3 Core Stages: Crawl, Index, and Rank
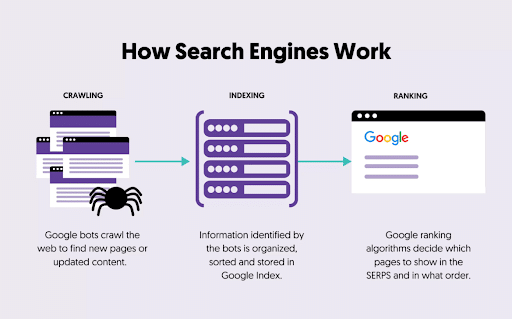
Search engines do three key things: crawl, index, and rank. Here’s a look at how Google search engine works step by step, and how to optimize for each step:
1. Crawling
How does a search engine find results?
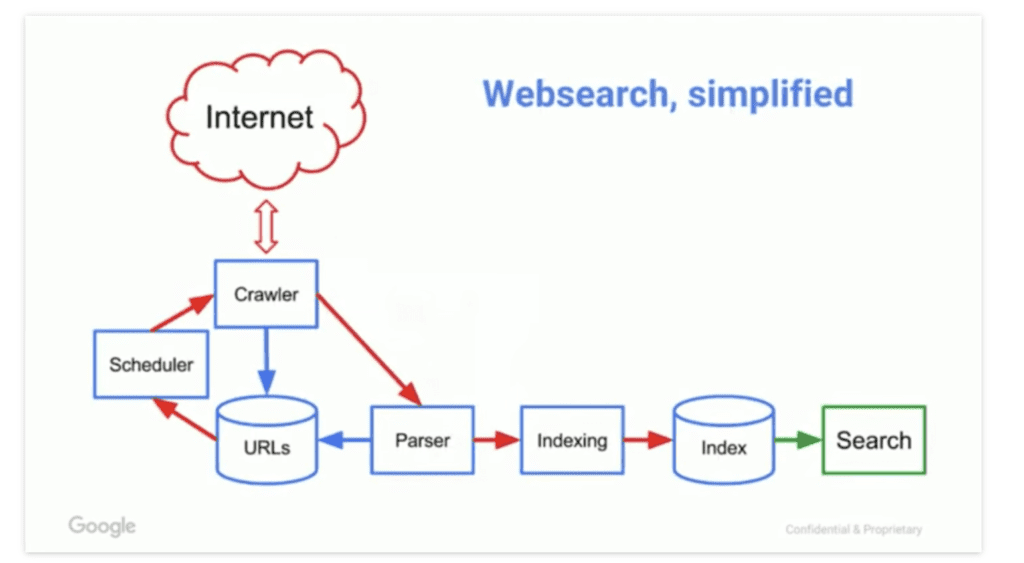
Crawlers, also known as bots or spiders, are computer programs designed to automatically search through webpages to understand and organize content to build an index. Think of the crawler as the Google search motor that enables the engine to access all pages and determine whether they’re worthy of appearing in search results.
You may also wonder: How do search engines use sitemaps? Search engines kick off the crawling process by taking a list of known URLs from previous crawls and user-submitted sitemaps, which go to a scheduler that determines when to crawl each link.
Another factor that allows search engine bots to crawl a site is a robots.txt file, which sits in the site’s root directory to indicate what bots can or cannot crawl.
From there, the Googlebot crawlers visit those known websites and rely on the links within those sites to discover new pages. The software is programmed to pay special attention to new websites, dead links, and updates to existing sites.
And what’s the job of links when building a search engine results list? The crawler’s primary role is to locate new data and collect “notes” about what each page is about, what it’s for, and who might find it useful. Crawled pages then go a parser, where critical data is extracted, then indexed. Parsed links are added to the “list,” where the scheduler determines when to crawl and recrawl those new pages.
Today, crawlers use a combination of AI and machine learning to better understand which pages match a query based on user intent and the relevance of the content. More specifically, AI uses a large language model (LLM) to understand natural language, converting it into a format that search engines can read.
2. Indexing
After a crawler finds a page, the search engine renders it just like a browser would. During that process, the search engine analyzes the content and stores it in a database known as an index, which contains all of the rankable sites and pages within the search engine. The index stores data about each URL, as well as the following pieces of information:
- Keywords and topics – What concepts does this page cover?
- Schema – What type of content was crawled? Microdata, known as schema allows website owners to mark-up specific parts of a webpage to indicate specific features and content types. (For more direction, this article covers which markups work best by industry).
- Freshness – in other words, when was the last time this page was updated?
- Engagement – How often do people interact with this page? And how they interact with the various on-page elements?
Again, AI and machine learning play a critical role here today in helping search engines determine which sites to index and rank.
To make sure your website indexes and ranks, it’s important to make sure your content adheres to Google’s E-E-A-T guidelines, meaning that your content must exhibit:
- Experience
- Expertise
- Authority
- Trustworthiness
3. Serving & Ranking
At this stage, the search engine has collected website data through crawling and organized those findings via indexing. The next stage is serving and ranking web pages so that users receive the most relevant information possible.
When a user enters a search query, it’s the search engine’s job to find the most relevant answer from the index based on several key factors.
I’ll get to those factors in a moment, but the basic idea here is, Google aims to deliver the highest-quality results, then factors in other considerations like location, device, language, search history, and intent to further improve the user experience.
AI can determine which results will be the most relevant based on the query, and, in fact, Google and other search engines often incorporate generative AI into search results. For instance, users can see AI Overviews at the top of many search results today, and Google allows users to do even deeper dives in their searches with AI Mode.

Of course, other developments over the years have continually impacted how search engines work and rank websites. Examples include a focus on mobile-first optimization for people using smartphones and tablets, user experience metrics like bounce rate and session duration, and the need for quality and quantity of content.
Ranking Factors
In learning how search engines work, you also need to consider these key factors and how they play into indexing and ranking:
- Content: One major component of an indexable and rankable site or page is the content it contains. Search engines look for content that’s well-optimized with relevant short- and long-tail keywords, along with well-structured and -written content that brings real value to users and appeals to E-E-A-T guidelines.
- Backlinks: In addition to on-page SEO and content, a search engine checks for a site’s backlinks to see if other authoritative sites link back to that indexed site. The more high-quality backlinks a site has, the more likely it is to appear worthy of higher rankings in organic results.
- User Experience (UX): You also need to consider your site’s UX, or the ability for people to easily navigate and view each page. A good UX will signal to search engines that your site is user-friendly, further helping with rankings.
- Intent: Another item to think about is the intent that each page targets, specifically each keyword within that page. Users might want to learn more information about a certain topic, compare businesses or products, get more details about a particular brand, or achieve another goal. Appealing to this intent will help hone your ranking efforts.
The Role of User Experience, Core Web Vitals, and Intent in Search Engine Results
How do search engines work based on user experience and intent? In understanding how an internet search works, it’s critical to understand both of these components.
The Rise of Mobile-First Indexing
One crucial development is the use of mobile-first indexing, as more and more search engine users tend to conduct searches on mobile devices. Today, mobile searches actually account for around 63% of all organic search engine visits.
This factor means that you must ensure your website is mobile-optimized to connect with users through mobile searches.
Today, Google ranking systems prioritize mobile versions of content, making mobile optimization particularly crucial for today’s SEO. Optimizing for voice search with conversational keywords that connect with Siri and other mobile search solutions will also assist with these efforts.
The Importance of Core Web Vitals
Another ranking factor to think about is Google’s Core Web Vitals. Websites need to appeal to these metrics to show that they provide the ideal user experience.
These metrics include:
- Large Contentful Paint (LCP): Tracks the length of time it takes for a page’s largest elements to show up for users. This metric should be no more than 2.5 seconds.
- First Input Delay (FID): Detects interactivity based on how long it takes for a browser to respond to a user’s initial interaction.
- Cumulative Layout Shift (CLS): Measures the unexpected shifting of a page’s layout as it loads, ideally measuring less than 0.1.
Google will review each of these factors to determine whether a site is worth ranking based on its UX.
Engagement Signals
Search engines also keep track of user engagement signals to impact rankings.
The following are a few of these metrics:
- Click-through Rate: The percentage of search engine users who click on a search engine result.
- Bounce Rate: The percentage of people who leave a website immediately after visiting a page through search results.
- Dwell Time: The amount of time between when a person clicks on a search result and returns to the search engine results page.
- Time on Page: The average time users view a particular web page.
All of these contribute to ranking systems’ perceived UX. For example, if a page has a high click-through rate but a high bounce rate and short dwell time, this could indicate that the page content doesn’t provide real value or match the user’s search intent, which can lead to penalties.
In learning more about how search engines work, you’ll discover how these metrics can indicate the quality of your website in the eyes of Google and other platforms.
Advanced Search Engine Concepts: AI, Automation, and the Future
How does a search engine work in today’s environment, and what does the future hold for these platforms?
AI is one of the main developments as Google Gemini, ChatGPT, and other models continually develop over time. AI can determine which results (and answers) are the most relevant by gaining a deeper understanding of the intent and meaning behind search queries.
In the process, machine learning enables AI to “learn” about users and what they want, facilitating continual improvement as search engine bots maximize relevance.
AI Overviews are especially important to rank for, as they feature more prominently than featured snippets in many cases, taking up more space at the top of SERPs. In fact, for many searches, only paid sponsored search results will appear higher than Overviews, with the latter starting off organic search results.
You must also appeal to other generative engines like ChatGPT and Perplexity to maximize AI visibility, which can help establish your site as a trustworthy source of information in your industry, eventually earning more clicks from these and other results.
Critical supporting data can help you rank higher for AI results, such as:
- Structured data, including schema markup that indicates what each page is about to give AI crawlers more insight into what your content is about
- Entity-based mentions that track how AI mentions your brand within results
- Short paragraphs, bulleted lists, and other types of structured content that appeal to natural language processing (NLP) algorithms
- Unique research, case studies, stats, and other data that helps establish you as an authority to boost rankings
So, how do search engines work looking into the future? Simply put, conversational AI will be one of the biggest trends, with AI Mode and other developments turning search engines into virtual assistants. As people’s behavior changes over time, these platforms will also adapt.
With the continued integration of AI and machine learning, search engine results are also only going to get more interactive and relevant, making it important for sites to incorporate generative engine optimization (GEO) into their SEO efforts.
How Do Search Engine Algorithms Work?
Finding and indexing websites is just the beginning. Search engines index millions, or in the case of Google, billions of pages, and as a result, rely on algorithms to deliver and rank the most relevant results.
For example, Google’s March 2025 core update aimed to penalize spammy and low-value pages while helping high-quality content rank. It also worked to punish sites using AI-generated or thin content.
Beyond the basics, there are also some things you should know about the algorithm and how it determines what is good, relevant, timely, and so on.
RankBrain
RankBrain is a machine-learning algorithm introduced in 2014, designed to help Google process search results. The algorithm performs two main tasks in understanding search queries and measuring user satisfaction.
Before RankBrain, Google would scan the index for the exact keyword someone typed into the search bar. The problem there was, Google had never seen 15% of those keywords.
Today, RankBrain doesn’t just match keywords, it tries to determine what searchers mean when they enter a specific query.
On the UX side, RankBrain aims to provide the results that best serve user needs.
It looks at the following areas to understand how searchers engage with the results:
- Dwell time
- Bounce rate
- Pogo-sticking (aka when a user clicks multiple results before finding one that answers their question).
- Click-through rates
From there, the algorithm adjusts rankings based on its findings.
For example, if RankBrain detects that a URL positioned toward the bottom of the page is delivering a better answer to users than higher-ranked results. The algorithm will reorder the rankings and place the more relevant content at the top of the page.
Or, if it notices a high number of bounces on a particular result, it might not be the most relevant answer to a particular query and will make changes based on those patterns.
RankBrain learns from user behavior and over time gets better at determining the intent behind search queries.
BERT
In late 2019, Google added a new algorithm to the mix to help analyze search queries. Like RankBrain, BERT is used to pick up on the nuances and context implied when searchers enter a query to deliver the most relevant content to the user. It is also used to determine which featured snippets and SERP features deliver the best possible answer.
BERT is additive to RankBrain’s existing capabilities and is used exclusively for queries, not on-page content.
AI Integrations
Various AI models have also become integrated into search algorithms, enabling more accurate and relevant results. For example, Google Gemini 2.0 harnesses the power of AI and machine learning to even more effectively optimize results.
As mentioned, Google and other sites like Bing are also incorporating AI-generated overviews and “chat” functions that are changing the way people search.
We’re seeing a lot more long-tail conversational keyword inclusions, many of which come through voice search. People can also interact in greater depth with search engines using tools like Google’s AI Mode, further keeping people from exploring outside of SERPs.

Relevance
To determine webpage relevance, search engines look for signals that a page contains the information users are looking for using a combination of interaction data, keyword mentions, and other factors.
Here’s a look at the four areas Google uses to match queries to relevant content.
Style
Content style refers to the medium—text, image, or video. For most queries, one style tends to dominate the results. For instance, if I type in “content strategies for B2B marketing,” I’ll get a long list of blog posts on that topic:
Alternatively, if I type in something less specific like “hiking boots,” Google doesn’t have much to work with, and as a result, serves up shopping results, images, local retailers, and “best of” lists.
Format
The algorithm also considers which format makes the most sense based on the query. For example, all of the top-ranking results for “SEO tips” are numbered lists.
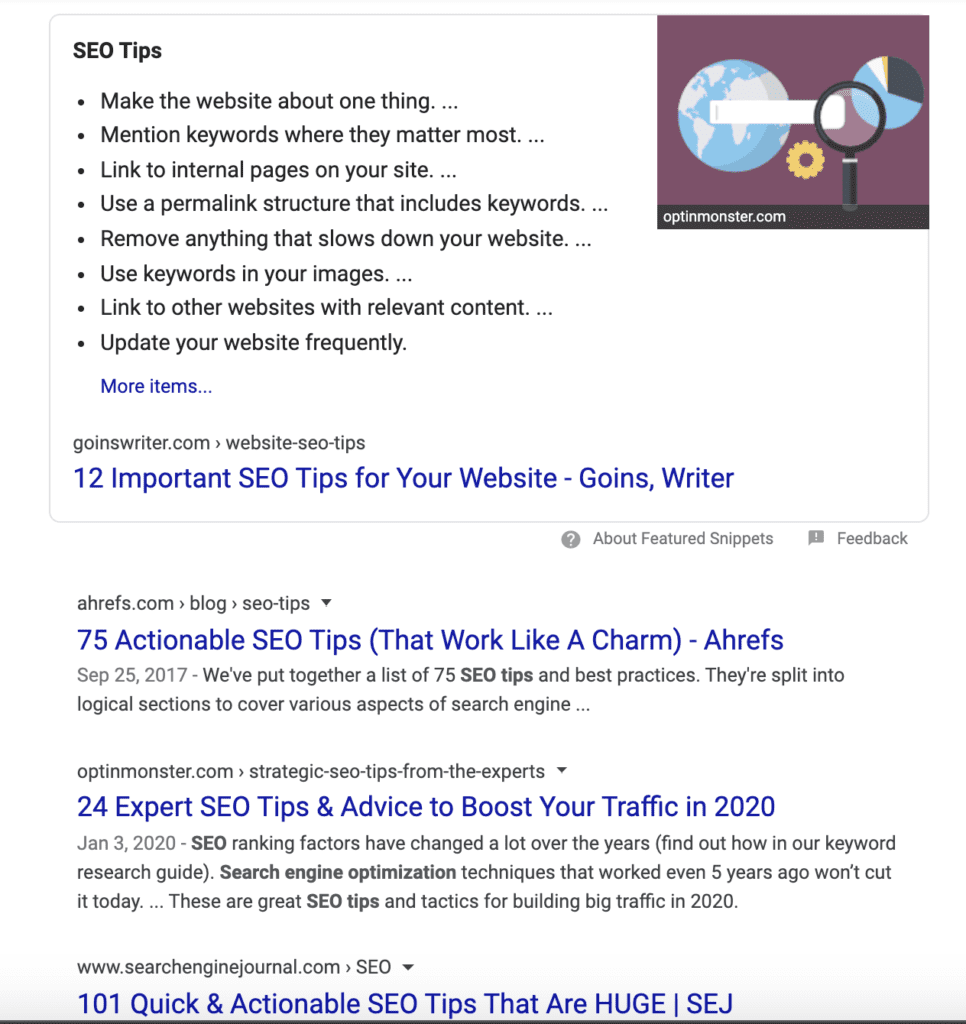
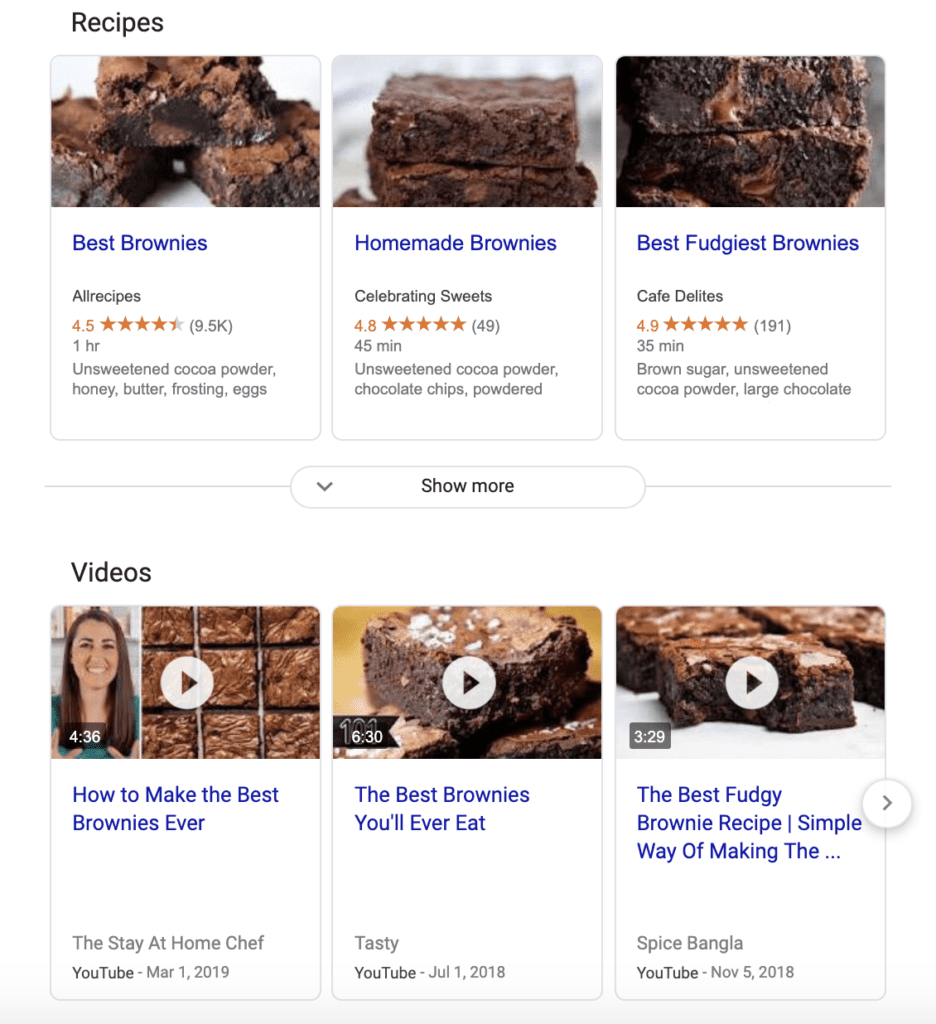
Whereas, if I type in “how to make brownies,” the top results are all recipes, not blog posts or news updates.
Type
The content type is used to identify the purpose of the content, sorting them into the following categories: product pages, category pages, blog posts, videos, and landing pages.
Again if I ask Google how to make brownies, the top results are informational—a mix of video and text-based recipes I can review to find the tastiest-sounding option.
In this case, it doesn’t make sense to serve up a category page where I can buy brownie mix, even though that would be one way of achieving my goal.
Angle
The content angle describes the key selling point of the content. With the brownies example, the dominant angle is recipes for brownies, with the SEO tips example, it’s a roundup of tips and tricks.
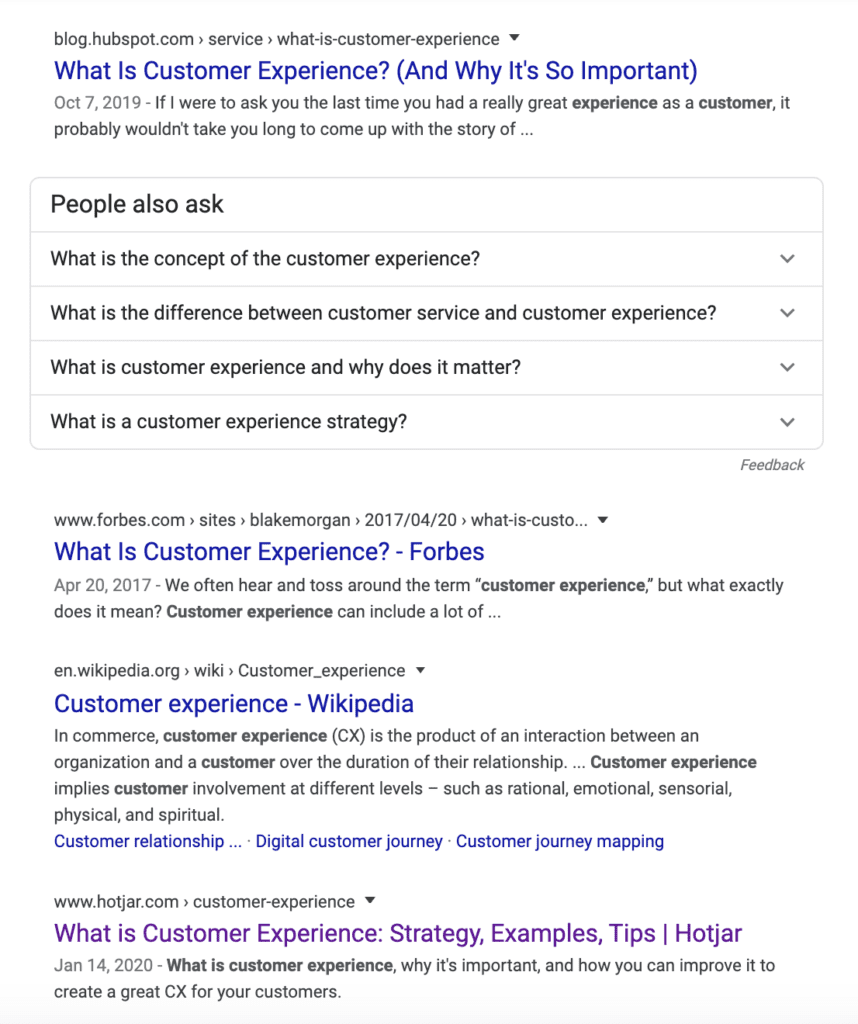
Now, if I type in something like “what is customer experience?” the dominant angle is introductory posts aimed at defining CX and providing examples.
Context & Setting
According to Google, information about your search history, location, and search settings also factor in to creating a relevant experience for the user.
If you search for “best auto repair” or “pizza places open late” Google will serve up a list of results nearby, highlighting the top results in the local 3-pack and showcasing your options using the map results.
Freshness
Google’s Freshness algorithm is used to deliver results related to trending topics, news items, and anything that’s “happening right now.” For example, something like a search for movie times requires demands the latest results.
Content Quality
It’s in Google’s best interest to deliver high-quality content to its users. The challenge here is, quality content is hard to define. To combat this issue, the search engine uses a set of guidelines called, EAT to help its quality raters objectively separate the good from the bad.
EAT stands for expertise, authority, and trust, and in a nutshell, provides a framework for identifying (and for marketers, creating) content that accomplishes the following:
- Anticipates searcher needs and exceeds expectations.
- Provides comprehensive answers to questions.
- Is useful to the reader.
- Claims are backed by credible sources.
If you’d like to learn more, I go over EAT guidance in more detail, here.
Usability
Finally, the algorithm also looks for content that is easy to consume. Factors like proper formatting, mobile-friendliness, page speed, and accessibility also help determine ranking.
Optimization Framework to Help Boost Rankings
In optimizing your content to achieve higher rankings and overall visibility, here’s a checklist to guide your next strategy:
- Technical SEO: To give your site a good foundation, focus first on technical SEO elements, such as mobile-friendliness, site speed, robots.txt, UX, HTTPS, and XML sitemaps that assist with crawling and indexing.
- On-Page SEO: The next item involves developing high-quality, valuable content that connects with users’ search intent, complete with natural keyword inclusions, title tags, meta descriptions, and overall user-friendliness.
- Off-Page SEO: Obtain plenty of high-quality backlinks to your site from industry blogs, news sites, and other relevant authoritative sources, which will develop a healthy backlink profile that complements on-page efforts.
- Website Architecture: Organize all of your content to create the optimal user experience, with effective internal linking to improve link equity, along with a pillar content strategy that can ultimately help build topical authority.
- Performance Measurement and Analytics: Regularly monitor and measure performance based on your goals, whether you want to get more traffic to your site, increase time on page for key pages, or drive more conversions, taking steps to optimize based on the results.
Keeping Content Fresh: How Search Engines Update Results
How do search engines work to keep search results consistently relevant? And how do you build discovery and relevance for search engines?
Search engines tend to prioritize fresh content to answer certain time-sensitive queries. The more topical a topic is, the fresher your content needs to be to show up for it, whether discussing industry trends or a recent news headline on your website.
Search engines use real-time indexing to find and rank the most relevant and recent content, and even if your content is evergreen, it could benefit from updates over time.
Updating your content can keep your site consistently relevant and potentially boost your rankings for new and existing terms.
FAQs
1. How do search engines work step by step?
Here is how Google search engine works step by step:
- Search engine bots crawl your site to discover it.
- These bots then index the page, adding it to the search engine’s database of URLs it can rank.
- Engines analyze searchers’ queries to understand their intent, informing rankings.
- Based on their relevance and value, engines rank pages in SERPs.
2. What are the three stages of search engines?
- Crawling: Bots first crawl a site using XML sitemaps and the overall site structure.
- Indexing: Engines then index pages to enable them to rank for certain terms.
- Ranking: The final step involves ranking pages when users enter relevant queries based on context and intent.
3. How does Google rank websites?
So, how does the Google search engine work? Google prioritizes pages that are mobile-friendly, with high-quality content and a user-friendly experience that provides real value while optimizing for certain on-page and off-page SEO components. The engine then matches the best results to relevant search terms.
4. What is crawling and indexing?
Let’s explain search engine basics: Crawling is a process that entails search engine bots discovering new websites or pages, while indexing involves adding those URLs to an engine’s database, allowing them to appear in organic search results.
5. How do search engines find new pages?
Search engine bots, also known as crawlers or spiders, automatically seek out new URLs on new and existing websites across the web. XML sitemaps and structured content can enable these bots to “crawl” each URL, followed by indexing them if they meet the search engine’s indexing criteria.
6. How does AI affect search engines?
How does a search engine work with AI? Today, Google and other search engines incorporate generative engine results like AI Overviews and AI Mode, delivering results to users using large language models (LLMs) and natural language processing (NLP), supplementing traditional organic results.
7. What factors affect search engines?
How do search engines work to index and rank? Here are some key factors:
- Content quality and relevance
- UX signals like fast page load speeds and mobile-optimized content
- Technical SEO components such as URL structure and crawl budget
- Local SEO factors, including business names, addresses, and phone numbers, along with the user’s location
- Search context based on user intent
8. Why is my website not showing on Google?
If your website isn’t appearing in Google search results, this could be due to numerous reasons, such as:
- Technical indexing issues like missing robots.txt or XML sitemaps
- New websites with little authority
- Low-quality or poorly optimized content
- Stiff keyword competition or poor targeting
- Slow site speeds, a lack of mobile optimization, and other UX signals
Get the Best Results From Ranking Efforts With Ignite Visibility
With a better understanding of how search engines work, you can determine how to build discovery and relevance for search engines with high-quality, well-optimized content.
However, you may want some help, as SEO and GEO can be daunting. Ignite Visibility’s experts can work with you to:
- Create top-quality content
- Integrate natural keyword instances and technical SEO elements
- Measure engagement metrics and rankings
- Continually improve your website’s performance
Want to learn more about how we can help you achieve top rankings? Learn all about our SEO services here!