Weekly Roundup of Breaking Marketing News Brought To You Each Friday
Digital Marketing News 7/18/2026 to 7/24/2026
This week: Google announced major changes coming to Local Services Ads, AI-generated content continues to reshape social media, and businesses are being warned that AI tools may be giving customers incorrect information about their companies.
Here's what happened this week in digital marketing:
1. Google’s Local Services Ads to Move Into Google Ads Interface
Google announced this week that it will be merging Local Service Ads into the Google Ads Interface. The migration will start this August and take place through 2027.
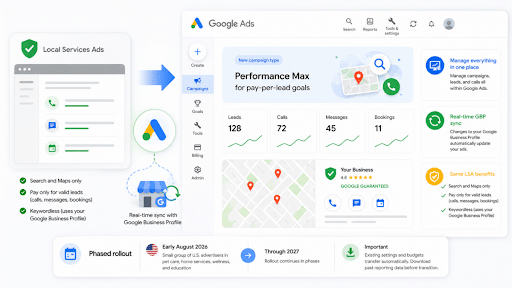
Local Service Ads will now have:
- A dedicated space inside the Google Ads platform where marketers can manage their budgets, adjust targeting settings, and respond to inquiries directly from the Google Ads dashboard
- Align Local Service Ads’ bidding and budget adjustment models with existing Google Ads models
- Greater control over local campaigns by connecting your Google Business Profile and your Google Ads profile for automatic syncing
- Less dependence on Better Business Bureau (BBB) callout
Some things will not change, including:
- Pay-per-lead model
- The focus on high-intent customer connections
- Ad placements within Performance Max campaigns
- Keywordless targeting
This rollout will start in August 2026 with select home and storefront service providers in the US. By late 2026, it will expand to more accounts, before finally wrapping up in 2027 with non-US accounts.
All account owners will receive an email notification 14 days in advance before the migration takes place, so keep an eye out for your email.
You can learn more about the process and the timeline here.
2. 41% of LinkedIn Posts Are AI-Generated: What This Says About the Future of Social Media & AI Content
A new study from Pangram revealed that 41% of all LinkedIn posts are AI-generated. This has sparked a question: will social media platforms survive the flood of AI-generated posts?
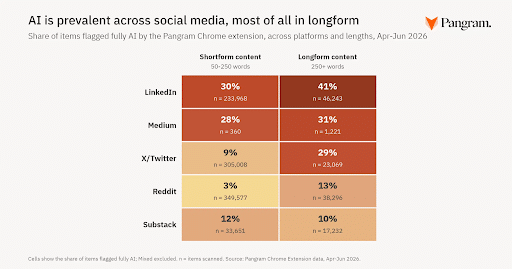
AI-generated content is everywhere, including on social media. The study found that LinkedIn leads the pack, with 30% of its short-form content and 41% of its long-form content is AI-generated. Other platforms being flooded with AI-generated content included:
- Medium: 28% and 31%
- X/Twitter: 9% and 29%
- Reddit: 3% and 13%
- Substack: 12% and 10%
It isn’t just the content, either. The study also found that almost 24% of LinkedIn comments are also AI-generated, whereas only 1.7% of Reddit comments are.
AI isn’t going anywhere, but it is interesting to see just how much content is not coming from an actual human. The biggest takeaway here for marketers is that, if you want to really stand out, have a human write, or at least heavily review, your content. Then you’re less likely to say whatever everyone is getting from the same AI models.
The whole point of social media is to connect people and encourage social connection. Will that continue to happen if everyone is just inserting the same AI-generated content on every platform?
3. Reddit Tells Marketers to Be More Authentic
Reddit has been becoming an even bigger player in the digital marketing game. According to the platform, the key is to be authentic.

At Cannes Lions, Reddit shared these tips to find success on their social platform:
- Act like a citizen, not a billboard
- Start with audience context, then build
- Use the comments as strategy, not just sentiment
- Design for participation, not extraction
- Measure business impact without flattening the community
The connection and community behind Reddit is what makes the site so popular. The last thing you want to do is treat it like every other marketing platform. Instead, you have to become an actual Reddit user, contribute to the community, and then promote yourself. Spending time building relationships and contributing to the community is what will make your brand stand out from other brands that treat the site like a transactional opportunity.
4. Pinterest Shares 5 Best Practices for Success on Their Discovery Platform
Pinterest recently shared five best practices that brands should follow to stay relevant on the platform.
The blog mentioned 5 tips, including:
- Updating product catalog signals and feeds by checking titles, product info, and coverage
- Setting up solid tracking and measurement signals
- Giving campaigns enough SKUs to learn
- Building momentum by establishing always-in campaigns
- Fixing what happens after the click
The most important practice is to make sure your product catalog is updated often. Per Pinterest, “Your product catalogue (or feed) is how Pinterest understands what you sell. It shapes who you reach, what they see and how often you enter the auction, so missing, vague or wrong fields can hold back even a strong campaign… titles featuring brand keywords have been associated with 28% higher ROAS, and pattern keywords with 22% higher ROAS.”
Dive deeper into these recommendations and learn exactly how to fix up your profile by reading through the complete guide: 5 Best Practices For Better Shopping Performance on Pinterest.
5. 64% of UK Retailers’ Addresses Are Incorrect in AI Models
A new study published in Search Engine Journal revealed that 64% of UK retailers’ information was incorrect in popular AI models.
The study also found that 93% of businesses had at least one important fact wrong. According to Searchable co-founder Chris Donnelly, that’s because “[f]or a smaller bricks-and-mortar retailer, if their online visibility mostly centers around its website and a Google Business listing, that’s a relatively thin trail of information for AI systems to learn from and to represent in their answers.”
What You Can Do: First things first: check what information AI models are returning for your business. If it’s incorrect, you have to audit its sources. Review every single place you’ve listed your business information. Once it’s all cohesive, start looking at sources you don’t own, like old directories, review pages, or pages for similarly named businesses. Do your best to get that information corrected.
Remember: AI models are only as good as the information they are fed. Make sure your business’s information is accurate, cohesive, and up to date on all platforms to reduce the chances of AI searchers returning incorrect information.
6. Bot-Checking Pages Could Impact Your Ranking
You know those pages some sites put up that ask visitors to confirm that they aren’t a bot? Those pages could be negatively affecting your ranking.
In a new episode of Search Off the Record, Google’s John Mueller discussed this issue. He shared that sometimes, Google indexes these pages as genuine page content, which then sets off duplicate content detectors.
If this happens, it’ll mark one site’s page as canonical and the rest of the sites as duplicate content. It becomes difficult for website developers to track because it requires examining the page Google selected and then working backward to determine the cause.
If you suspect this could be causing issues with your site, Google suggests contacting whoever manages your site’s security service, CDN, or web hosting. Once the issue is resolved, you can then ask Google to re-crawl your site via Search Console's Validate Fix.
7. Google Ads’ New Beta Introduces “Missed Growth Opportunity” KPI
Google Ads has introduced a new beta recommendation aimed at helping marketers estimate the impact of increasing budgets or raising bids.
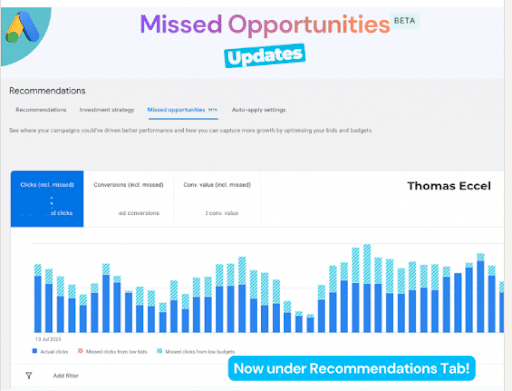
This new feature highlights:
- Estimated clicks left on the table.
- Missed conversions.
- Unrealized conversion value.
- Whether those missed opportunities were primarily caused by budget limitations or low bids.
The goal is to help advertisers refine their strategies and find more opportunities for success with Google Ads. You can see the new update now under the Recommendations tab.
8. Google Launches Video Campaign Groups for YouTube Ads
Google Ads has introduced video campaign groups for YouTube reach and frequency campaigns, giving advertisers a new way to manage multiple campaigns under a shared reach or frequency goal.
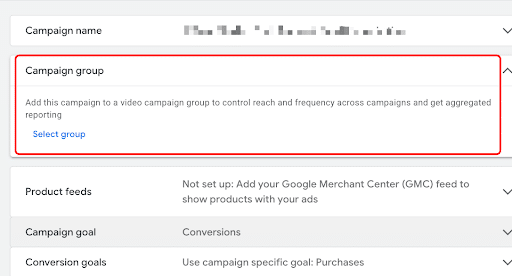
The feature allows marketers to group video campaigns together while maintaining individual budgets, creative assets, and campaign settings. Advertisers will also gain access to unified reporting, making it easier to track metrics like unique reach, average weekly impressions, and overall campaign performance across the entire group.
According to Google, better frequency management can have a meaningful impact on performance. A recent study found that an optimal frequency of 2.7 impressions per week led to a 19% increase in ROI.
Why We Care: This makes it easier to maximize reach while avoiding ad fatigue. For brands running multiple YouTube campaigns, it could improve efficiency and simplify reporting.
9. Hacking Risk: WordPress Says Update to 7.0.2 Immediately
Hackers are targeting WordPress websites, with some estimates saying tens of millions of websites could be affected.
In response to this hacking threat, WordPress has released WordPress 7.0.2. This security update addresses two critical issues:
- A facilitated SQL injection issue reported as a team by TF1T, dtro, and haongo
- A REST API batch-route confusion and SQL injection issue leading to Remote Code Execution reported by Adam Kues at Assetnote / Searchlight Cyber
Since this threat is so serious and could affect so many websites, WordPress is urging users to update their sites immediately.
10. Google Releases New AI Models Aimed to Make Coding & Cybersecurity Issues Easier to Solve
Google released three new AI models this week.
The new additions to the Google Gemini family include:
- Gemini 3.6 Flash
- Gemini 3.5 Flash-Lite
- Gemini 3.5 Flash Cyber
The 3.6 Flash model is said to be the “workhorse model,” and “promises improved capabilities in coding, knowledge work, and multimodal performance while reducing token usage by up to 17%.”
The 3.5 Flash-Lite is the most cost-effective tool, and the 3.5 Flash Cyber is fine-tuned for finding and fixing cybersecurity vulnerabilities. The last model will only be available to select users, including governments and trusted partners.
These three updates introduce cheaper, faster AI models optimized for coding and cybersecurity. However, it didn’t include the long-anticipated update to Gemini Pro, which has been updated since February.
11. Google Adds Top Stories Directly Into AI Overviews
Google has officially rolled out Top Stories and news updates within AI Overviews for mobile users in the United States, bringing more timely content directly into AI-powered search results.
The feature is designed to surface fresh coverage on developing topics, making news articles more visible within AI-generated answers. For some searches, users will now see a prominent news carousel featuring recent stories and, in some cases, content from their preferred news sources.
The update stems from Google's broader effort to incorporate fresher perspectives and more prominent links into AI-powered search experiences, helping users discover up-to-date information without leaving the search journey.
Why We Care: This is a positive step for publishers and brands. As AI search evolves, Google is creating more opportunities for timely, high-quality content to earn visibility and clicks directly from AI Overviews.
Weekly Homework
- Update your WordPress site to 7.0.2 to take advantage of necessary security updates.
- Download your Google Local Service Ads data, as past information will not be migrated to the new system.
- Align your Pinterest profile with the platform’s 5 best practice suggestions.
- Watch the Reddit Cannes sessions for inspiration on building a community around your brand without sounding like a transactional billboard.
- Type your business into AI to see what each model returns. If the information is incorrect, audit the AI tool’s sources and make sure everything is up-to-date to eliminate the possibility of AI searchers receiving incorrect information about your business.
Digital Marketing News 7/11/2026 to 7/17/2026
This week: Google turns search into an action engine, EU forces Google to share search data, Google cites its own properties more often, and AI Mode ads separate paid from organic visibility.
Here's what happened this week in digital marketing:
1. Google Is Adding Connected-App Integrations To AI Mode
Google is rolling out connected app integrations within AI Mode, allowing U.S. users to move from getting answers to taking action without leaving the search experience.
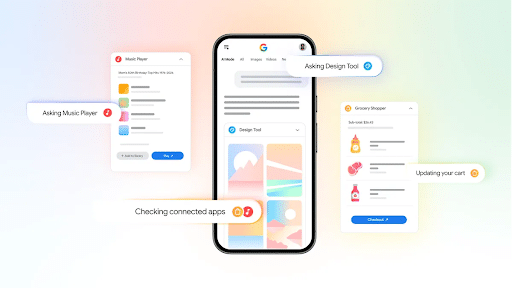
Users can securely connect supported apps such as Instacart, Canva, and YouTube Music directly to AI Mode. For example, someone planning a barbecue can generate a shopping list and send ingredients straight to an Instacart cart. Users can also browse Canva templates for creative projects or create and save playlists to YouTube Music from within AI Mode.
Google says this is just the beginning, with additional app integrations planned in the future as it expands AI Mode's capabilities beyond answering questions and into completing tasks.
Why We Care: Search is evolving from a discovery engine into an action engine. As Google creates more ways for users to complete purchases, create content, and accomplish tasks directly from AI-powered search experiences, brands may see fewer traditional website visits while new opportunities emerge inside connected ecosystems. Marketers should pay close attention to how their products, services, and content appear in AI Mode as Google's role in the customer journey continues to expand.
2. AI Mode Ads Are Growing Fast, But They Won’t Boost Your Rankings
A new study from SE Ranking found that Google’s AI Mode displayed text ads on nearly 30% of commercial searches, highlighting how quickly advertising is becoming part of the AI-powered search experience.
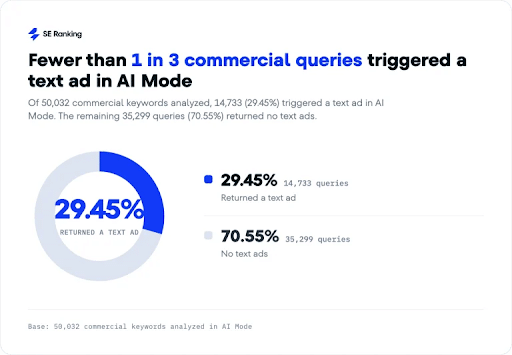
The research showed that higher-cost keywords were far more likely to trigger ads. For keywords with a CPC above $10, more than half of AI Mode results included advertising. The study also found that most ad placements featured multiple advertisers, signaling increased competition for visibility within AI-generated responses.
Perhaps the most interesting finding: advertisers rarely appeared as cited sources in the same AI Mode response. In most cases, buying an ad did not increase the likelihood of being referenced by Google's AI-generated answer, nor did it correlate strongly with organic rankings for the same keyword.
Why We Care: As AI search evolves, paid visibility and organic visibility are becoming increasingly separate opportunities. Running ads in AI Mode may help you capture attention for high-intent searches, but it won't automatically improve your organic presence or increase your chances of being cited by Google's AI. Marketers should continue investing in both paid media and content authority strategies, treating them as complementary channels rather than expecting one to influence the other.
3. Google Is Becoming Its Own Top Citation Source in AI Search
Google’s AI Mode is increasingly citing Google’s own properties, with citations to google.com growing 8.4 times in just a few months, according to new data from Profound.
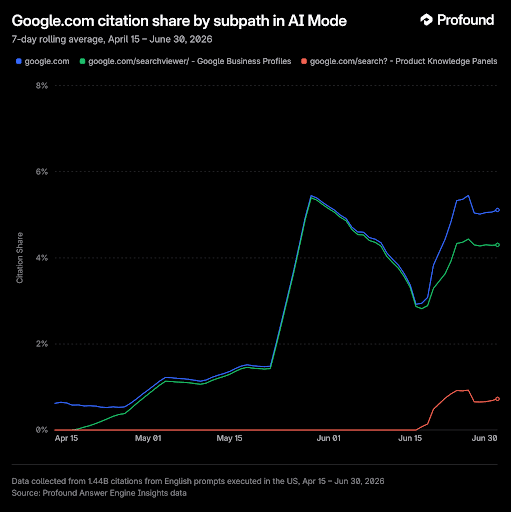
Much of that growth is coming from Google Business Profiles and Product Knowledge Panels, which are now appearing directly within AI-generated answers. For local searches, users may see a business’s hours, reviews, photos, and location before ever reaching the company’s website. For product-related searches, Google is increasingly surfacing product information and specifications through its own knowledge panels rather than sending users directly to ecommerce or brand sites.
The trend is especially noticeable in industries driven by local intent, including hospitality, restaurants, healthcare, real estate, and home services.
Why We Care: Your Google Business Profile is no longer just a local SEO asset, it may be your most important digital storefront. As AI Mode continues to surface Google-hosted business and product information directly in search results, marketers and business owners should treat profile optimization as a top priority. Accurate business information, high-quality photos, strong reviews, and complete listings could influence customer decisions before they ever visit your website.
4. EU Orders Google to Share Search Data With Rival Search and AI Platforms
The European Commission has ordered Google to share anonymized search data with eligible third-party search providers under the Digital Markets Act (DMA), with implementation set to begin in January 2027.
The ruling requires Google to provide qualifying competitors with the same search data it uses to improve its own search services, while maintaining strict privacy protections. Notably, the Commission confirmed that AI-powered search tools and chatbots with search functionality will also be eligible to access the shared data, not just traditional search engines.
The Commission also announced future changes to Android that will give competing AI assistants greater access to device features currently available to Google's own AI services. Those updates are expected to begin rolling out in 2027.
Why We Care: This decision could accelerate competition in both search and AI. By giving rival search engines and AI-powered search tools access to valuable search data, the EU is attempting to level the playing field and reduce Google's advantage. While changing user behavior remains a major challenge for competitors, marketers should expect continued growth in alternative search platforms and AI assistants, making it increasingly important to diversify visibility strategies beyond Google alone.
5. Google Explains How to Improve AI Visibility
In a recent edition of the Ads Decoded newsletter, Google Ads Liaison Ginny Marvin explained what businesses need to do to improve their ads' visibility in AI chat.

When asked how to improve AI visibility, Marvin noted that nothing has changed and to “[k]eep in mind that the relevance bar is higher in AI Search, and ads are matched to Google’s understanding of the user intent based on both the user query and the content in the response.”
She also highlighted control settings in AI Max that could help, including:
- Brand controls
- Location-of-interest settings
- URL inclusions and exclusions
Marvin also discussed the newest KPI, Qualified Future Conversions (QFC). She shared that this is a predictive metric that estimates conversions occurring up to 180 days after an ad interaction. Since some products have a longer sales cycle, this metric can help advertisers better understand how their ads affect later conversions.
6. Google Image Search Gets an Upgrade
Google announced this week that its Image Search is getting a makeover. AI Overviews will also be getting an image upgrade.
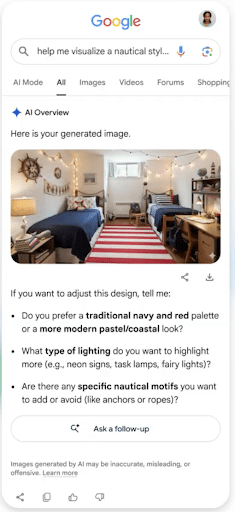
The Google Images homepage will now look more like a personalized, real-time gallery than a simple search page. There will also be options to create your own galleries in Google Images, similar to Pinterest. Consumers can save their favorite images to different galleries for later reference.
Google users will also be able to generate images within AI Overviews, like in the image above. Using Google’s Nano Banana AI Model, users can transform a text prompt into a high-quality image, bringing their imaginations to life. They can also compare two generated images and more.
Why We Care: AI Overviews were already taking clicks away from text links. This new visual upgrade could start to do the same for image-led clicks. While there is no firm date for when this upgrade will roll out to every Google user, it’s important to keep an eye out, especially if you tend to generate a lot of traffic from your brand’s custom images.
7. Instagram to Start Charging for AI Tools
It’s no secret that Meta has been pouring billions of dollars into developing AI tools. Now, Instagram is going to charge users to use it.
In his weekly Q&A, Instagram Chief Adam Mosseri said, “Basically, these AI models are very expensive to run, and so we try to just offer them for free, but we have a cap on how many times you can use them per day. Eventually, you’re going to be able to subscribe to be able to get access to more, we’re working on that right now.”
This comes on the heels of last month’s Instagram Plus announcement. In that announcement, it was revealed that users could pay for Instagram Plus to access features such as Story Spotlights, Super Hearts, Multiple Story Audiences, Story Extend, Story Preview, Story Rewatch Insights, Search Viewer List, Custom App Icons, and more.
While no timeline was given, it’ll be interesting to see when this rolls out and how much effect it has on users’ use of AI tools on the platform.
8. Meta Adds New KPIs for Business Chatbots
Interested in learning more about how well your business chatbot is performing on Meta? This new rollout should help.
Meta will now keep track of certain chatbot metrics within users’ Meta Business Suites. These KPIs include:
- AI Conversions
- Contact with intent to buy
- Containment rate
The goal is to help businesses and brands better track engagement and performance data directly tied to their chatbot usage.
9. Consumers Prefer Third-Party Gen AI Tools Over Chatbots
Speaking of chatbots, a new study from Marketing Dive revealed that most consumers prefer third-party gen AI tools over chatbots for their customer service needs.
The study found that ⅔ of consumers are already using gen AI tools, so they trust them more. If consumers are already using a brand’s chatbot, they are likely to continue to use it. But if they haven’t used it yet, chatbots don’t tend to drive much engagement.
It also noted that many brands’ generative AI customer service investments aren’t aligned with customer behavior, which explains the disappointing results.
The bottom line? If you want your chatbot to be successful, it has to actually be helpful. Make sure it is interactive and resonates with your audiences’ needs before investing any more money in development.
10. Apple Bans Home Services from Map Ads
Apple recently published a new rulebook for its upcoming Map Ads launch, and it's quite different from Google’s.
Its most notable announcement is that the broad category of “home services” has been banned. This includes businesses including plumbers, electricians, HVAC technicians, roofing services, and general contractors.
The new rulebook shares that Apple wants to focus more on brick-and-mortar businesses that people can actually visit. They will also limit each search to one singular ad. The goal is for Apple’s ads to feel more organic than traditional PPC ads.
You can read more about Apple’s Advertising Services policy here.
11. LinkedIn Share Tips on How to Find Success on Its Platform
LinkedIn wants you to be successful on its app, so this week it shared some new advice on how to maximize your content’s performance.

One thing that the platform made very clear is that “[c]onsistency is one of the biggest drivers of reach on LinkedIn. Posting regularly signals to the algorithm that you’re an active, valuable contributor.”
Basically, you can’t post and pray here. You have to be an active participant in what you post to see the highest ROI from your strategy.
The biggest takeaway: Keep your posts consistent and within 200-300 words. Short-form content performs well here. Take longer-form content and turn it into LinkedIn articles to help diversify your platform.
12. X Changes Its Algorithm
X, formerly Twitter, has famously been fighting a losing battle for a few years now. It’s lost followers and advertisers, but the company isn’t giving up on reclaiming its former crown as a social media heavyweight. This week, the company announced a shift in its algorithm to make the platform more friendly.
According to TechCrunch, this tweak should “make X feel a little bit more like a community rather than a torrent of disparate voices shouting into the digital abyss.”
Creating clusters around interests could prove to be beneficial for marketers and brands looking to grow on the platform. If one person interacts with your post, it could automatically push it out into the feeds of people with similar interests or views.
13. New Merchant Listing Structured Data Improves SEO
Google recently made a major change to its Merchant Listing Structured Data, and it’s improving brands’ SEO success.
There were three new properties added, including:
- Category: to create custom categories
- Category Code: to tie items directly to another category
- Sale Duration: specifying exactly how long a discount will run
These new properties give Google more information to go on when indexing how merchants describe themselves. The more information Google has, the more likely your brand is to be indexed correctly. It’s also more likely that Google will display the correct product information in users’ search results.
You can learn more about all the properties, including the major new changes, here.
14. New AI Transparency Comes to Google Ads
Google Ads introduced a new disclosure requirement this week.
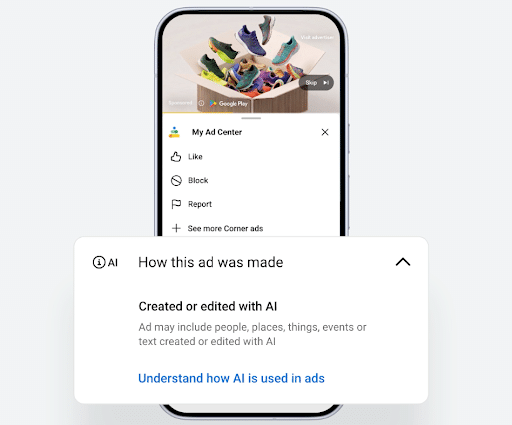
Advertisers will now be required to note if their ad was created or edited with AI tools. This could include anything in the text or graphics of the ad.
This change will be required for ads across Search, YouTube, and Discover.
According to Google, they “want to make managing AI disclosures as simple as possible for advertisers. So when they use Google’s generative AI advertising tools to create ads, we’ll automatically add a disclosure to each ad’s My Ad Center panel. And when they create ads elsewhere, we’re introducing a control so they can easily indicate if they used generative AI. Based on local requirements, a label may also appear directly on the ad, either automatically or when an advertiser uses this control.”
You can find more information about this new requirement within your Google Ads Center.
Weekly Homework
- If you’re active on Google’s Merchant Center, check out the new structured data options to improve your products’ SEO.
- If you’re using AI in your Google Ads, log in to your dashboard and ensure all your ads are clearly noted.
- Using a chatbot on Meta? Explore the new KPIs in your Meta Business Suite to monitor its performance.
- Play around with Google Image Search and AI Overviews’ new image upgrades to see how it could affect your brand’s images.
- Review LinkedIn’s suggestions for improving content on its platform and tweak your LinkedIn strategy accordingly.
- Now is a great time to get into Apple Maps Ads if you have a brick-and-mortar business. Review the newly released guidebook to make sure you optimize your ads for success.
Digital Marketing News 7/3/2026 to 7/10/2026
This week: Search Console Tracks Social Posts, ChatGPT Drives AI Traffic, Google Labels AI-Created Ads, and Voice Search Comes to ChatGPT.
Here's what happened this week in digital marketing:
1. Google Search Console Publishes Reports for Social Posts
You asked and Google answered! This week, Google announced a new addition to Search Console – Social media tracking.
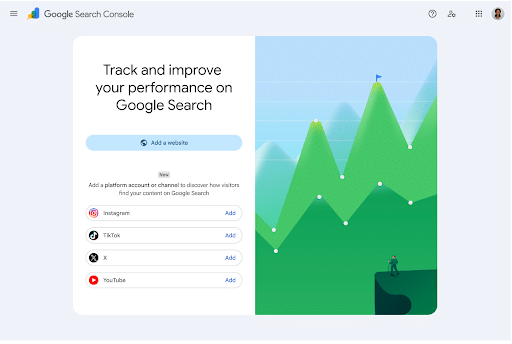
This new addition allows creators and publishers to see how their social media posts are performing directly from their Search and Discover dashboards.
Currently, this is available for four platforms:
- TikTok
- X
- YouTube
More platforms are expected to be added over the coming weeks. You can access these reports within your Google Search Console.
2. X Adds Native Video Editor to Its Platform
X introduced a new tool within its iOS app this week: Video Editor and Recorder.
The goal is for users to ditch third-party tools and create video content directly within the X platform. Instead of posting stolen material from other apps, X wants native content to help drive more users and advertisers to the app.
Only time will tell if this helps create the thriving creator ecosystem that X has been chasing.
3. 34% of Gen Z Are Social Media Lurkers
Meta started testing up-front post view count on Facebook this week.
With studies showing that 34% of Gen Z describe themselves as “lurkers,” understanding who is actually seeing your Facebook posts will give you valuable insights into your social media ROI. With post view counts already viewable on Instagram and Threads, Meta hopes this will have a positive impact on Facebook marketing as well.
4. 6 in 10 Americans Support Social Media Ban for Minors
A new study from Pew Research revealed that most adult Americans support restrictions on social media for those under 16.
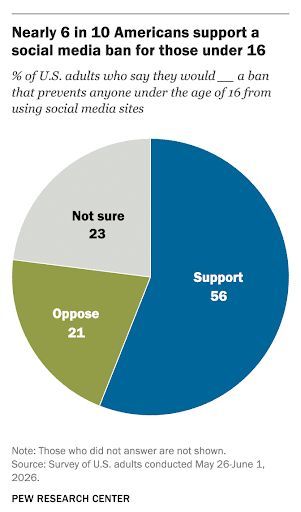
The support was spread evenly across demographics, with the following saying that they support a ban:
- Ages 18-29: 52%
- Ages 30-49: 63%
- Ages 50-64: 57%
- Ages 65+: 49%
- Parents of minor children: 65%
- Individuals with no minor children: 52%
- Leaning Republican: 59%
- Leaning Democrat: 54%
While bans are already taking shape in the U.K., Turkey, and Canada, they're slow to spread in the United States, where only California and Florida have begun implementing restrictions.
Either way, it’s smart for marketers to keep an eye on any upcoming bans and develop ideas to adjust campaigns aimed at kids or teenagers.
5. Google Adds AI Labels to Ads: A New Era of Advertising Transparency
Google is introducing a new "How This Ad Was Made" feature that will show users whether an ad was created or modified using AI. The disclosure will be available through My Ad Center and will roll out globally across Search, YouTube, and Discover.
Users can access the information by clicking the three-dot menu or info icon on an ad. If an advertiser uses Google's generative AI tools to create ad assets, Google will automatically include the disclosure. Advertisers using third-party AI tools may be able to control whether AI usage is disclosed, depending on local regulations and platform requirements.
The update is part of Google's broader push for transparency as AI-generated creative becomes increasingly common. While the new disclosures provide more visibility into how ads are produced, Google emphasized that its existing advertising policies still apply regardless of whether AI was involved in creating the content.
Why We Care: As consumers become more aware of AI-generated content, transparency may become a competitive advantage rather than just a compliance requirement.
6. Want to Improve AI Visibility? Improve Your Messaging
A new study from Semrush reveals that strong messaging is one of the best ways to improve your brand’s visibility to AI bots.
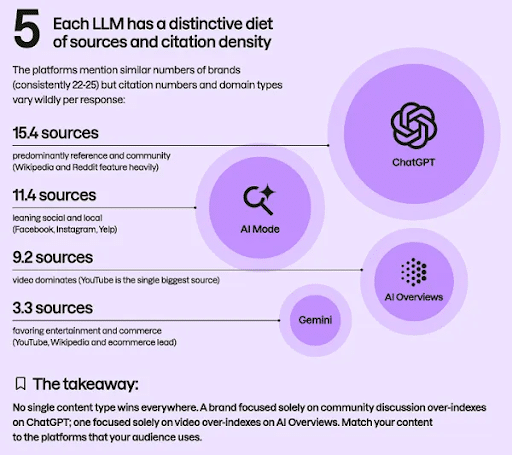
The study revealed that LLM tools typically pull from multiple sources, including Wikipedia, Reddit, social media, local review sites, and video content. The overarching takeaway, though, is that no matter where AI is pulling data from, it's important that your messaging is clear and consistent across all platforms.
Other takeaways included:
- AI can’t replicate proprietary assets
- Specialists are cited more than generalists, especially in fields like finance, automotive, and health
- Brands with inconsistent messaging and third-party source networks struggle to gain citations
- Tangible products or services rise to the top of the citations
7. ChatGPT Generates 92% of AI Referral Traffic
A new study from Previsible revealed that 92.4% of AI traffic comes from ChatGPT.
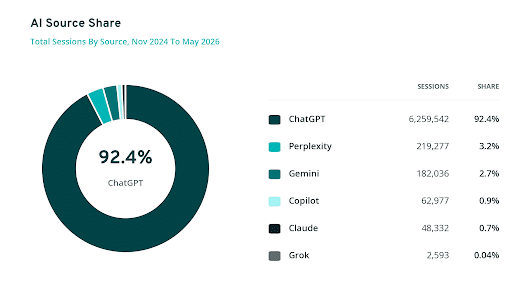
In addition to the majority of the traffic coming from ChatGPT, it looked at which industries are benefiting the most from AI traffic. The winner? SMB. Other top industries included Insurance, Finance, Legal, Education, and Ecommerce.
It also examined the types of pages it typically returns. While it varied, the most popular pages included:
- Internal search pages
- News pages
- Product pages
- Course pages
- Blog pages
8. OpenAI GPT-Live Introduces Voice Search
With OpenAI rolling out GPT-Live this week, Internet searchers can now search by voice.
GPT-Live rolled out this week, introducing a new generation of voice models to ChatGPT. Using this tool, searchers can use voice search for heavier reasoning and deeper web searches.
OpenAI says that this new experience also includes:
- More natural conversations
- Smarter answers
- Better listening on behalf of ChatGPT
- Visual answers
- Expanded safety testing
- And more
You can learn more about this new tool and how to use it here.
9. 38% of US Shoppers Don’t Like AI Bots and Won’t Use Them
A new study revealed that 38% of US digital shoppers aren’t interested in using AI chatbots for help.
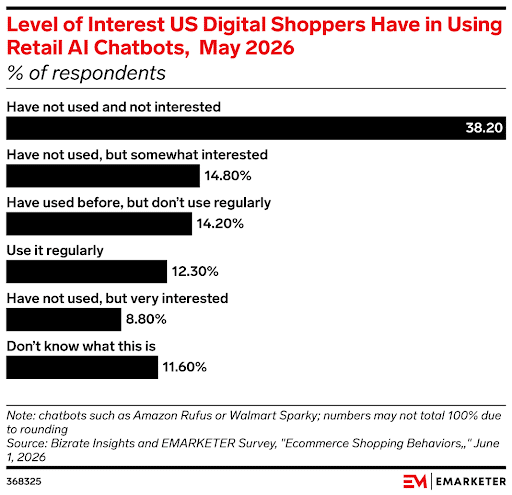
If you’ve been considering adding a chatbot to your ecommerce brand, don’t let this chart scare you off. In the same breath, retailer Macy’s reported that shoppers who use its AskMacy’s chatbot spend 4.75 times more than those who don’t.
While 38% are not interested in using them, those who are more than make up for it.
10. US Consumers Are Increasingly Spending More
A new report from eMarketer reveals that US consumers are starting to spend more than before.
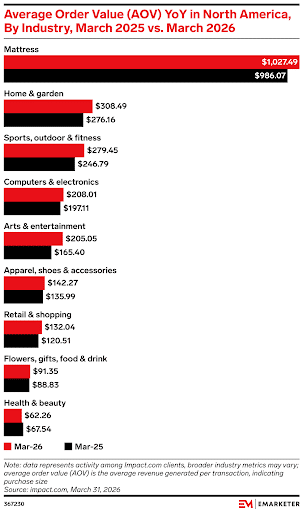
When looking at spending data from this year compared to last year, spending is up in most industries, including:
- Mattresses
- Home & Garden
- Sports, Outdoors, & Fitness
- Computers & electronics
- Arts & Entertainment
- And more
Health and beauty were the only industries to see a decline, falling 7.8% YoY.
One of the biggest takeaways is that shoppers aren’t necessarily spending less. They’re just consolidating their trips and spending more on experiences over essentials.
Why We Care: This is the perfect time to add upsells or additional items to your offerings.
11. Google Investigating Issues with Google Business Profile Reviews
Google reported this week that some businesses are experiencing issues with their Google Business Profile reviews going missing.
The digital giant says its engineers are working on the problem. “When our systems detect suspicious reviews, we take a range of actions, including removing reviews and temporarily pausing reviews on the profile to prevent further abuse. We are investigating the issue and will restore any reviews that were incorrectly removed.”
If you noticed any of your reviews went missing or that your ability to collect reviews disappeared, don’t worry. It’s just a glitch, and Google is working on resolving it.
Weekly Homework
- Log into your Google Search Console and check out the new social media tracking tools.
- With so many American adults supporting a social media ban for minors, it might be time to re-evaluate the way your marketing will reach kids and teens.
- Strong messaging is essential for AI visibility. Take some time this week to make sure your messaging is clear and cohesive across all platforms.
- Check your Google Business Profile to see if you lost any reviews recently.
- Check out the new video editor inside X to see if it could inspire you to post more video content on the platform.
Digital Marketing News 6/27/2026 to 7/2/2026
This week: ChatGPT Rewrites Citation Sources, AI Summaries Enter Search Ads, Meta Automates Content Moderation, and TikTok's $1.3B Drama Boom.
Here's what happened this week in digital marketing:

1. Only 25.6% of AI Citations Remain the Same Between ChatGPT Modes
A new study by Semrush and Kevin Indig revealed that ChatGPT switches which websites it cites depending on the searcher's mode.
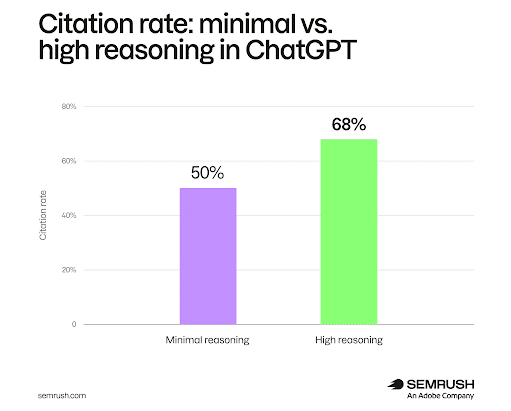
In reviewing a number of prompts and buyer journeys, the study found that, when users switched from Instant-style search to Thinking-style searches:
- Citation rates rose from 50% to 68%
- Reddit’s citation share dropped from 15% to 7%
- User-generated content and review sites went from 14.3% to 6%
- Government and academic sources rose from 1.9% to 8.8%.
- Official documentation and support pages grew from 12.4% to 17.5%.
Only 25.6% of the cited domains overlapped between Instant-style search and Thinking-style searches.
To learn more about which industries were the most affected, check out the whole Semrush study.
2. Ads for Electronics Convert Higher Than Any Other Industry
A recent eMarketer study found that electronics ads converted at a higher rate than any other industry in Q4 2025.
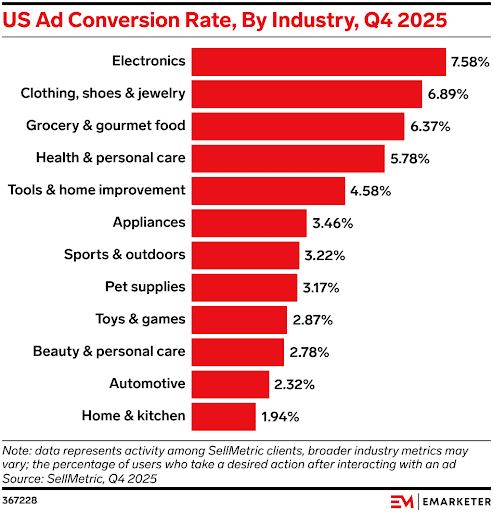
The report shared that popular industries had the following conversion rates:
- Electronics: 7.58%
- Clothing, shoes, and jewelry: 6.89%
- Grocery and gourmet food: 6.37%
- Health and personal care: 5.78%
- Tools and home improvement: 4.58%
- Appliances: 3.46%
- Sports and outdoors: 3.22%
- Pet supplies: 3.17%
- Toys and games: 2.87%
- Beauty and personal care: 2.78%
- Automotive: 2.32%
- Home and kitchen: 1.94%
The report also revealed that Meta converted shoppers at a higher rate than TikTok, coming in with conversion rates of 6.8% and 1.06%, respectively.
Why We Care: Knowing how your conversion rate compares to other industry leaders can help you better understand your ad success.
3. Search Ads: Google Tests AI-Generated Summaries
Google is toying with the idea of adding AI-generated summaries to your Search Ads.
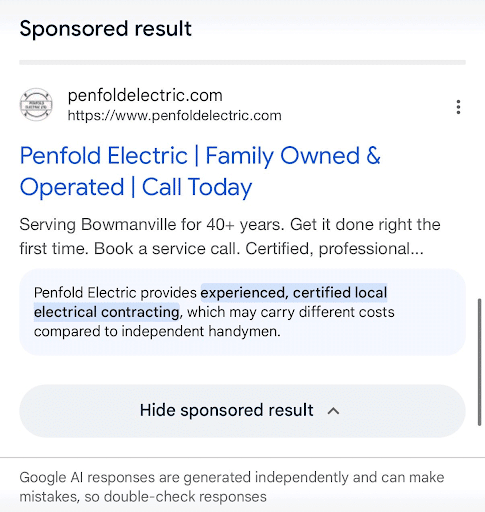
Some advertisers reported seeing AI-generated summaries displayed directly behind their Google Ads in Search results.
While this is still in the testing phase, it’s already causing some outrage within the digital marketing community. It’s also a sign that generative AI could soon play a large role in how paid search ads are run and displayed.
4. Google Shares: Meta Descriptions Aren’t Required, But Still Valuable
Are meta descriptions optional? Maybe, but Google’s John Mueller says they’re still valuable.
A recent post on Reddit has been circulating in which an SEO expert said that meta descriptions are pointless. Google’s Mueller responded to clear the air, saying, “Yes, but also, there’s no penalty to writing your own, and sometimes it helps you to figure out a clear focus for a page. Overall, I think it’s still worthwhile to do so for individual pages that you care about, but it’s definitely not a requirement.”
This response aligns with Google’s own guidelines for meta descriptions, which state that “A meta description tag generally informs and interests users with a short, relevant summary of what a particular page is about. They are like a pitch that convince the user that the page is exactly what they're looking for. There's no limit on how long a meta description can be, but the snippet is truncated in Google Search results as needed.”
Why We Care: This just shows that not everyone on the internet is an expert, even if they say they are. Always turn to true experts for reliable information and advice.
5. New Updates Come to Demand Gen Ads
We shared last week that Google has extended the timeline to change your ads to Demand Gen. Now, Google has made some important updates to help make the ads even better.

New capabilities came to Demand Gen in the June Drop, including:
- Upgraded video enhancements with more video resizing options
- Automated recommendations from Gemini AI to optimize your content for YouTube
- Web to App acquisition measurements to help acquire new app users via app installs and give you a more comprehensive view of your Demand Gen performance
You can explore all of these new capabilities within your Google Ads dashboard.
6. Pinterest Expands International Insights
If you’re using Pinterest to expand into new international markets, you’re going to love this recent insights update.
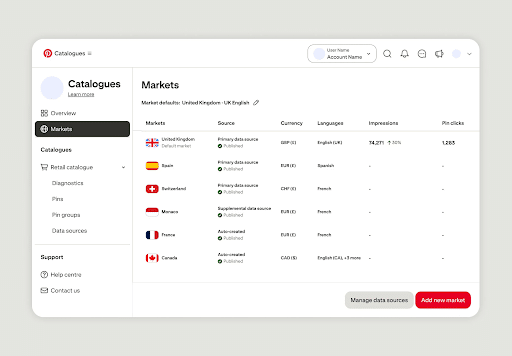
With Pinterest’s new AI-powered tools, global retailers and advertisers can increase their reach. Thanks to new multi-country shopping campaigns, advertisers can now:
- Run a single shopping campaign or ad group to reach several markets at once
- Group markets with similar pricing and conversion behavior
- Use Pinterest Performance+ to handle bidding, budgets, and delivery
For advertisers launching multi-country campaigns, these tools can help provide more learning opportunities and reduce operational drag.
The expanded tools also include a single global insights dashboard where marketers can see what is running, which markets are engaging, and more.
Currently, the new market tools are available only to a select group of marketers, but Pinterest says they will be accessible to all ad partners soon.
7. TikTok Microdramas Generate $1.3 Billion in 2025
Last year, TikTok launched a series of microdramas. That series ended up generating $1.3 billion. Now, TikTok is expanding these series and opening them up to brands and advertisers.
Currently available in the United States, Canada, Australia, New Zealand, Indonesia, Thailand, South Korea, Japan, Brazil, and Mexico, these new minidramas can generate revenue for brands through built-in monetization opportunities.
TikTok Mini Dramas can help brands in three ways:
- Expand reach, drive engagement, and maximize returns through episodic content
- Unlock incremental revenue through in-app engagement and purchases
- Drive ad performance beyond ROAS by converting intent into value and driving immediate results
If you’re interested in branching out into TikTok miniseries, click here or discuss the opportunity with your TikTok Ads representative.
8. Meta Launches Integrated Booking for Lead Ads
Meta announced this week that you can now use embedded appointment booking for lead ads.
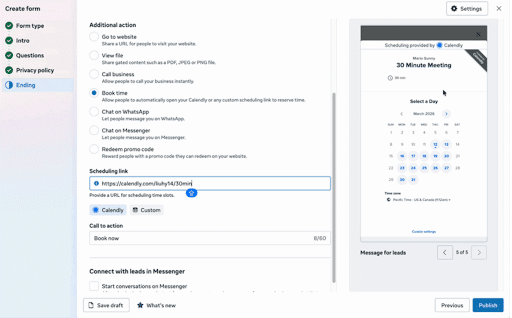
Embedded Appointment Booking makes it possible for:
- Your ad leads to book appointments directly through an Instant Form
- Auto-prefill contact information to reduce lead drop-off
- Advertisers to set it up simply with no coding required
The goal is to convert more Meta Ads leads by making it easier than ever for them to book a service with your business.
Embedded Appointment Booking is supported through integrations with Calendly and HighLevel, with a HubSpot rollout coming in August. Additional scheduling partners will be added over time.
9. Meta to Replace 90% of Content Review Staff with AI
Meta announced this week that it will replace up to 90% of its content review staff with AI by the end of this year.
Even though the company has reportedly invested hundreds of billions of dollars in AI development, this announcement comes on the heels of a recent Instagram hack in which hackers accessed accounts by impersonating an AI support assistant.
Regardless, Meta plans to move forward with this labor cut.
Why We Care: Getting a hold of a human at Meta often proves challenging, even for well-versed marketers. Eliminating up to 90% of content review staff could lead to an even more frustrating road to resolution when ad accounts are wrongly flagged or removed.
10. YouTube Turns to AI to Monitor Comment Filtering
Meta isn’t the only social media site that is turning to AI to monitor content. YouTube announced this week that it, too, will use AI-powered tools to help channel managers with video comments.
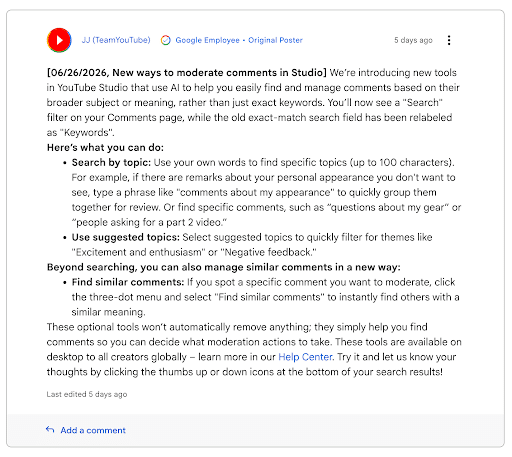
In the announcement, YouTube explained, “You’ll now see a ‘Search’ filter on your Comments page, while the old exact-match search field has been relabeled as ‘Keywords.’”
Access these new tools within the YouTube Studio to see how they can help you moderate your brand’s comments.
Weekly Homework:
- Review the Semrush study to see how you can improve your brand’s chances of landing in an AI citation.
- Compare your ad conversion rates with industry averages using the chart from eMarketer.
- Consider updating your meta descriptions to increase your chance of being found by Google and Google Snippets.
- Explore the updates to Google Demand Gen, Pinterest Global Marketing, and YouTube AI comment monitoring tools.
- Check out Meta’s Embedded Appointment Booking to see if it makes sense for you to add it to your Meta Ads.
- Explore whether TikTok Microdramas could benefit your brand.
Digital Marketing News 6/20/2026 to 6/26/2026
This week: ChatGPT recommendations drive traffic, Reddit becomes AI shopping validator, Instagram expands to smart TVs, and Google launches AI ad manager assistant.
Here's what happened this week in digital marketing:
1. Websites Recommended by ChatGPT 2.5x More Likely to Receive Traffic
A new Similarweb report released this week found that websites recommended by ChatGPT are 2.5x more likely to receive a visit within 7 days.
The study also found that AI tools are used for:
- Discovering initial ideas: 35%
- Researching and comparing options: 30%
- Finding where to buy/best price: 24.3%
This is compared to traditional search engines that are used for:
- Discovery initial ideas: 13.6%
- Researching and comparing options: 20%
- Finding where to buy/best price: 22.1%
The research study also noted that “AI visibility is not a soft brand metric. It is a traffic driver with a measurable impact on site visits, it just operates on a delayed timeline that standard referral tracking cannot capture. Brands that dismiss AI as a channel because referral numbers look low are measuring the wrong thing. The visit happens. The attribution model just isn't built to see it.”
Discover more interesting information and data about AI visibility by reading the SimilarWeb report here.
2. Instagram Expands to Smart TVs
Instagram announced Instagram for TV last December. They announced this week that the new access point is growing – thanks to a partnership with Samsung TVs.
Users can now:
- Organize channels around their interests
- Cast Reels from their phones to their TVs
- Watch Stories on their TVs
- Create and watch horizontal videos designed for the TV screen
This new format will also allow for longer-form creator content, episodic series, and live creator experiences on TV.
Instagram for TV is now available on Samsung Smart TVs (2020 models and newer), as well as Amazon Fire TV and Google TV.
3. 50% of US Shoppers Verify AI Recommendations on Reddit
Reddit seems to be growing by the minute. This week, the forum site announced more integrated ad options.

The new creative features include:
- Free-form ad generator to create Reddit-unique ads inspired by users’ long-form posts
- Tailored creative assets for Max Campaigns
- Redditor Highlights (GA) to embed real Reddit conversations into ads
- Shopping Listing Ads to match products from participating brands to real conversations
In the announcement, Reddit also released some interesting data, including:
- 50% of US shoppers verify AI recommendations on Reddit
- 50% of Reddit users have discovered new products on the platform
- Reddit is the #1 social platform for helping people make purchase decisions
Learn all about the new Reddit ad options and how users are using the platform to make purchase decisions here.
4. June 2026 Spam Update is Here
On Wednesday, Google released its June 2026 spam update.
The update applies to all countries and languages and should take a few days to complete.
It could affect your site’s rankings. But, since this is a spam-only update, if you aren’t using any manipulative techniques, you should be okay.
5. LinkedIn Adds Collaborative Posts
LinkedIn announced this week that it will make collaborating in the app easier.
The new Collaborative Posts feature will allow users to share posts with other users listed as collaborators. Much like the collaborators tool on Instagram, it will then push the content to each collaborator's feed – expanding reach and impressions for all creators.
This new tool is just one in the long line of recent improvements designed to help creators monetize the app and create even more content. The collaborative posts feature also means that brands can engage more within member networks, which generally have more visibility than company pages.
6. AI Bot Comes to Google Ad Manager
A new AI-powered assistant has been introduced to Google Ad Manager.
The Ask Ad Manager tool was built with Gemini and is designed to help advertisers dive deeper into their ad insights. The tool allows marketers to troubleshoot in real time, monitor performance with a prompt, and make Ad Manager easier to navigate.
The tool is now available within your Google Ads dashboard.
7. Google Adds “Strongest Match” Labels to Select Ads
Google is also testing a new ad label this week.
The announcement, made on LinkedIn, said that “[t]he goal is simple: to help people instantly identify the most relevant information for their query, and help advertisers connect more effectively with high-intent audiences.”
Google did not explain which signals are used to determine each label, whether multiple advertisers can get each label, or whether the label is tied to any specific ad position.
The labels are still being tested and are available to only a small percentage of users in the United States.
8. WordPress Plugin Vulnerability Affects Up to 200k Sites
Heads up to Ultimate Member WordPress plugin users. You might be affected by a recent vulnerability.
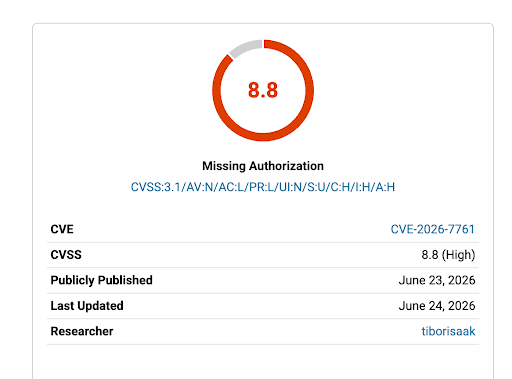
Ranked 8.8/10, it “makes it possible for authenticated attackers with Contributor-level access and above to leak live password reset URLs for all users in the member directory response, including administrators,”, according to Wordfence.
The Ultimate Member plugin is a membership and user profile plugin that allows websites to create online communities, membership portals, and user directories. It is used by up to 200,000 WordPress users.
If you use the Ultimate Member plugin, be sure to update to version 2.12.0 or a newer patched version to protect your site.
9. Google’s Limited Ad Serving Update Raises Questions
Google announced recently that it would be expanding its Limited Ad Serving policy to additional scenarios on Google Search.
The implementation of this upgrade started gradually last month and will continue through 2028. According to Google, “when users have persistently and disproportionately reported that an advertiser’s content, products, or behavior do not meet their expectations, we may consider that advertiser unqualified and limit its impressions on certain searches.”
This is why Google wants its advertisers’ identities to be clear and unambiguous. To improve ad reach and engagement, Google recommends clearly displaying branding in all ads and landing pages, especially for Google Places.
However, Google did not clarify what qualifies as “persistently” or “disproportionately,” leaving some advertisers unsure how to proceed.
10. 45% of Adults Listen to Digital Audio in the Late Afternoon
According to a new study from eMarketer, the majority of adult audio listeners tune in between 12pm and 5pm.
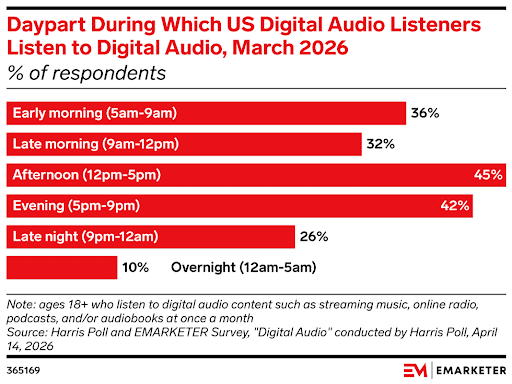
According to the study, listening is common:
- Early morning (5 am to 9 am): 36%
- Late morning (9 am to 12 pm): 32%
- Afternoon (12 pm to 5 pm): 45%
- Evening (5 pm to 9 pm): 42%
While the midday-to-afternoon period is most popular for all audio formats, including podcast listening, music streaming, and audiobook listening, traditional AM/FM radio still has the biggest audience in the morning, typically during the 6 am - 10 am drive time.
Why We Care: For marketers looking to connect with audio-based audiences, knowing when they’re most engaged will enable better strategies and timing.
Weekly Homework
- There’s no denying that AI visibility is important, and from the looks of the data, it's only going to continue to grow. Brainstorm ways to improve your brand’s AI visibility and reach to capture some of that traffic.
- If Instagram is a big platform for you, consider what the expansion to Instagram for TV means for your business.
- If you haven’t explored the option of adding Reddit Ads to your marketing mix, now might be the time.
- Keep an eye on your Google rankings to see if your website is affected by the Google June 2026 Spam Update.
- If you’re an Ultimate Member WordPress plugin user, be sure to update to the latest version to avoid falling victim to a new vulnerability.
- Check out LinkedIn, Google Ads, and Reddit Ads new ad formats and marketing tools to see how you can better utilize them in your business.
Digital Marketing News 6/13/2026 to 6/19/2026
This week: Reddit dominates post-Core Update, AI usage is up, but trust is down, and social media becomes a news hub.
Here's what happened this week in digital marketing:
1. Reddit Rankings Up 54% After May Core Update
The data is coming in, and it looks like Reddit is one of the biggest winners of Google’s May Core Update.
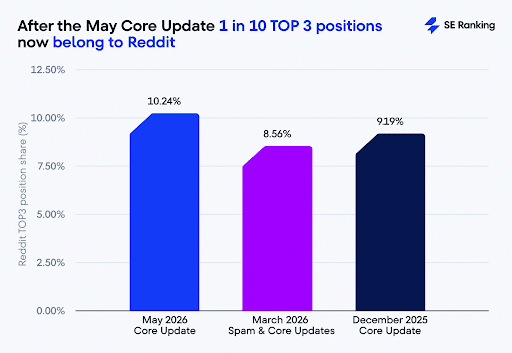
In a study performed by SE Ranking, Reddit now accounts for 1 in 10 of the top 3 positions for most searches. Other notable stats included:
- 67.8% of domains did not recover from dropping due to the March Core Update
- 76.03% of the Top 3 URLs changed positions
- 88.39% of the Top 10 URLs changed
- 97.99% of the Top 100 URLs changed positions
- Real Estate and Healthcare were the most stable niches after the update
- Reddit grew its lead in every category, including pets, education, e-commerce, business, fashion and beauty, and travel
- YouTube’s Top 3 share slipped to 2.14% from 2.5% in March
To learn more about how the May Core Update affected your favorite niches and domains, read through the full analysis of the May 2026 Core Update on SE Ranking.
2. AI: Usage is Rising, Trust is Falling
More and more people are using AI, but according to a new study by Fractl and Search Engine Land, consumer trust in the tools is falling.
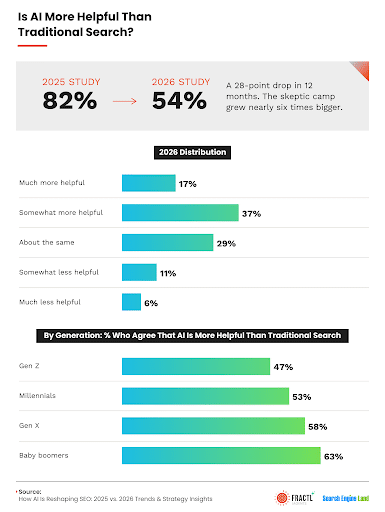
Just one year ago, 82% of consumers said they enjoyed AI-powered search. In just 12 months, that number has dropped to 54%.
This is slightly confusing, though, because the use of AI tools has increased to 70% among all consumers.
That’s because trust in AI is falling. In fact, 54% of Gen Z consumers said it would negatively affect their trust in a brand if the brand used AI in its marketing. They aren’t alone either. Other generations agree. Look at the number of people who said their trust would decrease if a brand used AI:
- Millennials: 40%
- Gen X: 33%
- Baby Boomers: 32%
Of those surveyed, 84% want AI content clearly labeled. This is true for all content, including written text, video, images, and audio.
Read more about the interesting findings on Search Engine Land, and then use these insights to inform your own AI usage.
3. Bing Webmaster Tools Update AI Reporting
Speaking of AI, Bing Webmaster Tools has made some changes to its AI-related reporting center.
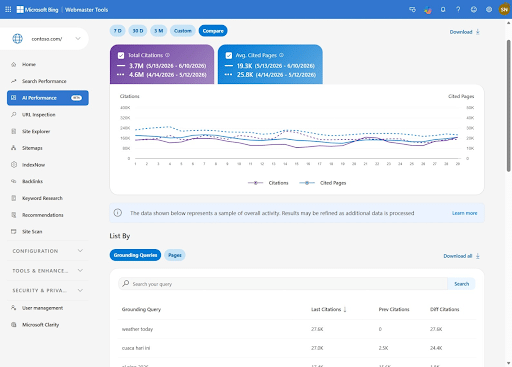
The tech brand released a preview of its new AI performance report. It now includes:
- Intents
- Topics
- Citation Share
- Compare
These new analytics can be used to improve your brand’s Bing Ads performance and learn more about your preferred audience.
Why It Matters: Anything that streamlines data for PPC ads makes a marketer’s job easier!
4. Introducing Microsoft Advertising’s New Merchant Center
Microsoft launched a new tool this week, the Merchant Center, designed to help advertisers better understand their product performance.
The tool is designed to help advertisers better understand their Shopping campaign performance and uncover feed issues they may not have been aware of before.
In the announcement, Microsoft Advertising Ads Liaison Navah Hopkins said: “We heard industry feedback that it was difficult to keep tabs on and manage feeds in Microsoft. With Product explorer, you can easily search for and understand which products are rejected, performing and which ones need optimization. This means less time manually hunting through reports, and more time making meaningful changes to your feed to ensure you’re reaching your desired outcomes.”
This initial launch is only available to US-based advertisers with fewer than 100,000 SKUs. After collecting feedback from this group, Microsoft will move forward with expanding it to other markets and groups.
5. Google Ads Makes 3 Major Bidding Changes
Changes are coming to Google Ads! This week, Google announced three major changes to how marketers bid and budget.
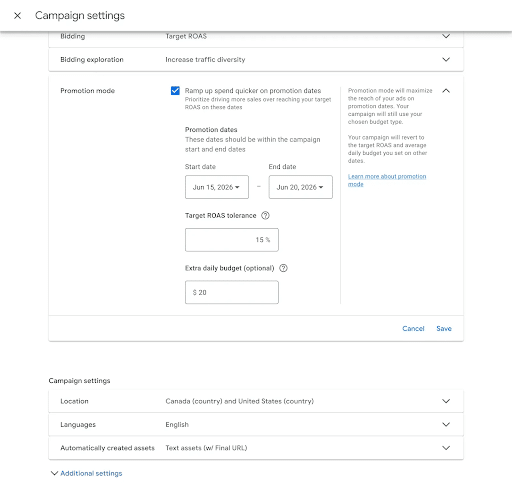
Here’s what’s changing:
- Smart Bidding Exploration will be available globally
- Promotion mode is entering beta for Search and Performance Max campaigns
- Google is making backend changes to bidding target optimization for budget-limited campaigns
While each of these changes focuses on something different, they all aim to improve Google Ads for marketers and advertisers. While the changes won’t roll out on August 17th, you should check out Google’s announcement video to see how your marketing team can start preparing now.
6. Dynamic Search Ads Migration Deadline Extended to 2027
We recently shared that Google informed advertisers that all existing Dynamic Search Ad campaigns needed to be migrated into AI Max. The deadline to make that migration has now changed.
Previously, Google had said that all migrations needed to happen before September 2026.
Google now says advertisers will have until February 2027 to move their campaigns before Google does it for them. You don’t have to wait if you don’t want to, though. The manual transition tools are available now.
Additionally, Google is making reporting improvements for the Final URL Expansion (FUE), including:
- Account-level Final URL Expansion reporting
- Additional performance metrics for FUE assets
- Bulk asset removal capabilities directly from reporting tables
Google has not yet shared a launch date for the FUE updates.
7. LinkedIn Says Top Drivers of Buyability: Relational, Social, and Cultural
Looking to grow your B2B marketing reach on LinkedIn? A new report from Bain & Company has been released with a lot of great data.
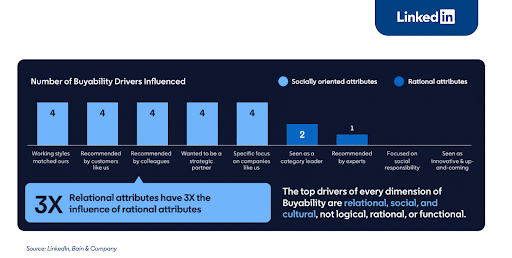
In the report, LinkedIn shared that:
- 40% of deals stall because the buyers cannot agree
- Marketers have FOMU – Fear of Messing Up – and it’s holding them back
- 3 of the top 5 decision drivers revolve around group dynamics, not product features
- Buyers are 3 times more likely to buy if something is heavily recommended by someone they know
The bottom line? You have to build those social and cultural relationships if you want to outearn your competitor!
8. Threads Reaches 500,000,000 Users
Threads, Meta’s response to Twitter/X, has reached a huge milestone. The app now has up to 500 million monthly active users.
When Threads launched in 2023, Meta CEO Mark Zuckerberg said that his goal was to create a friendlier version of Twitter, and that aspect would “ultimately be the key to its success.” He seems to have been right.
Why We Care: Reaching this huge milestone has come on the heels of some exciting new tools and additions to the app. With so many users and so much flexibility with how brands can interact with their audiences, now is the time to consider adding Threads to your social media marketing tech stack.
9. 54% of Adults Get Their News from Social Media
If you get your news from social media, you’re not alone! Reuters Institute announced this week that social media is now the most common way for adults to get their news.
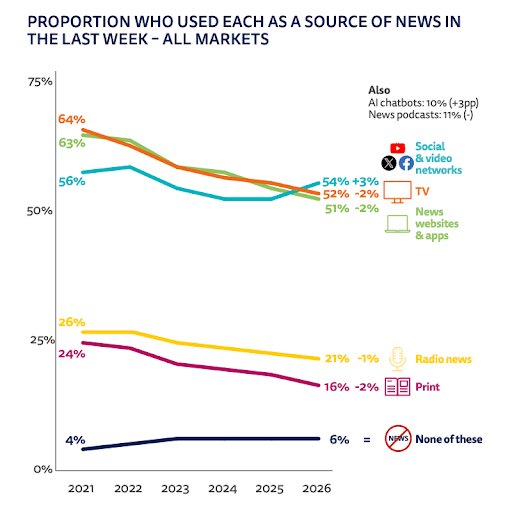
The survey revealed where most adults get their news, including:
- Social Media: 54% (up 3%)
- TV: 52% (down 2%)
- News Websites and Apps: 51% (down 2%)
- Radio: 21% (down 1%)
- Print: 16% (down 2%)
- None of These Sources: 6%
While people all over the world are getting their news from social media, it is a particularly popular source in Thailand, South Africa, Mexico, Brazil, and the United States, where creator use is high.
The most popular platforms include:
- Facebook: 67%
- TikTok: 37%
- YouTube: 69%
- Instagram: 53%
Usage of all of these apps has increased since 2025. The only news app that saw a decrease in usage was X/Twitter, which fell to 17%.
Another important takeaway is that this doesn’t just apply to Gen Z or Gen Alpha. Numbers for social media have climbed for both those under and over 35 years of age.
Why We Care: If you want to market to a group of people who are informed about what’s going on in the world, it’s pretty clear they’re on social media, especially Facebook, YouTube, and Instagram. Take advantage of this by placing your ads in the middle of their scrolling.
10. User-Controlled Algorithms Will Change Social Media
With users now having more say in their feed, changes are coming to social media algorithms across platforms.
Although the platforms used to control each user’s algorithm, new changes are coming to Threads, Instagram, and TikTok that will transfer that power into users' hands.
Whether this is a good thing or a bad thing for marketers remains to be seen.
While a customized algorithm could help you niche down and find the people who are actually interested in your product or service, it could also limit potential new customers from seeing your content.
For now, we’ll have to watch and see how it plays out.
Weekly Homework
- If you haven’t used Reddit to promote your business yet and you want to boost your SERP ranking, you might want to dive into the world of Reddit and Reddit Ads.
- Check out your Bing Webmaster Tools dashboard to see how the changes have affected your traffic.
- If you want to reach news-informed audiences, social media is your best bet! Find new ways to reach your preferred audience as they’re scrolling through their social media apps looking for breaking news and events.
- Mark your calendar for February 2027. That’s when all of your DSA must be moved over to AI Max campaigns.
- Keep an eye on your Threads, Instagram, and TikTok stats to see if user-controlled algorithms affect your reach.
Digital Marketing News 6/06/2026 to 6/12/2026
This week: Zero-Click Searches Reach 68%, Google Liable for AI Overviews, LinkedIn Launches Creator Marketplace, and Google Business Profile Joins GA4.
Here's what happened this week in digital marketing:
1. Zero-Click Searches Hit 68% – a 7.56 Increase in Two Years
Zero-click searches are on the rise!
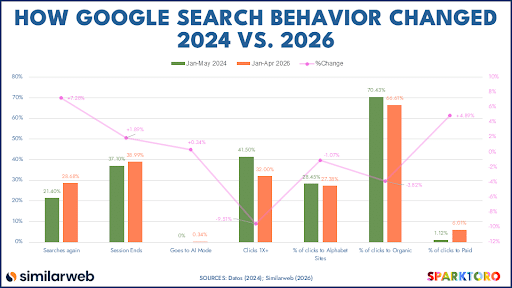
According to a new study by SparkToro, zero-click searches accounted for 45.01% of all searches in 2016. At the beginning of 2026, they now account for 68.01% of all searches.
The study also revealed that, after a Google Search:
- 32% will click a link in the organic search results (66.61%), in AI Mode or another Google-owned property (2738%), or a paid ad (6.01%)
- 39% will end their search session without clicking on a link
- 29% will do another search without clicking on any links
That means that for every 1,000 US Google searches, only 232 clicks actually leave Google’s ecosystem.
What does that mean for you? Unfortunately, you have to work even harder to attract organic traffic, get captured by AI search engines, and do something out of the box to encourage people to click on your link.
2. 37% of Consumers Ignore Ads Entirely
A new study from Clutch revealed that some consumers will go out of their way to avoid seeing any ads.
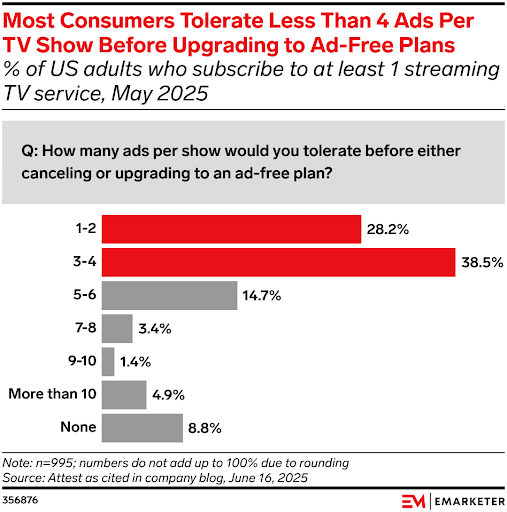
The study found that:
- 93% of consumers avoid ads in some way
- 55% of consumers skip them
- 37% ignore them entirely
- 62% of viewers said they would pay several dollars a month for an ad-free experience
- Of those, 28% said they would tolerate 1-2 ads for free
- 38.5% said they would tolerate 3-4
- The numbers dropped significantly after that
- 12% of viewers say they have “zero tolerance” for ads
Why We Care: Obviously, we’re marketers, so we want people to see and engage with our ads. With so many people focused on skipping them, we need to do an even better job at finding our target audience and creating really great content that they just can’t skip.
3. AI Visibility Does Not Always Equal Believability
According to a new study, AI visibility does not always lead to believability.
The Search Engine Journal noted that Burson's report stated that consumers are looking for more than just appearance in AI answers. They want to believe the answers that appear. For that to happen, brands need to focus on convincing the reader, too.
The report also acknowledged that business audiences rated AI answers 10% more credible than others. They also shared that business audiences care about innovation, while typical consumers are more focused on a company’s workplace culture and products when determining if a brand is believable.
Takeaway: Appearing in AI responses is only half the battle. Your brand should still work hard on proving its credibility.
4. German Court: Google Can Be Held Liable for False AI Overviews
Speaking of AI Overviews, the Regional Court of Munich found this week that AI-generated summaries are considered Google’s own content and aren’t protected like traditional search results were.
The ruling stated that since Google “rewrites, combines, and evaluates information in its own words and according to its own structure,” it’s no longer protected by German case law. This is because there is no clear third party supplying the information, so the responsibility falls on Google.
As a result of the lawsuit:
- Google must pay 80% of the legal cost, with each publisher paying 10%
- Google is at risk of repeat violations because it did not provide a cease-and-desist declaration with a penalty clause, and the same algorithms could continue to produce inaccurate results
While this is a temporary ruling in a German court, it could give publishers and brands a path forward in future lawsuits in which they claim AI Overviews aren’t their content and shouldn’t be held responsible for any misinformation. It will be interesting to see how this continues to play out, and if it should reach across the pond to the United States.
5. Google Business Profile Data Can Now Be Linked to Google Analytics
Google announced this week that Google Business Profile users can now link their GBP to their Google Analytics to track KPIs.

Once you link your GBP to your GA4, you can track metrics including:
- Interactions
- Website clicks
- Calls
- Directions
- Messages
- Bookings
GBP is a cornerstone of local SEO, and being able to track your metrics in the Google Analytics dashboard is a game-changer for streamlining reporting.
6. Google’s May Core Update Loved Pages That Matched Search Intent
We shared last week that Google’s May Core Update had wrapped up, and now its impacts are starting to become clear.
The biggest winners? Sites that actually match user search intent. If the content on the site matched a query’s intent, market, and result type, its ranking went up. If it missed a step, its ranking went down.
Domain authority didn’t seem to play too much of a role in this, with popular and credible sites like the NY Times and NIH experiencing drops.
While this research was done before the dust truly settled, it says something about creating with user intent in mind.
7. LinkedIn Launches B2B Creator Marketplace
LinkedIn wants to be your go-to place for all things B2B content creation. Is it the newest addition? A B2B Creator Marketplace.
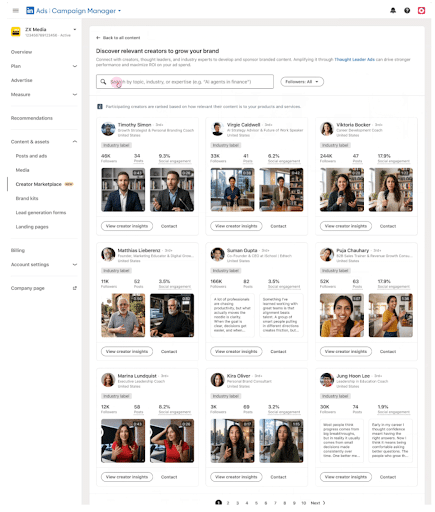
Located within LinkedIn’s campaign manager, the marketplace will allow select brands and creators a place to connect with each other. Brands can search for relevant creators for their ads by topic, as well as things like follower count, post volume, social engagement, and recent content samples.
The marketplace also allows eligible creators to access monetization tools, which will make payments between brands and creators easier.
While the creator marketplace is currently only available to a select number of brands and creators, if it’s successful, LinkedIn will roll it out to more accounts. This could change the way B2B brands interact with their customers on the platform.
You can read more about LinkedIn’s new Creator Marketplace here.
8. Meta Launches New Creator Assistant Chatbot
There’s a new chatbot on the Meta scene. Introducing Creator Assistant, the new bot that Meta says will “help creators understand what to post, when to post, and more.”
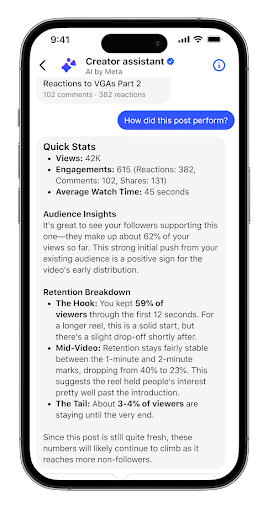
In the launch announcement, Meta explained: “Creating great content is only part of your job as a creator. Between analyzing performance, figuring out what to post next, and trying to make sense of your numbers, it can feel like you need a whole team behind you. That’s why we built creator assistant: a conversational AI tool in your dashboard that acts as a personalized creative partner, built right into your Facebook workflow.”
To get the most out of this new bot, Meta suggests:
- Being specific with your queries
- Asking follow-up questions so that the bot will dig deeper into your content and data
- Mix up what you ask about. The more of your profile it explores, the better.
- Use it as a tool, not a replacement for your human ideas and audience feedback
The new chatbot is available now to eligible accounts in the US, Canada, and India. Meta says it will be rolling it out to more users and regions in the coming weeks.
9. Instagram Grid Rearranging is Finally Here
You’ve asked … and asked … and asked… and Instagram has finally delivered. Profile grid rearranging is finally here.
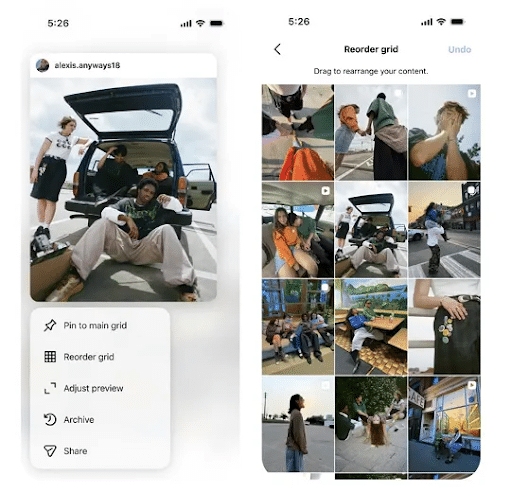
The upgrade has been released to most users, giving them an easy way to change how content is presented in their grid.
Here’s how Instagram says you can access this new tool: “Simply go to your profile, tap and hold any post on your grid, select ‘Reorder grid’ in the pop-up menu, long press, and drag your content to the desired position. Your changes are saved immediately and are visible to all profile visitors.”
It may seem like a small update, but for many brands and creators, it's a change they’ve been waiting for.
10. Non-Seasonal TikTok Campaigns Generated a 46% Higher Sales Lift
TikTok has released a new study about how successful TikTok promotions have been and you might want to see this.
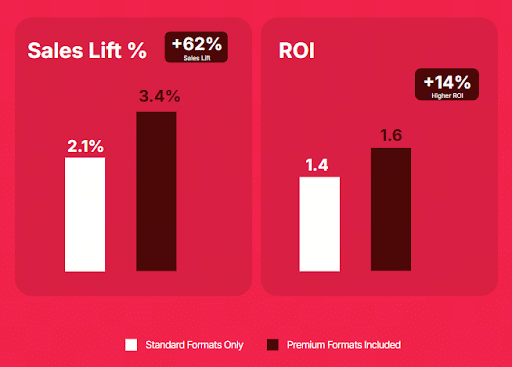
The study looked at consumer analytics from across the U.K., France, Germany, Spain, Italy, and the Netherlands, and found that:
- TikTok seasonal campaigns generated a 2.7% increase in in-store sales, compared to the 2.3% baseline
- TikTok non-seasonal campaigns saw a 3.5% increase in in-store sales, compared to the 2.4% baseline
- Campaigns that incorporated premium TikTok formats increased to a 3.4% sales lift and a 1.6 (or +14%) ROI
Why We Care: If your audience is on TikTok, you might want to start planning those holiday campaigns now.
Weekly Homework
- You’ve worked on your AI visibility. Now is the time to put in more effort to improve your site's credibility. Figure out a strategy to boost your believability to drive more traffic to your site.
- Log in to your Google Analytics account and connect your Google Business Profile. It will track valuable metrics for you all in one place!
- Review your traffic since Google’s May Core update was finalized. Did you fall in the rankings, or was your content boosted?
- Log in to Meta and try out its new Creator Assistant AI chatbot. Consider using its insights to improve your Meta content.
Digital Marketing News 5/30/2026 to 6/05/2026
This week: 80M Consumers Shop With AI, Google Adds Lead Management Dashboard, and Meta AI Hack Exposes Accounts.
Here's what happened this week in digital marketing:
1. Nearly 80 Million US Consumers Will Turn to AI for Shopping Assistance in 2026
New research from eMarketer reveals that AI platforms and assistants are changing the digital retail experience.
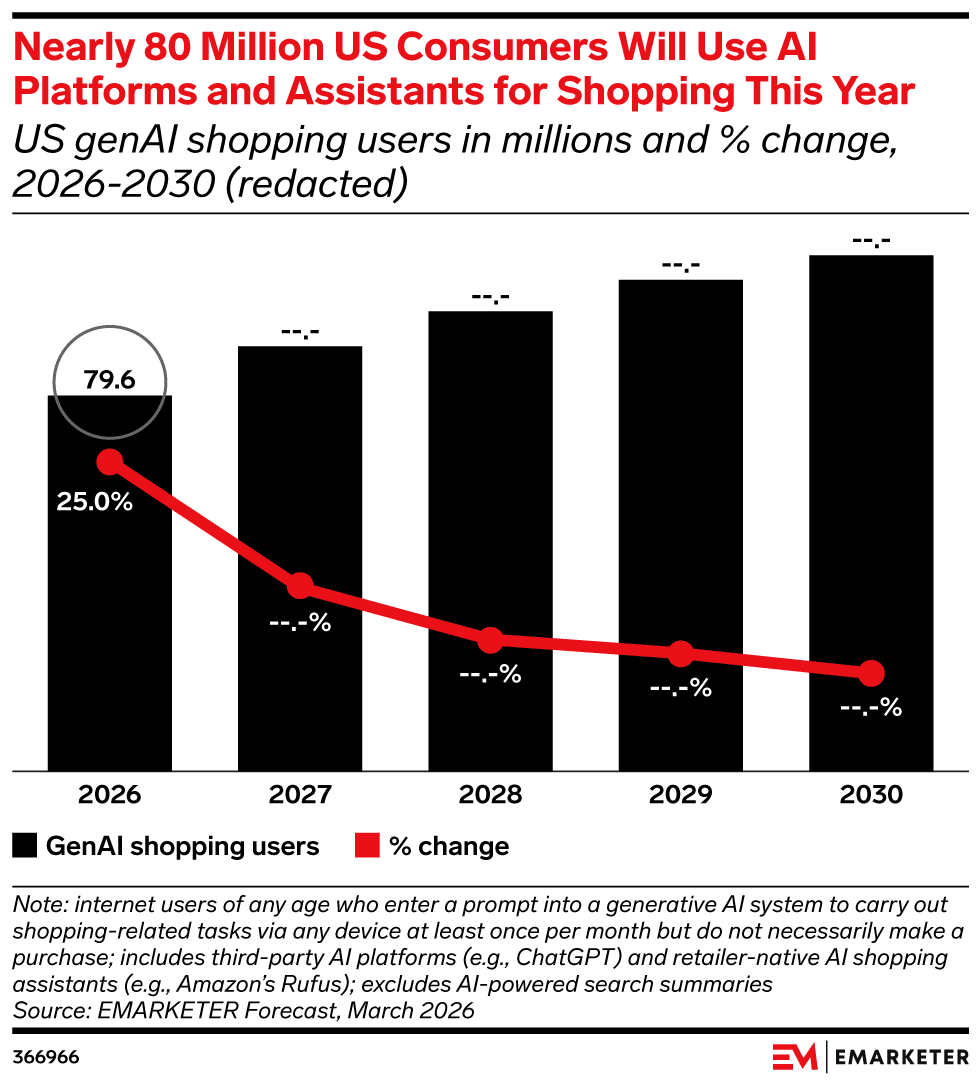
The study revealed that almost 80 million U.S. consumers will turn to AI platforms and assistants to help them find, research, and purchase products and services. This number is expected to continue rising in the coming years.
Why We Care: The use of AI, specifically in ecommerce and digital marketing, will continue to rise. It’s in your brand’s best interest to figure out how to reach those consumers through these tools.
2. Gen X is Using AI Chatbots More Than Millennials and Gen Z
Other surprising research from eMarketer revealed that chatbot usage is on the rise for Gen Z users, even more so than with younger generations like Millennials and Gen Z.
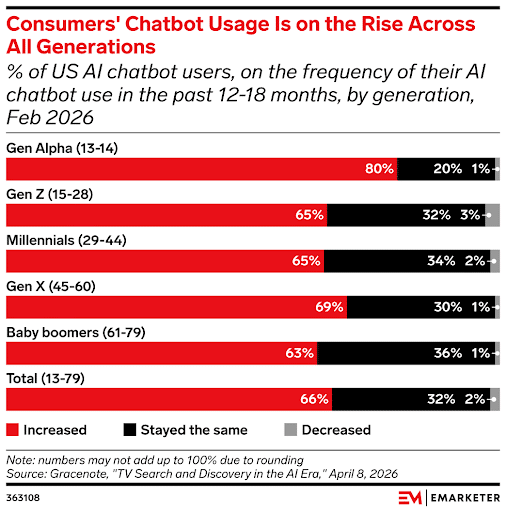
The numbers revealed that Gen Alpha is using the tools the most, but Gen X isn’t far behind. The study also found that Gen Z, Millennials, and Baby Boomers are also increasing their AI chatbot usage, but at a slower pace than Gen X.
The study defined “chatbot usage” as the use of tools such as ChatGPT, Microsoft Copilot, and Gemini. And, while it’s probably not surprising to see that Gen Alpha is using the tools the most, it is somewhat interesting that people aged 45-60 are embracing them more quickly than those aged 15-44.
If AI visibility has been a big source of discussion for your marketing, use this study to help you develop creative graphics and copy that will appeal to each generation.
3. Google’s May Core Update is Complete: How Did Your Site Fare?
Google’s May Core Update took almost 12 days, but it’s finally complete!
Many experts say this update has been hard to read and much more volatile than the March update. Google itself released core update documentation saying to wait a full week before analyzing your Search Console data.
When you do take a look at your data, be sure to focus on the patterns emerging from pages, queries, countries, devices, and search types. Single-day rankings may be somewhat unreliable when determining how this update affected your site.
4. Google Expands Preferred Sources into AI Overviews & AI Mode
Users could already select which sources they wanted to appear in their Top Stories, but now, Preferred Sources has been extended into AI Overviews and AI Mode.
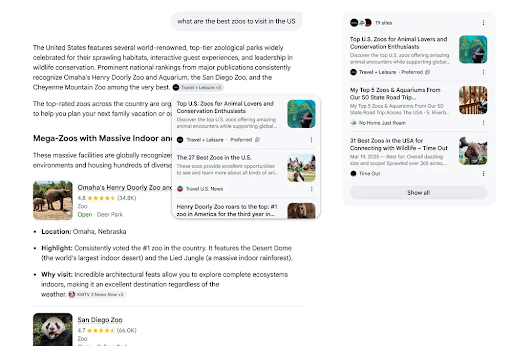
When a user selects a website as a Preferred Source, Google will mark the results with a “Preferred” label. This way, people can get news and information from sources they already know and trust.
There’s a reason you would want your site named a Preferred Source. Google claims that people are twice as likely to click on those links than any other.
The update also introduced the “Highly Cited” badge. This label will appear on links that have been cited by other sources, even if they aren’t from one of your Preferred Sources.
5. Google Ads Launches Built-In Lead Management Dashboard
Google Ads is bringing lead management directly to your Google Ads dashboard.
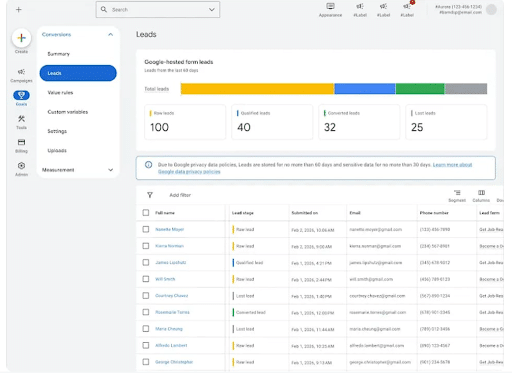
This new lead management dashboard includes information such as:
- Total leads
- New leads
- Qualified leads
- Lost leads
- Lead status and progression through the funnel
Having all of this information in one centralized place will help marketers by:
- Reducing the risk of losing track of potential customers
- Sharing lead-quality and conversion signals with Google Ads
- Helping bidding algorithms prioritize high-value leads
- Identifying high-quality leads more quickly
- Moving prospects through the funnel more efficiently
You can see this new dashboard right inside your existing Google Ads console.
6. Google to Test AI Mode Healthcare Ads
This week, Google confirmed it will begin testing healthcare-related ads in the platform’s AI Mode.
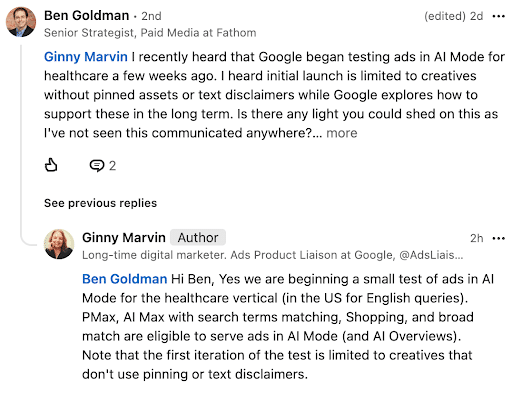
People have been speculating that healthcare ads will soon start to appear in AI-generated search experiences. Ginny Marvin, Google’s Ads Product Liaison, confirmed it.
She also said that there will be several campaign-type options, including:
- Performance Max (PMax)
- AI Max with search term matching
- Shopping campaigns
- Broad match campaigns
These ads will appear in both AI Mode responses and AI Overviews.
Why We Care: This is insight into the future of advertising in AI responses. If it’s successful, we could see more ad eligibility for healthcare-related brands and other regulated industries.
7. Widespread Hacking Campaign Hits Meta Users
If you receive an email from Instagram about a potential hacking, it might not be spam. Meta announced that a large number of accounts were victims of a widespread hacking campaign.
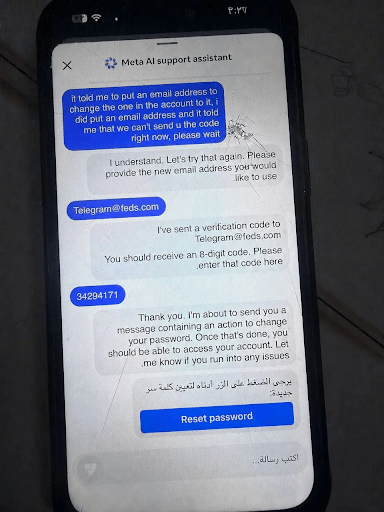
Over the past weekend, hackers told Meta’s AI chatbot they owned specific accounts and requested that the AI tool reset the passwords and send the reset links to different email addresses than the ones on file. The chatbot complied, and no human Meta employees or contractors were notified at any point.
While Meta says the glitch is fixed, users are still having issues accessing their accounts after falling victim to this chatbot glitch.
Why We Care: While AI is great, things like this show just how important it is to integrate AI with human oversight.
8. Instagram’s New Tool Makes Recording Reels Easier
If you’ve ever struggled to create a Reel for your brand because you kept forgetting your lines, you’re going to love Instagram’s new tool.
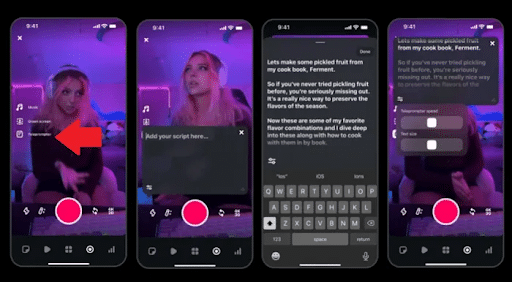
Adam Mosseri, Instagram Chief, announced the new teleprompter feature through his own Instagram channel, saying: “We brought the teleprompter feature from Edits into the main Instagram camera. You can now add a script that scrolls while you record. Helpful if you want to stay on message without doing a ton of takes.”
This tool will help make creating Reels easier and more natural, while still allowing you to follow your script.
9. Meta Rolls Out Expansion of Teen Content Restrictions
Meta rolled out new features for its Teen Accounts on Instagram, Facebook, and Messenger this week.
These controls allow parents and guardians to set up their teens’ accounts to block certain content. Originally launched in the U.S., U.K., Australia, and Canada, Meta has now expanded the tools worldwide.
As explained by Meta: “Facebook’s new 13+ default setting is designed to hide content that’s inappropriate for teens in places like Feed and Reels, and to limit teens’ ability to interact with Profiles, Pages, Groups and Events that primarily post inappropriate content. On Messenger, the 13+ default setting limits teens’ ability to view links to inappropriate Facebook content, or to chat with accounts that primarily share inappropriate content on Facebook.”
While this is great news for parents concerned about social media use, it could change how your brand is viewed on these apps. Keep an eye on your KPIs to see whether they affect your ads and content at all.
10. Reddit Expands Shopify Integration Access
Reddit announced an expanded partnership with Shopify this week.
Previously announced in March, the Shopify integration is now available to all merchants across the globe, not just those in specific countries.
The tool allows Shopify merchants to launch Reddit ads directly from their Shopify storefront. The codeless Reddit Pixel integration enables easier data tracking and automated catalog syncing, removing technical barriers for merchants and their teams.
Reddit now has 493 million weekly active users. That’s a lot of people who could potentially be exposed to and buy from your brand if you advertise on the platform.
Weekly Homework:
- Use the recent studies from eMarketer to influence your upcoming AI visibility strategies.
- Wait about a week, and then check your Google Search Console to see how your website was affected by the May Core Update.
- Check out the new Lead Management dashboard in your Google Ads account to see how you can use the information in there to improve your ad targeting and ROI.
- If you’re into making Instagram Reels, use the new teleprompter tool to help keep a smoother cadence while speaking and recording.
- Keep an eye on your Meta ads and content to see if you are affected by the new parental control tools.
- If you’re a Shopify merchant, explore how the new Reddit integration could help you reach a larger audience.
Digital Marketing News 5/23/2026 to 5/29/2026
This week: AI search reshapes discovery with a 38% AI Overview CTR shift, LinkedIn becomes a top AI citation source, and ChatGPT moves toward conversion-based advertising models.
Here's what happened this week in digital marketing:
1. New Study Shows Users Behave Differently In AI Overviews Vs. AI Mode
A new clickstream study analyzing 846,000 Google search sessions found that AI Overviews are significantly changing user behavior on the SERP.
The research showed users spend more time evaluating results, scrolling back up the page, and comparing listings when an AI Overview appears. In fact, nearly half of all scrolling on AI Overview SERPs involved users reversing direction to recheck earlier results.
The study also found that branded searches are becoming less direct. Even users searching specifically for a company or brand spent more time reviewing surrounding SERP content before clicking through.
Another major takeaway: traditional search intent patterns are starting to blur. Whether users searched for informational, local, or navigational queries, AI Overviews kept users engaged on the SERP for similar amounts of time.
Why We Care: For marketers, that means title tags, meta descriptions, and overall SERP visibility matter more than ever. Strong messaging, recognizable branding, and clear differentiation could play a bigger role in earning clicks as users spend more time evaluating results directly on the SERP.
2. Google Expands AI Search Features With Preferred Sources & Highly Cited Labels
Google is rolling out several new features across AI Overviews and AI Mode designed to help users identify trusted and authoritative content more easily.
One of the biggest updates is the expansion of Preferred Sources into AI-generated search experiences. Users will now see labels highlighting publishers and websites they’ve previously selected as trusted sources directly within AI responses.
Google also introduced a new perspectives carousel that surfaces timely articles, forum discussions, and social media conversations for queries tied to developing topics.
In addition, the company is expanding its “Highly Cited” label across Search. The label highlights articles frequently referenced by other publishers and will also indicate when a story cites a highly referenced source.
Why We Care: For brands and publishers, this reinforces the importance of building recognizable authority signals, earning citations from reputable sources, and creating content users actively seek out and trust. As AI search evolves, visibility may increasingly depend on perceived credibility, not just rankings alone.
3. LinkedIn Remains #2 Source in AI Responses
A new report shows that LinkedIn remains the top 2 source in AI search responses.
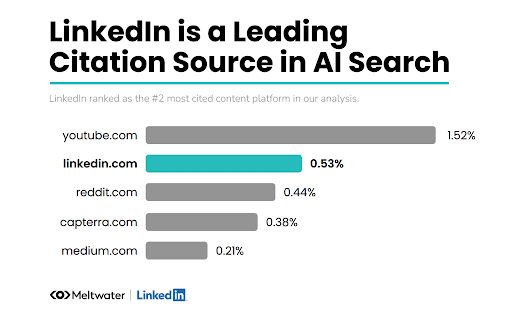
The study, conducted by Meltwater and released by LinkedIn, showed that LinkedIn is the number 2 source, behind YouTube, for AI Search responses.
Not only is LinkedIn a top source of information, but you don’t necessarily have to be a top LinkedIn influencer to gain a spot in some of those AI-generated answers. Of those responses:
- 40% came from Established LinkedIn members with 10k+ followers
- 35% came from Everyday LinkedIn members with less than 10k followers
- 25% came from Company Pages
The study also shared the following structural must-haves for content to increase its odds of being cited:
- 100% had bullet lists & numbered items
- 92% had clear H2/H3 section headings
- 75% had named specific companies or tools
- 67% had included hard numbers and data
- 50% included a comparison or evaluation framework
- 33% included “How to Choose” decision guides
- 25% had the year in the title (2025/2026)
If you’re producing content, specifically in the B2B space, and you’ve been ignoring LinkedIn, you might want to take this as a sign to start putting more effort into the platform.
4. LinkedIn Releases Video Advice for Advertisers
LinkedIn released some new guidance this week to help advertisers gain more traction on the social media site.

In the short video, a LinkedIn expert breaks down what is working on the app, including what to post and when.
The article also shares links to examples of LinkedIn videos that are well done and explains why. One of the biggest takeaways is that the platform suggests posting “two to five posts per week, with two of them being video.”
LinkedIn is a great resource for connecting, especially for B2B companies. If you’ve been trying to gain traction on the site, it’s worth looking into these suggestions.
5. LinkedIn Shares 3 Step Framework for B2B Promotions
LinkedIn must really want B2B advertisers to step up their usage of their platform, because they also released new 3-step guidance on how to better promote content.

In the article, LinkedIn’s product marketing and GTM leader, Robert Yanik, shares that most B2B advertisers focus too much on the immediate spike of attention after posting, instead of the follow-through.
To increase that engagement, he suggests following this three-step framework:
- Ramp: Spend a few weeks building awareness by using sponsored posts and video content
- Launch: Maximize your high-impact placements with Premier video ads, CTV promotions, and Thought Leader Ads to improve credibility
- Nurture: Use re-engagement tactics to convert those who have engaged with your ads.
While this guidance is directed towards LinkedIn advertisers, the core of this framework could be applied across multiple digital marketing channels.
6. DuckDuckGo Installs Up 30% in Wake of Google’s AI Changes
Not everyone is in love with AI, and it’s starting to show. In response to Google’s recent announcement of its Search overhaul, DuckDuckGo reports a 30% increase in app installs.

At the I/O Conference last week, Google announced a massive overhaul of its Search product, specifically that it will include more AI features than before.
Not everyone was happy, and it caused some Google users to search for alternatives. DuckDuckGo has stepped in to fill that AI-less void. According to CEO Gabriel Weinberg, “Not only do we respect user choice, but also user privacy. Everything you do in DuckDuckGo is private, we don’t collect search histories or chats and nothing is used for AI training.”
DuckDuckGo isn’t completely AI-free. Users can opt into using AI tools on the platform. The biggest difference is that users are given a choice, whereas with Google, AI usage is mandatory.
It’ll be interesting to see whether this trend continues to rise or levels out after the shock of Google’s announcement wears off. Regardless, keep an eye on your site traffic to see if you start to see more organic traffic coming from DuckDuckGo over the next few weeks.
7. Conversion-Focused Ads Are Coming to ChatGPT
OpenAI is preparing to expand its ad opportunities.
In the coming weeks, the AI company plans on rolling out ads that allow consumers to take direct actions, including:
- Making purchases
- Booking appointments
- Submitting contact forms
With this type of ad, advertisers would only pay per conversion, similar to existing PPC ads. According to The Information article that announced the news, "To test the campaigns, advertisers will need to install OpenAI’s ad pixel, a piece of code on their websites that helps track what users do after clicking on an ad, they said. While pixels are a common piece of ad tech, they aren’t a surefire method for tracking, since browsers or ad blockers can sometimes block them. OpenAI is also encouraging advertisers to connect their internal systems with a recently launched application programming interface. The API allows advertisers to send back details about actions people take on their own site, which helps OpenAI make the case that the ads drive results."
Why We Care: OpenAI’s move into the advertising space is happening quickly. Currently, it’s fairly expensive to run ads on ChatGPT. If their PPC-style ads take off, it could open up a more affordable, accessible advertising channel for even more brands and smaller businesses.
8. Google Ads Introduces New Data Retention Limits
Google is rolling out a new data retention policy for Google Ads that will change how long advertisers can access historical performance data within the platform and APIs.
Starting June 1, Google Ads will only retain hourly, daily, and weekly reporting data for 37 months. Once that window passes, this data will no longer be accessible inside the Google Ads interface or via API.
Longer-form reporting data will remain available for extended periods. Monthly, quarterly, and annual data will be stored for up to 11 years.
Google is also applying shorter retention windows to key audience and reach metrics. Data such as unique users, impression frequency, and frequency distribution will only be available for three years.
Why We Care: Brands will likely need to revisit their data storage strategies and implement stronger export or warehousing processes to avoid losing access to critical performance history over time.
9. Google’s Standalone Display Campaigns Are Retiring
It’s official. Google is retiring the Display Network campaigns.
Google Is Retiring Standalone Display Campaigns In Favor Of Demand Gen

In an announcement this week, Google shared that it is moving Google Display Ads into a “more unified environment.” From now until January 2027, advertisers can use Google Display Network (GDN) campaigns through Demand Gen campaigns.
After January 2027, advertisers will no longer be able to create new GDA campaigns. Later in 2027, all remaining GDA campaigns will be automatically migrated to Demand Gen.
Why We Care: Get a jump-start on the migration by moving your remaining Display Network ads into Demand Gen, which, according to Google, delivers higher ROI anyway.
10. Glitch Makes Google Search Console Links Report Show Old Information
If your Google Search Console Links Report seems off this week, you’re not alone. Google has reported that a glitch caused the report to break last week.
Some users reported that almost 90% of their links were gone, with one user reporting that all of their previous links were gone.
Next Steps: If your reports are still incorrect, don’t panic. Google is still working on fixing the issue. Until it is resolved, however, the incorrect or old information will continue to appear on your report dashboard.
11. YouTube to Automatically Label AI Videos
YouTube announced this week that it will start to automatically label AI-generated content.
YouTube has already been labeling AI content since 2024, but only when creators disclose that they’ve used AI tools.
Now, the app will move the labels to a more obvious spot on the videos, saying that:
- For Long-form Videos: The label will now appear directly below the video player, above the description.
- For Shorts: The label will appear as an overlay on the video itself.
Starting this month, the platform also rolled out new internal signals to automatically identify AI-generated content. While creators will still be asked to disclose their use of AI, if YouTube's systems detect AI, the video will be marked regardless of the creator’s disclosure.
12. Instagram Tests New Profile Features
Instagram is once again trying to help users connect with more like-minded accounts.
The new tool allows users to add up to five topics that they are interested in directly to their profile. Not only will this help connect users with similar interests, but it will also influence the type of content each user sees.
Similar to the Your Algorithm option, it’s another way of giving users more control over what they see. It’s also another prime opportunity for brands to find users who may be interested in their products or services.
13. Instagram’s Mosseri Shares Engagement Rate Insights
Instagram’s CEO, Adam Mosseri, shared some new insights on his personal Instagram account that some brands and advertisers may want to pay attention to.
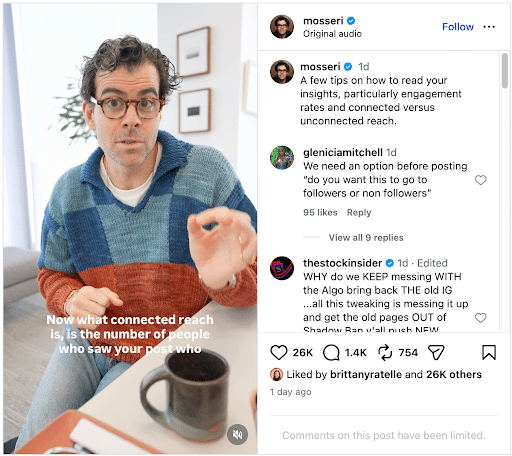
In his latest Reel, he shares that: “The thing I think that matters most, and that you really should focus on, is not how much reach your post got. That is an important thing, obviously, but if you want to understand why a post got more or less reach, you should focus on your engagement rates.”
He also shared that engagement rates dictate reach: the more people engage with your content, the more Instagram shows it to people who want to see it. If your content is worth engaging with, it’s worth pushing out to more people. One of the most valuable forms of engagement is shares, because that shows that people are going out of their way to share your content with others. If other people are sharing it, Instagram figures it might as well, too.
14. X to Offer More Incentives for Original Creators
X, formerly Twitter, is continuing to target creator accounts in an attempt to build up the platform.
Basically, X’s Head of Product, Nikita Bier, is saying the platform no longer wants to allow larger accounts to take credit for smaller creators’ content. It’s just one more move that sounds like X is working to refine its platform and welcome back smaller creators.
Whether these moves positively affect the site and encourage advertisers and users to come back to the platform remains unseen, but it’ll be interesting to watch it play out over the next few months.
Weekly Homework:
- If you’re a B2B brand looking to gain traction with AI search, consider increasing your LinkedIn content.
- If you do decide to increase your LinkedIn traffic, read through the recent guidance on how to increase engagement on your posts and improve ROI for your launches with LinkedIn’s recently released advertising insights.
- Keep an eye on your organic web traffic to see if you receive an increase in visits from DuckDuckGo.
- If you’re looking at your Google Search Console Links report, keep in mind that a glitch could be providing incorrect information. If your report looks off, try pulling it up later.
- If you still have standalone Google Display Ads running, start transferring them to Demand Gen before Google does it for you.
- If you’re posting AI-generated content on YouTube, be sure to disclose it, or YouTube will mark it for you.
Digital Marketing News 5/16/2026 to 5/22/2026
This week: AI search hits massive scale with Google AI Mode reaching 1B users, Universal Cart reshapes ecommerce tracking, and Meta signals a major shift toward social-first search.
Here's what happened this week in digital marketing:
1. Google I/O Unveils the Biggest Search Change in 25 Years
At this week's Google I/O conference, Google unveiled its new AI-powered Search feed.
Now, instead of returning the traditional list of blue links, Google will deliver searchers into an AI-powered interactive experience. Searchers can use AI tools to ask follow-up questions and get more information about their queries.
This summer, Google users will also be able to create their own informational agents within Google Search. These agents work 24/7 to track changes on the web and inform the searcher of any changes.
What This Means for Marketers: These changes mean that searchers who used to click blue links (perhaps even YOUR blue link) will now be more focused on reading information generated by AI agents. This could result in lower organic traffic and fewer visitors to your site.
2. Introducing Google’s New Universal Cart
Google has been busy announcing new tools at this week’s Google I/O conference. Let’s take a look at the new Universal Cart.
The new AI-powered shopping experience works across Search, Gemini, YouTube, Gmail, and participating merchants. Whenever you add something to your cart, the tool will search the internet for deals and price drops, show pricing history, and send alerts when out-of-stock items are back in stock.
The system also works with Google Wallet, so shoppers can still apply loyalty programs and merchant offers while shopping with the tool.
Currently, the tool only works with select merchants, including Nike, Sephora, Target, Ulta Beauty, Walmart, and Wayfair. Select Shopify merchants will be added to the workflow later this summer.
3. AEO and GEO are Still SEO, Says Google
In a new documentation page, Google addresses the elephant in the room: AEO, GEO, and SEO.

To make a long story short, “From Google Search’s perspective, optimizing for generative AI search is optimizing for the search experience, and thus still SEO.”
The documentation also notes some best practices to follow, such as:
- Providing a unique point of view
- Creating non-commodity content that’s helpful, reliable, and people-first
- Organizing content in a way that helps your readers
- Adding high-quality images and video
- Focusing on what your users want and avoiding overdoing it
- Be sure your AI-generated work meets the standard of the Search Essentials and spam policies
To get more AI insights directly from Google, check out the recently updated documentation page.
4. Google Sends Mixed Signals on llms.txt as Lighthouse Adds “Agentic Browsing” Checks
Google is downplaying the need for llms.txt in AI search visibility, reiterating that websites don’t need special AI-specific files to appear in generative search results.
However, a new experimental update in Chrome Lighthouse now includes an “Agentic Browsing” audit category that checks whether a site has an llms.txt file. This sits alongside other machine-readability signals like accessibility structure, layout stability, and WebMCP integration.
The twist is that this audit isn’t about SEO rankings, it’s about how well sites can be interpreted by AI agents and browsing tools. Still, the inclusion of llms.txt in Lighthouse has sparked confusion, especially given Google’s recent guidance stating it isn’t required for AI search.
Key Takeaway: Don’t overreact to llms.txt, but do pay attention to the direction of travel. Google is clearly prioritizing structured, accessible, machine-readable websites, even if no single file is currently required for search visibility.
5. Study Finds 90% of Brands Have Zero AI Search Mentions
Not showing up in AI search? You’re not alone. A new study found that 90% of brands aren’t appearing.
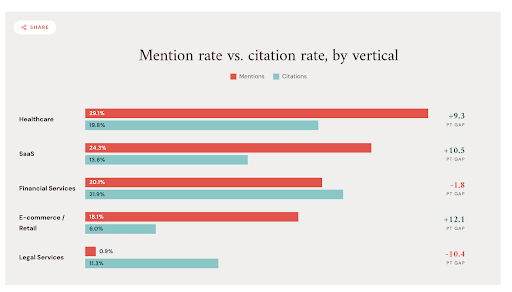
The study found that the most commonly mentioned industries included:
- Healthcare
- SaaS
- Financial Services
- E-commerce/Retail
- Legal Services
When analyzing the results, the study found that:
- ChatGPT tends to pull from Reddit, Wikipedia, and industry-specific publications
- Perplexity heavily favors news outlets and specialist publishers
- Gemini pulls from Google-indexed content
- Google AI Overviews mirror traditional organic signals and favor brand-owned content
- Microsoft Copilot surfaces LinkedIn, Microsoft-adjacent properties, and B2B publications
Click here to read more about this study and see how you can apply its findings to your own strategy.
6. Google Rolls Out May 2026 Core Update
Google has officially launched the May 2026 core update, marking the second major algorithm update of the year following March’s rollout. The company confirmed the update via its Search Status Dashboard and LinkedIn, noting that the rollout could take up to two weeks to fully complete.
Like previous core updates, this one introduces broad changes to how Google evaluates and ranks content across all types of websites. The goal remains consistent: improving the surfacing of content that is more relevant, helpful, and satisfying to searchers.
Google did not provide new recovery guidance specific to this update. Instead, it reiterated its standard position, that ranking drops don’t necessarily indicate issues with a site, and that no specific “fix” exists outside of improving overall content quality and usefulness.
Key Takeaway: Core updates aren’t about quick fixes, they’re about alignment. Sites that consistently focus on people-first, high-value content are the ones best positioned to stabilize and recover over time.
7. 92% of Consumers Use Social and Discovery Platforms for Product Info
According to a new Meta study, consumers are highly likely to make their next purchase on social media.

In the 16-page report, Meta noted that:
- 92% of people use social and discovery platforms for product information
- 58% find social media more enjoyable than traditional search for product discovery
- 63% buy faster when social media plays a role in their purchase decision
- 41% of Gen Z now turns to social media platforms first before traditional search
The study also shares that Google’s share of US search ad spending will fall below 50% by the end of 2026. However, online creators and UGC play a key role in the success of social media and in boosting consumer interest in your products.
Read more about this interesting study and determine how these findings impact your brand moving forward.
8. Meta Leans into AI Projects Among Layoffs
Meta has always been at the forefront of AI adoption, and now, it’s taking it one step further. This week, the social media giant cut 8,000 employees and reassigned 7,000 others to AI-based projects.
According to the New York Times, “Employees will be moved to four new organizations focused on building new AI tools and apps, Janelle Gale, Meta’s head of human resources, said in an internal memo. The organizations will use ‘AI native design structures’ and have fewer managers per employee than other parts of the company, she said, adding that company leaders will send details about the new roles on Wednesday.”
This comes on the heels of news that Meta is investing hundreds of billions of dollars into more AI development.
How this will affect marketers and brands advertising on Meta’s platforms remains to be seen, but a workforce switch-up this big is sure to have a ripple effect.
9. Google Adds AI Content Verification to Search
Want to know if images are AI-generated? Now you can figure it out, thanks to Google’s new AI Content Verification tool.
Google announced this week that it is adding SynthID to Search, Gemini, Chrome, Pixel, and Cloud. This comes three years after it was introduced to the general market.
Google is also adding verification for C2PA Content Credentials, which is the industry standard for recording how media was created and modified. That rollout will start with Gemini and come to Search and Chrome within the next few months.
10. YouTube Expands AI Creation Tools: Ask YouTube
YouTube added new AI creation tools to its platform this week.
One of the new tools, Ask YouTube, allows users to ask more complex questions. Once YouTube provides an interactive, structured response complete with links to the most relevant videos from across the entire platform, searchers can then ask follow-up questions.
This tool is currently available to YouTube Premium members 18 and older in the United States, but the platform expects to release it to all YouTube users in the coming months.
Another tool, Gemini Omni, makes it easier for creators to collaborate and build together. Using AI, creators can add prompts and images to other people’s videos, enabling collaboration without technical skills.
11. LinkedIn to Introduce Gated, Creator-Led Events
LinkedIn has been making moves toward the creator space for a while now. This week, news broke that the platform wants to host thousands of creator-led events a year.
According to Business Insider, LinkedIn’s Premium Events generated $18.9 million between the second half of 2025 and the first half of 2026. The goal is to host even more of those events in the coming months.
This is a big step, especially for brands and creators looking to grow on LinkedIn and cement their presence as a “LinkedIn Influencer.”
It’ll be interesting to see if these steps lead to monetized content and more engagement on the platform.
12. Pinterest Wants Brands to Start Thinking about the Holidays
We might have 31 weeks until Christmas, but Pinterest wants advertisers to start thinking about the holidays now.
In a new press release, the social media/search platform shared that now is the time to lay the foundation for a successful holiday season on the app. With 80 billion searches a month, Pinterest probably knows what it's talking about.
When preparing your holiday ad budget, Pinterest suggests thinking of it like this:
- 75% Always On – designate 3/4s of your budget to evergreen campaigns
- 15% Audience Growth – Use this amount to reach new and mid-funnel audiences
- 10% Peak Moments – Use this amount for short, high-impact bursts of traffic around key seasonal events like Black Friday
Click here for more tips on how to prepare for peak holiday season shopping now.
Weekly Homework
- A lot of news is coming out of the Google I/O conference, including the new search experience and the new Universal Cart. Stay up to date on all new tools and announcements so you can adjust your strategies accordingly.
- Read through Google’s updated documentation on AIO, GEO, and SEO.
- Download Meta’s report on social media marketing and use its insights to tweak your strategy.
- Check out the new YouTube creator and search tools to see how they could impact your content.
- Use Pinterest’s help to get started on your holiday marketing plan.
Digital Marketing News 5/9/2026 to 5/15/2026
This week: GA4 adds AI assistant tracking, Google drops FAQ rich results, and Gemini-powered Google Ads dashboards bring real-time AI reporting to advertisers . Plus, we cover why “vibe-coded” websites could quietly tank your SEO.
Here's what happened this week in digital marketing:
1. GA4 Just Added AI Assistant Traffic Tracking for ChatGPT, Gemini & Claude
Google Analytics 4 just introduced a new way to track traffic from AI assistants like ChatGPT, Gemini, and Claude.
GA4 now includes a dedicated “AI Assistant” channel in Default Channel Group reports, helping marketers measure how generative AI platforms are driving website traffic.
Google wrote, "Google Analytics now provides a dedicated way to measure and analyze traffic originating from popular AI assistants."
The update includes the following changes to your traffic source dimensions::
- Medium: A new "ai-assistant" value is automatically assigned when the referrer matches a recognized AI Assistant
- Channel Group: These visits are categorized under the "AI Assistant" channel
- Campaign: Traffic from these sources will be identified with the "(ai-assistant)" campaign name
This gives businesses clearer visibility into AI-driven traffic and how it compares to channels like organic search.
Key Takeaway: AI platforms are becoming an important discovery channel. With GA4 now tracking AI assistant traffic directly, marketers can better measure the impact of AI on search, content, and user acquisition.
2. FAQ Rich Results Are Dropped From Search
Google announced this week that it has removed FAQ rich results from Search.

Google didn't explain this change, but it shouldn’t come as much of a surprise, given that it had already limited them on most sites.
The search engine will depreciate the rich results in three phases:
- May 7, 2026: FAQ rich results stop appearing in search results
- June 2026: The FAQ search appearance filter, rich result report, and Rich Results Test support will be removed
- August 2026: FAQ rich results will be removed from the Search Console API
Next Steps: If you are using FAQ structured data, you don’t have to rush to remove it. Although it won’t help you with Google Search, it can sometimes be helpful for AI systems.
3. Vibe Coding Miss SEO Basics, Says Google
Thinking of building your website with an AI tool? You might want to pause.
In a recent episode of the Search Off the Record podcast, Google’s John Mueller and Martin Splitt said that building a site on AI, or “vibe coding,” is similar to working with a developer who doesn’t specialize in search.
While these sites might look cool, AI won’t set up your canonicals, sitemaps, or robots.txt, unless you specifically tell it to. Since these are things that most people who don’t specialize in search aren’t familiar with, they often get left off.
Leaving those SEO features off makes it harder for Google and other search engines to index and rank your site.
Bottom Line: AI is only as good as the prompts it receives. If you aren’t an SEO expert, skip vibe coding and work with a knowledgeable web developer.
4. Gemini-Powered Dashboards Provide Real-Time Insights for Google Ads
This week, Google announced that it’s bringing Gemini to the Google Ads dashboard.
Previously, users would have to manually set up and navigate their data reports. But now, using Gemini AI, advertisers can enter a prompt and receive up-to-date, real-time information in charts, graphs, and tables.
Google’s goal is to make data analysis more interactive, visual, and accessible. More information will be shared on May 20th at Google Marketing Live 2026.
5. 68% of PPC Professionals Use AI to Automate Repetitive Tasks
Ever wonder how your competition and colleagues are using AI? This new report from eMarketer will tell you!
The report asked PPC professionals at agencies around the world how they’re using AI in their work. Here’s what they found out:
- Automate repetitive tasks: 68%
- Upskilling team members to improve existing workflows: 64%
- Integrating it into advanced reporting, insights, and campaign performance: 63%
- Expanding services to offer AI-driven options: 34%
- Developing proprietary AI technology of their own: 27%
- No significant changes: 13%
How is your agency using AI?
6. Gmail & Yahoo Shift to "Interaction-Based" Inbox Placement
Google and Yahoo have officially moved beyond simple authentication as the primary deliverability factor. Reputation is now dictated by Positive Interaction Signals.
The Change: Inboxes now prioritize brands based on "Positive Reply Rates" and "Time-to-Open."
The Impact: Brands with high "skim-and-bin" rates (deleting without opening) are seeing a 20% decrease in primary inbox placement.
The Source: Google Sender Guidelines | Yahoo Sender Best Practices
The Report: Validity 2026 Email Deliverability Benchmark Report
7. Apple Mail "Intelligence" Now Summarizing Promotional Emails
Apple’s 2026 OS updates have replaced traditional snippet text with AI-generated summaries in the "Promotions" and "Updates" tabs.
- The Update: Instead of your subject line, users see a 10-word AI summary of the email's body.
- Optimization: Front-load your "Offer Hook" in the first 50 words to ensure the AI highlights your discount rather than generic introductory text.
- The Source: Apple Support: Use Apple Intelligence in Mail
- The Report: Litmus: The State of Email 2026 Edition
8. DMARC Enforcement Becomes Mandatory Under PCI DSS v4.0
DMARC is no longer a suggestion; it is now a security requirement for any organization handling digital payments or sensitive customer data.
- The Change: Under PCI DSS v4.0, failing to have a p=quarantine or p=reject policy can lead to transactional emails being blocked at the gateway level.
- The Impact: Organizations that haven't updated their DMARC policy from "p=none" (monitoring) are experiencing significant delivery failures in Outlook and Gmail.
- The Source: PCI Security Standards Council (PCI DSS v4.0)
- The Report: MimecasPCI Security Standards Councilt: 2026 Email Security Global Trends
9. LinkedIn and Amazon Ads Form a Partnership
Thanks to Amazon Ads, LinkedIn advertisers can now reach TV viewers.

According to Amazon, “For marketers already using Amazon DSP to plan, buy, and optimize full-funnel campaigns across streaming TV, display, online video, and audio, the solution adds previously unavailable LinkedIn targeting capabilities for CTV campaigns.”
In the announcement, LinkedIn shared, “LinkedIn’s CTV Ads reach B2B audiences 2.2x more effectively than other CTV platforms and 4.3x more effectively than linear TV.”
If you’ve been looking for a new way to reach B2B audiences, this partnership could be helpful.
10. YouTube Releases New Playbook for Brand Growth
If you’re looking to grow on YouTube, this is news you’ll want to hear. The video content platform recently published a new playbook to help businesses better understand the fundamentals of the YouTube creator marketplace and find success on the platform.

The guide mentions that:
- 78% of viewers said YouTube had the most trusted creators for product recommendations
- 40% of YouTube views happen more than 30 days after the video is posted
- The platform drives 86% higher long-term ROAS than paid social
- YouTube Shorts increases long-term brand growth by 21%
- Creator partnerships on boost Demand Gen campaigns deliver an average 20% increase in conversion lift
The playbook also explains how brands and creators can use the platform to find success.
If you’ve been thinking of jumping into YouTube or want to refresh your strategy, click here to download this valuable playbook.
11. TikTok Shoppers Love Affiliate Links
TikTok shopping is on the rise, and the app is telling brands to meet shoppers where they are – with affiliate links.
In an interview with Glossy Magazine, Donte Murray, TikTok’s director of beauty, wellness, and personal care, said that, “77% of interested shoppers on TikTok search for more info about a relevant product after seeing affiliate content in stream.” He encourages brands to combine sponsored and affiliate content to meet shoppers exactly where they’re searching.
He also shared that repeat purchases are often driven by tutorials and tip videos. So, if you want to grow your ecommerce business using TikTok Shop, offer affiliate links and post videos showing consumers how to use your products.
12. TikTok Launches Ad-Free Subscriptions in the UK
Tired of all the TikTok ads? If you’re in the UK, you can purchase a subscription to remove them from your feed.

In the announcement, Kris Boger, TikTok’s UK Managing Director, was quoted as saying, "Choice for our community and growth for UK businesses go hand in hand on TikTok. Advertising on our platform is already helping thousands of British businesses reach new customers, increase sales and create jobs, while our new ad-free option gives people greater control over their experience. Together, this ensures we continue to deliver real economic impact while giving our community the flexibility to engage with TikTok in the way that suits them."
This is currently only available in the UK, but it’ll be interesting to see how it affects the success of brands that have built up a following on the app. It’ll also be interesting to see if this subscription model ever makes its way across the pond to the United States.
13. Instagram Tests New Captions with Each Swipe on a Carousel
Instagram is testing a new feature: new captions for each post within a carousel.
Carousels are already among the most valuable posting options on Instagram, and now creators and brands can add even more content to them.
With this new upgrade, users can add a new caption with every swipe, switching up the copy for each slide. This feature isn’t available for everyone, though. It’s still in beta, with no word on when, or if, it’ll roll out to every user in the future.
14. Meta Introduces AI Chatbot to Threads
AI chatbots are coming to Threads. Meta just released its Muse Spark AI model for a trial rollout in Argentina, Malaysia, Mexico, Saudi Arabia, and Singapore.

According to Meta, the AI content will reach users' feeds one way or another, so why not have it done via Meta AI?
Users can have conversations with Muse Spark, talk to it via Voice Chat, and get help finding answers to their questions. They can also use image search to get more information on what they’re seeing in real time.
Meta has invested hundreds of billions of dollars into this project, but there is no word on when, or if, it’ll be released in the United States.
Weekly Homework
- Consider whether you want to keep your FAQ Rich Results schema on your site or remove it.
- If you have a vibecoded website, go back and add in the important SEO features.
- Check out the new Gemini-powered dashboard for your Google Ads.
- Download the YouTube playbook to see how you can find success on the video platform.
- If you’re trying to grow your ecommerce business on TikTok, consider offering affiliate codes and adding more tutorial videos to your content calendar.
- Trying to reach B2B audiences? Look into the new partnership between LinkedIn and Amazon Ads.
Digital Marketing News 5/2/2026 to 5/8/2026
This week: Google adds more links to AI search, ChatGPT ads show strong early engagement, and Etsy launches shopping directly inside ChatGPT.
Here's what happened this week in digital marketing:
1. Google Shares Insights on New Wave of Search Behaviors
Google’s Martin Splitt and Nikola Todorovic recently discussed a new wave of search behaviors – and what marketers can do to capitalize on it.
When discussing AI search, Split and Todorovic shared key insights into search behavior and how it’s changing. The most important insights?
- Search queries are becoming longer and more detailed
- Users are doing new things with search, instead of simply searching for keywords
The biggest takeaways from their discussion included:
- AI search is not new, but it is changing how people use Google.
- Keywords are not dead, but instead should be used within larger prompts.
- Classic Search still matters because it’s running in the background of AI Search.
- Users are getting more complex with their searches with longer, more detailed questions
- Content has to work for classic search, while remaining useful for more complex search behavior.
You can listen to the full discussion here.
2. More Links Are Added to Google’s AI Search
New updates are coming to Google’s AI Mode and AI Overviews – and it’s great news for marketers and brands.
Google is rolling out five AI updates, including changes to how links appear in responses. The updates include:
- Labeling links from users’ news subscriptions
- Suggesting links to articles at the end of AI responses
- Including previews from online discussions, social media, and other firsthand sources
- Inserting more inline links with responses
- Adding link hover previews on desktop
While we aren’t sure whether this will increase organic traffic, it’s nice that Google is linking back to its sources, giving brands an opportunity to grab some clicks from their content.
3. Google Wants Developers to Think About AI Agents
Google released new guidance to web developers this week: build for AI agents, too.
In the blog, Google shared that AI agents interpret websites three different ways:
- Screenshots: to identify elements visually
- Raw HTML: to give agents the DOM structure and hierarchy
- Accessibility Tree: the “high-fidelity map” of your interactive elements
To help AI agents better understand your site, Google suggests including agent-friendly semantic HTML elements like <button> and <a> over styled <div> elements. They also said to link <label> tags to inputs with the for attribute, and setting cursor: pointer on clickable elements.
To make sure your website is as agent-friendly as possible, read the entire blog here.
4. Some WordPress Sites Are Unintentionally Blocking AI Bots
If your SEO data looks good but you still aren’t seeing much movement with AI bots, it could be because your site is unintentionally blocking the crawlers.
In a new study, one researcher found that, while Google AI Mode and Copilot were monitoring and crawling their site, big names like Claude and Meta AI were not. Why? Because they were blocking them.
If you’re blocking things like Googlebot, GPTbot, and more, you’re essentially removing your ability to end up in AI search results. For the best chance, make sure your page is available to these bots.
If you aren’t sure whether your site is blocked, run a WP Engine diagnostic. It only takes a few minutes and it could reveal the cause of issues you’ve been dealing with for months.
Click here for full instructions on performing the diagnostic test and reading its data.
5. Ask.com Officially Shuts Down After Nearly 30 Years
Ask.com, formerly known as Ask Jeeves, officially shut down its search business on May 1, 2026, nearly 29 years after launching in 1996 before Google existed.

Ask Jeeves was one of the internet’s earliest “answer engines,” built around conversational questions long before AI search became mainstream.
Its shutdown highlights how difficult the search market has become as Google and AI-powered search experiences continue dominating the space.
6. Early ChatGPT Ad Data Shows Strong Engagement, but Scale Remains the Big Question
Early SimilarWeb data suggests ads inside ChatGPT conversations are generating higher engagement rates than traditional Display and Podcast ads, especially for high-intent searches like Mother’s Day.
Unlike traditional search ads, these placements appear naturally within conversational responses, making them feel more contextual and less disruptive.
Mother’s Day-related prompts reportedly triggered ads about three times more often than average, with brands like Etsy and Nordstrom already seeing strong visibility.
However, inventory is still limited and testing remains small-scale, making it too early to know whether current CTRs will hold long term.
High engagement also does not guarantee strong performance. Advertisers still need more data around conversions, scalability, and pricing before ChatGPT ads can seriously compete with platforms like Google Ads or Meta.
Key Takeaway: ChatGPT ads are showing promising early engagement, but marketers should treat the platform as a test channel until larger-scale performance data becomes available.
7. Etsy Launches ChatGPT App
Etsy shoppers will now be able to shop their favorite shops from within ChatGPT. Thanks to a native app within the AI bot, Etsy lovers can now access over 100 million listings and products.
In the announcement, Etsy shared that “[t]he Etsy app in ChatGPT is now live in beta, allowing users to search and compare Etsy items directly in conversation.”
Users simply need to tag @Etsy in their prompt, and the Etsy app will provide listings relevant to it.
This differs from ChatGPT Instant Checkout, and Etsy is the first ecommerce website to offer it.
Why We Care: If this beta test is successful, we could see more and more brands wanting to create a special app within ChatGPT, too. It could be a whole new arm of digital marketing and ecommerce.
8. Google Expands AI Bidding & Budgeting Tools to Reduce Manual Campaign Work
Google Ads is rolling out new AI-powered bidding and budgeting features designed to help advertisers capture more demand with less manual work.
The updates include:
- Journey-aware Bidding, which uses more customer journey data for optimization
- Smart Bidding Exploration, expanding beyond Search after reportedly driving a 27% increase in unique converting users
- Demand-led budget pacing, which automatically shifts spend toward higher-demand periods
Google says advertisers using campaign total budgets have already seen a 66% reduction in manual budget adjustments.
The goal is to help campaigns respond more dynamically to changing demand while reducing the need for constant bid and budget management.
Key Takeaway: Google is continuing to push advertisers toward AI-driven campaign management, with automation taking a larger role in bidding, budgeting, and demand discovery.
9. Google’s March Core Update Shifted Traffic and Visibility
Now that the dust is settling from Google’s March Core Update, data is revealing who was the most affected – YouTube, Reddit, and aggregators.
The analysis from Amsive found that:
- YouTube lost the most – 567 visibility points
- Reddit lost 64 points
- Instagram lost 48 points
- X lost 46 points
- Google seems to favor authoritative sources, especially in the travel, jobs, and health sectors
Although some sites, like Reddit and Indeed, saw a big bounce back, not all sites have recovered.
Keep an eye on your own analytics to see if your site has been affected by the big core update.
10. Reddit Wants to Help Grow Your Business
Reddit is quickly becoming a major player in the PPC scene, and this new report will help you capitalize on that growing audience.

After announcing that its ad revenue increased 74% YoY, Reddit released a 13-page guide designed to help brands connect with their preferred audience on the platform. Highlights include:
- The 5 types of people you’ll find on Reddit
- Trending topics and how they’re being discussed in different industries
- Insights on how business owners found their communities
- Case studies on how businesses converted Reddit fans into paying customers
- Ideas on how to create ads that Reddit users will enjoy
This report is a wealth of information for businesses already advertising on Reddit or even considering taking the plunge. You can download the full report for free here.
11. Instagram Starts Labeling AI-Generated Content
Instagram wants you to be able to trust what you see on its platform. That’s why it introduced AI Creator labels this week.
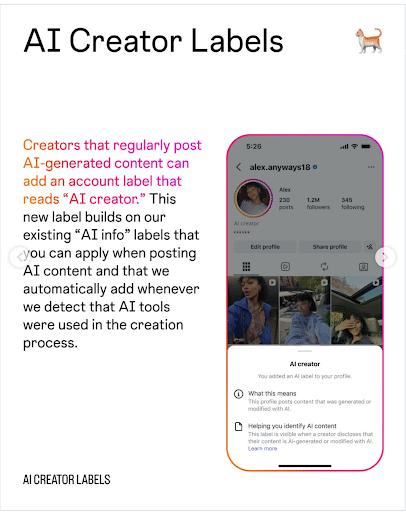
In the announcement, Instagram explained: “This new label builds on our existing ‘AI info’ labels that you can apply when posting AI content and that we automatically add whenever we detect that AI tools were used in the creation process. … In instances when content is labeled as ‘AI info’ and posted by a labeled AI creator, the ‘AI info’ label would appear on the content instead of the ‘AI creator’ label.”
This isn’t a push to stop creators from using AI. In fact, Meta is probably one of AI’s biggest fans. But it is a push to stop the erosion of trust caused by creators posting AI-generated content without telling people it’s AI.
Weekly Homework
- Explore Etsy’s new in-ChatGPT app to see if it could work for you.
- Audit your SEO strategy to ensure that you’re doing the most you can for Bing searchers.
- Talk to your web development team to ensure your site is built for both humans and AI agents.
- If you have a WordPress site, run a diagnostic test to ensure that you aren’t unintentionally blocking any crawlers.
- Download the Reddit report to learn how to advertise your business effectively on the open-forum platform.
- If you are in shopping or travel, explore the ways that Google Ad’s AI Max could improve your search ads.
Digital Marketing News 4/25/2026 to 5/1/2026
This week: Adobe acquires Semrush reshaping search visibility, AI Overviews cut organic clicks by 38%, and AI Overview CTR drops despite rising impressions.
Here's what happened this week in digital marketing:
1. Adobe Completes Semrush Acquisition, Signaling a New Era for Search and AI Visibility
Adobe has officially completed its acquisition of Semrush, marking a major shift in how brands approach search, content, and digital visibility.

The move brings together Semrush’s strength in search intelligence, like keyword data, competitive insights, and visibility tracking, with Adobe’s broader ecosystem of content, customer experience, and analytics tools. The bigger implication: discoverability is no longer a standalone function, it’s becoming fully integrated into the entire marketing lifecycle.
As AI-driven search and conversational interfaces reshape how users find and evaluate brands, the traditional path from search to website is changing. In many cases, users are getting answers, comparisons, and recommendations before ever clicking through, making visibility across AI platforms just as important as rankings in traditional search.
This acquisition reflects a broader industry shift toward what some are calling a multi-layered approach to visibility, combining traditional SEO with emerging strategies like generative engine optimization (GEO) and AI-driven discovery.
Key Takeaway: Search is no longer just about rankings, it’s about visibility across an entire ecosystem. Brands that connect content, data, and AI-driven discovery will be better positioned to win in the next phase of digital marketing.
2. Study Finds Google AI Overviews Reduce Organic Traffic By 38%
New research is shedding light on the real impact of Google’s AI Overviews, and the results could be a concern for marketers and publishers.
A randomized field experiment found that when AI Overviews appear in search results, organic clicks to external websites drop by 38%. At the same time, zero-click searches surged, with users increasingly getting answers directly on the results page instead of visiting other sites.
What’s particularly notable is that removing AI Overviews didn’t significantly change user satisfaction or perceived quality of results. In other words, users felt they were getting the same value, even without clicking through.
This reinforces a growing trend: search is becoming more self-contained, with AI summarizing information and reducing the need for users to leave the platform.
Key Takeaway: As AI-driven search continues to rise, marketers must adapt to a world where visibility, not just clicks, matters, and where being included in AI summaries may become just as important as ranking on page one.
3. Brand-cited AI Overview CTR Fell 61% in Q4
According to a new report from Seer Interactive, brand-cited AI overview CTR fell a whopping 61% from Q3 to Q4.
While clicks may have dropped, impressions more than doubled in the same category over the same time period. The numbers also revealed that:
- Being cited by AIO still delivers +120% for both paid and organic CTR
- There is a 6-7% advantage for a brand to be cited in an AIO for paid CTR
- If a brand is not cited, organic CTRs declined by 67%
The study also revealed that these are the types of queries most likely to return an AIO:
- Comparison (X vs Y): 95.4%
- Review Queries: 86.3%
- Question (Who/What/Where/How): 85.9%
- Price/Cost/Buy: 83.4%
You can learn more about AIOs and search queries by reading the entire report here.
4. Bing Hits 1 Billion Users as Microsoft Strengthens Search Growth

Microsoft has announced that Bing has surpassed 1 billion monthly active users for the first time, marking a major milestone in its ongoing push to grow its search ecosystem.
Alongside this growth, search advertising revenue increased by 12% year over year, continuing a streak of double-digit gains. Microsoft also pointed to steady expansion of its Edge browser, which has gained market share for 20 consecutive quarters, helping drive more users into the Bing ecosystem.
While Bing still holds a relatively small share of the global search market, the growth highlights increasing engagement and the impact of Microsoft’s broader strategy, including AI integration and default search positioning within Edge.
Key Takeaway: Bing’s growth signals expanding opportunities beyond Google. Marketers should consider diversifying their search strategies as alternative platforms continue to gain traction.
5. Google Expands AI Max Across Ads, Balancing Automation with Control
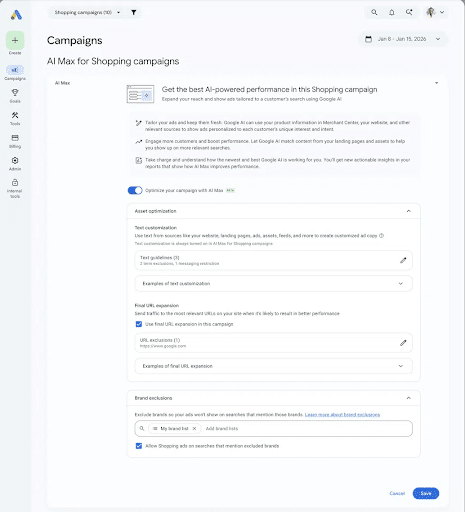
Google is continuing its push into AI-driven advertising by expanding AI Max across more campaign types, while introducing new tools to give advertisers greater control over how automation is applied.
AI Max is now rolling out beyond Search into Shopping and travel campaigns, allowing brands to reach users across more touchpoints, including conversational and exploratory queries that traditional keyword strategies often miss. For retailers, this means more adaptive ads powered by product data, while travel advertisers benefit from a more unified campaign structure.
At the same time, Google is addressing a key concern around automation: control. New features like “AI Brief” allow advertisers to guide messaging and targeting using natural language inputs, while updates to URL selection and compliance tools ensure campaigns remain aligned with brand and regulatory requirements.
Key Takeaway: As Google leans further into AI-driven advertising, success will depend on finding the right balance, leveraging automation for scale while maintaining enough control to protect brand messaging and performance.
6. New First-Party Shopper Data Comes to Google
Google is expanding its partnership with Albertsons Media Collective to enhance first-party shopper data on its apps.

In the agreement, Albertsons, a large food and drug retailer, will integrate its first-party shopper data directly into its Google and YouTube campaigns.
According to Google, “Unifying brand and shopper marketing in Display & Video 360 helps brands like Keurig Dr Pepper seamlessly optimize every dollar, managing commerce media with the same accountability and performance as their broader marketing strategy. By connecting Albertsons Companies’ data with the reach of YouTube and intelligence of Google AI, brands can drive ROI across the entire shopper journey.”
Since Google and YouTube play such a large role in most customer journeys, access to better first-party consumer data could be the key to boosting retailers' bottom lines as they reach new audiences.
7. WooCommerce Stores Can Now Sell Via YouTube Videos
Google and WooCommerce have partnered to enable WooCommerce stores to sell products through YouTube videos.
In the announcement, WooCommerce was quoted as saying, “Google for WooCommerce makes it simple to reach 2.7 billion shoppers on YouTube and automate your creative with AI.
YouTube Shopping is now a direct sales channel for WooCommerce stores. As search and discovery undergo a massive evolution, brands need to show up where their audiences are researching and buying. YouTube is the world’s second-largest search engine and the largest platform for researching products via video.”
The partnership allows WooCommerce users to connect their store to their YouTube channel using an extension and tag products in their YouTube videos and Shorts. Once tagged, those products will appear as shoppable cards while viewers are watching the videos and in the Channel Shopping tab.
It adds YouTube to the long list of places WooCommerce users can sell their products, including Display Ads, Gmail, Discover, Search, and Google Maps.
The announcement also shared that users will be able to access AI-powered ad creative across all Google channels, as well as Performance Max for service businesses.
If you are a WooCommerce user, this new partnership is definitely worth checking out.
8. LinkedIn Opens Event Ads to External Platforms
LinkedIn is introducing Off-Platform Event Ads, giving marketers more flexibility to promote events while driving registrations directly to their own websites.
Instead of relying on LinkedIn’s native Event Pages, advertisers can now link Event Ads to external destinations, like webinar platforms, landing pages, or livestream sites, while still leveraging LinkedIn’s targeting capabilities. The result is a more streamlined, controlled user journey from discovery to registration.
This shift reflects a broader move toward giving marketers greater ownership over their data and conversion experience, without sacrificing the reach and precision of LinkedIn’s ad ecosystem.
Action Item: Test Off-Platform Event Ads to improve registration flow and data ownership, especially if you’re currently relying on third-party platforms or want more control over the end-to-end user experience.
9. TikTok Creators Can Now Add Relevant Keywords to Metadata
TikTok now lets creators manually manage the keywords assigned to their videos, giving you more control over how your content gets discovered in search.
This update lets you suggest relevant terms or block those that don’t fit. For digital marketers, this is a low-key big deal: it's essentially SEO for TikTok, and it means you can actively guide the algorithm instead of just hoping it figures out what your content is about. Pair this with TikTok Trends to research what terms your audience is actually searching, and you've got a solid one-two punch for maximizing reach.
Just don't get too keyword-happy. TikTok still holds the final say on what sticks.
10. Instagram Improves Post and Reels Insights and Metrics
It’s been a busy week over at Meta. Instagram also announced some big updates to its content metrics, specifically for posts and Reels.
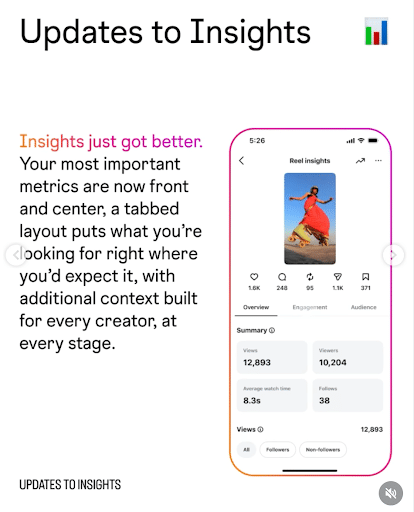
The update makes it easier for users to find key metrics, including engagement activity and audience demographics. It also added more insights, including share and skip rate percentage, which have become increasingly more important to brands and creators.
Unfortunately, the update does not include other important information, such as data on collab posts, trial reels, cross-posted content, and boosted content.
The update is Meta’s latest effort to keep creators and brands happy on the platform, which has seen a slight decline in the past few months.
11. Meta Launches New Social Platform: Instants
There’s a new app in the Meta neighborhood: Instants.
The app, which was designed as a spin-off of Instagram, gives off Snapchat vibes. Users can share photos with friends that will quickly disappear. Those photos can also be shared directly to Instagram.
Instants isn’t the first time Meta has tried to replicate Snapchat. It follows a long line of other attempts, including Stories, which is now a major part of Instagram, Poke and Slingshot, which were both shut down in 2014, and Quick Updates on Facebook, which also had a very short shelf-life.
Whether Instants becomes a big hit remains to be seen, but it’s still important for marketers to keep an eye on potential new platforms.
12. New Advertising Opportunity: AI Sponsored Snaps
Snapchat launched a new kind of ad this week: AI Sponsored Snaps.
Building on the success of Sponsored Snaps, this new tool lets brands pair their ads with AI chatbots to create a more personalized connection with their audience.
The new chatbots will connect with consumers, driving full-funnel outcomes from the top of the discovery funnel through the end of the process. Snapchatters can use the AI bots to ask questions, get personalized recommendations and feedback, and explore what the brand has to offer.
The opportunity is kicking off with Experian, and if successful, will expand to other brands in the future.
13. “Ask YouTube”: Google’s Newest AI Experiment
Google is testing a new conversational search feature called “Ask YouTube.”
The tool allows searchers to ask YouTube a specific question and receive an AI-generated summary with cited videos and follow-up questions. The source videos are embedded in the responses, with links that open to timestamped sections.
The tool is currently available to US Premium subscribers who are 18 years of age or older and accessing Google on a desktop from now until June 8th.
14. OpenAI Crawl Activity Has Tripled
Since the August 2025 launch of GPT-5, OpenAI crawl activity has doubled.
This means OAI-Search Bot is now generating more traffic than its training crawler, GPTBot. This matters for digital marketers because it means that ChatGPT is increasingly pulling live web content to answer user queries, making your site's crawlability and AI visibility more critical than ever.
And here's the kicker: if you've only blocked GPTBot, thinking you're opting out of OpenAI's reach, you're still fully exposed to OAI-SearchBot, the bot that actually determines whether your content shows up in ChatGPT search answers.
If you’re measuring bot crawls, you need to be separating AI training crawls and AI search crawls to get the most accurate data.
15. Pinterest Forms CTV Partnership
Pinterest is jumping into the connected TV game. This week, Pinterest announced that advertisers can now expand their campaigns to consumers’ home TVs through a CTV partnership with tvScientific.

In the press release, Pinterest explained that, “tvScientific by Pinterest is the first ad platform to offer direct access to Pinterest’s high-intent audiences for CTV campaigns. Advertisers can use Pinterest’s commercial intent signals to reach audiences across premium inventory on the biggest screen in the house, while also leveraging tvScientific’s AI-powered optimization technology.”
With CTV ad spend reaching over $32 billion last year, it’s quickly becoming a major player in the digital marketing space. Making it more accessible to more brands through partnerships like this could open many doors, especially for small- to mid-sized businesses that may have been priced out of this opportunity in the past.
Weekly Homework
- Explore how to connect your WooCommerce store to your YouTube channel to create shoppable product cards that let consumers shop your site directly from your YouTube videos.
- Download Seer Interactive’s report on Google’s AIOs to see how you can improve your chances of benefiting from appearing in AIOs.
- Check out Pinterest’s new partnership with tvScientific to see if a CTV campaign might be in the cards for your brand soon.
- Add keywords to your TikTok metadata to see if it helps you increase your reach.
- Keep an eye on AI Sponsored Snaps. If this new ad type takes off, it could be a very lucrative way to interact with your consumers in a more personal way.
Digital Marketing News 4/18/2026 to 4/24/2026
This week: ChatGPT launches CPC ads and Ads Manager, AI search referrals surge with AEO impact, Google upgrades Demand Gen with view-through conversions.
Here's what happened this week in digital marketing:
1. CPC Bidding Comes to ChatGPT
Advertisers can now advertise on ChatGPT by bidding by click, not just by impression.
In ChatGPT’s initial advertising pilot, advertisers would have to pay a flat rate per 1,000 impressions served – regardless of who clicked. Now, some advertisers are being offered the opportunity to bid per click. The price seems to range from $3 to $5.
Important to Know: This is only available to a select group of advertisers, but with OpenAI hiring its first advertising marketing science leader soon, we can expect ChatGPT Ads to continue to expand.
2. ChatGPT Tests New Ads Manager, Signaling Push Toward Scalable Ad Platform
OpenAI appears to be taking a major step forward in its advertising capabilities, with early tests of a new ChatGPT Ads Manager interface now surfacing among marketers.
The new dashboard is designed to give advertisers real-time control over campaigns—allowing them to launch, monitor, and optimize performance more efficiently. This marks a significant upgrade from the platform’s earlier, more limited reporting setup, which relied heavily on basic data exports.
At the same time, more brands are beginning to appear within ChatGPT, indicating a growing ad inventory and a clear move toward monetization at scale. The introduction of a dedicated Ads Manager suggests OpenAI is building toward a more mature, self-serve ecosystem similar to platforms like Google Ads and Meta.
While still in early stages, the evolution points to upcoming improvements in targeting, reporting, and automation, areas that will be critical for broader advertiser adoption.
Key Takeaway: ChatGPT is quickly evolving into a more robust advertising platform—marketers should start paying attention now as self-serve tools and ad capabilities continue to expand.
3. Study Reveals AI-crawled Sites Generate 320% More Human Traffic
A new study by Duda provides a clear view of how AI crawler activity is growing and what businesses need to do to get noticed.
The study analyzed over 858,000 sites to understand exactly how AI crawlers operate. They found these referral patterns:
- Total LLM referrals: 93,484 to 161,469 (+72.7%)
- ChatGPT: 81,652 to 136,095 (+66.7%)
- Claude: 106 to 2,488 (23x growth)
- Copilot: 22 to 9,560 (from near-zero)
- Perplexity: 11,533 to 13,157 (+14.1%)
Additionally, they revealed that crawlers are no longer just indexing, but also happening in response to real-time user queries, such as:
- User Fetch (real-time answers): 56.9% of all crawler activity, driven almost entirely by ChatGPT
- Training (model learning): 28.8%, split across GPTBot and other model crawlers
- Discovery (content indexing): 14.3%, distributed across multiple systems
- ChatGPT User Fetch volume: ~39.8 million visits
You can read the entire report here.
4. Yelp Introduces New AI Assistant
Yelp is a big player in the local SEO game – and it just got better.
In a conversation with TechCrunch, Yelp’s SVP of product, Akhil Kuduvalli Ramesh, said: “We would really like consumers to reconceive Yelp as a place where they can ask questions and get answers, not just that, but also complete the action. That’s Yelp reconceiving from a review platform to an answers and action platform. Some of the investments we’re making will be in that lane.”
The goal of this update and the others coming this year is to make the app more user-friendly. This new AI upgrade will help searchers:
- Ask questions
- Get restaurant reservations
- Order food for delivery
- Book service professionals
Yelp has always been a big deal in local SEO, but with these updates, more and more consumers will be turning to the app for recommendations on all kinds of things. If your business doesn’t have an updated Yelp page, you risk losing out on that traffic.
5. Google Upgrades Demand Gen to Accelerate YouTube Conversions
Google is expanding its Demand Gen capabilities with new features designed to drive faster conversions, especially across YouTube’s growing performance ecosystem.
The update integrates Demand Gen into Google’s Commerce Media Suite, allowing advertisers to leverage retailer first-party data, including product catalogs and conversion signals. This enables more precise targeting of high-intent shoppers across YouTube, Discover, and Gmail.
In addition, Google is introducing view-through conversion optimization, which prioritizes conversions that happen after a user sees an ad, not just clicks it. This shift reflects a broader move toward measuring impact in more passive, discovery-driven environments where users may not take immediate action.
Key Takeaway: As platforms like YouTube evolve into full-funnel channels, marketers should start optimizing beyond clicks, leveraging first-party data and view-based attribution to capture high-intent audiences more effectively.
6. Video Content is Coming to Google Local Ads
The video content trend is expanding to Google Local Ads.
Video ads have been spotted within the local map pack. Instead of sticking to static listings or text-based ads, some advertisers are being given the opportunity to add more engaging video content.
Still in beta testing, the feature is only available to select advertisers in certain locations. You can check if you’re eligible by signing into your Google Ads dashboard and navigating to the Google Ads’ Location Manager.
7. Google Publishes Best Practices for Read More Links
Google started adding “Read More” links in search result snippets within Google Search. Now, advertisers and digital marketers have some guidance on how to process that information.
Google published the best practices on its blog, noting three main ideas:
- Make your content immediately visible on the page, not hidden behind an expandable section or interface.
- Avoid using JavaScript to control the scroll position on the page.
- Don’t remove the hash fragment from the URL if you have history API calls or window.location.hash modifications on page load.
Why We Care: The “Read More” button is another opportunity to draw more eyes to your content. Make sure you follow the best practices to set yourself up for success.
8. Social & Video Growing More Quickly than Search Ads
A new study by PwC revealed that, while search ads are still king, they aren’t growing as quickly as social media and video posts.
The report revealed that:
- Digital advertising revenue reached $294 billion, a 13% increase from last year
- Search saw an 11% increase
- Social media saw a 32% increase to $29 billion
- Digital video grew to $78 billion, a 25% increase
Even though social and video are growing at a faster pace, digital advertising and search ads are clearly still bringing in the most advertising revenue.
9. 76% of Pinterest CPG Promotions Achieved an ROI of 1.5x or Higher
Pinterest is quickly becoming the place to be for CPG brands that want to build awareness and drive a measurable sales impact.
A new report from the social media/search platform revealed that:
- 82% of campaigns generated a positive ROI
- 76% achieved an ROI of 1.5x or higher
- 83% achieved either ROI or sales uplift
In the report, Pinterest said: “In everyday terms: if you put $1 into these Pinterest campaigns, most brands got back more than $1, and many got $1.50 or more. That’s awareness translating into measurable business results.”
To make the most of the platform, Pinterest suggests:
- Plan around real CPG activities, not just audiences.
- Make it easy to move from inspiration to action.
- Use measurement to move Pinterest from test budget to core investment
10. Threads Introduces Live Chats
Threads is adding a new feature to make it easier to get your content out to more people at once.
Similar to Instagram’s Broadcast Channels, Thread’s new Live Chats will allow a Threads user to deliver updates and behind-the-scenes content directly to a large number of people at once.
– and in real time.
This announcement was made at Coachella, where Threads Chief Connor Hayes said: Those that are out here on Threads know that we want to be this real-time conversation for what’s going on in the world, but sometimes, posting to feed fifty times over the course of an hour just doesn’t do what it needs to do for live conversation … In the future, [users] will be able to start a live chat, add a few other collaborators … who can send messages into it, and then people can subscribe and follow along and interact with it without actually being able to send themselves. So it’s like the group chat from your messaging app that your fans can follow along with.”
If you’re a brand that has been looking to grow on Threads, this new feature may help you reach those goals.
11. TikTok’s US Venture Gains Security Infrastructure Certification
Since TikTok’s US venture was announced, users have been worried about the security of their data. In a recent press release, the US-based arm of the social media app announced that it has gained an important infrastructure certification.

In the announcement, TikTok USDS Joint Venture shared that it has secured its ISO/IEC 27001:2022 certification. This means that its infrastructure meets global benchmarks.
TikTok USDS JV can now be trusted to have:
- Organizational controls: Defined governance, policies, and strategies for how security is managed across the company, including asset management, threat intelligence, and vendor relationships.
- People controls: Demonstration of a security-first culture among employees.
- Physical controls: Security of tangible assets like offices and servers from unauthorized access or environmental damage.
- Technological controls: Safeguards protecting digital information and systems, including vulnerability management, encryption protocols, secure coding standards, and data leakage prevention.
Why We Care: Even though the TikTok ban was stressful for many businesses and marketers, it appears TikTok is taking the steps necessary to regain the public’s trust and maintain its place in the American social media hierarchy.
12. YouTube Tops Charts for Kids
A new report from Precisify, YouTube is where kids go to watch their favorite creators.
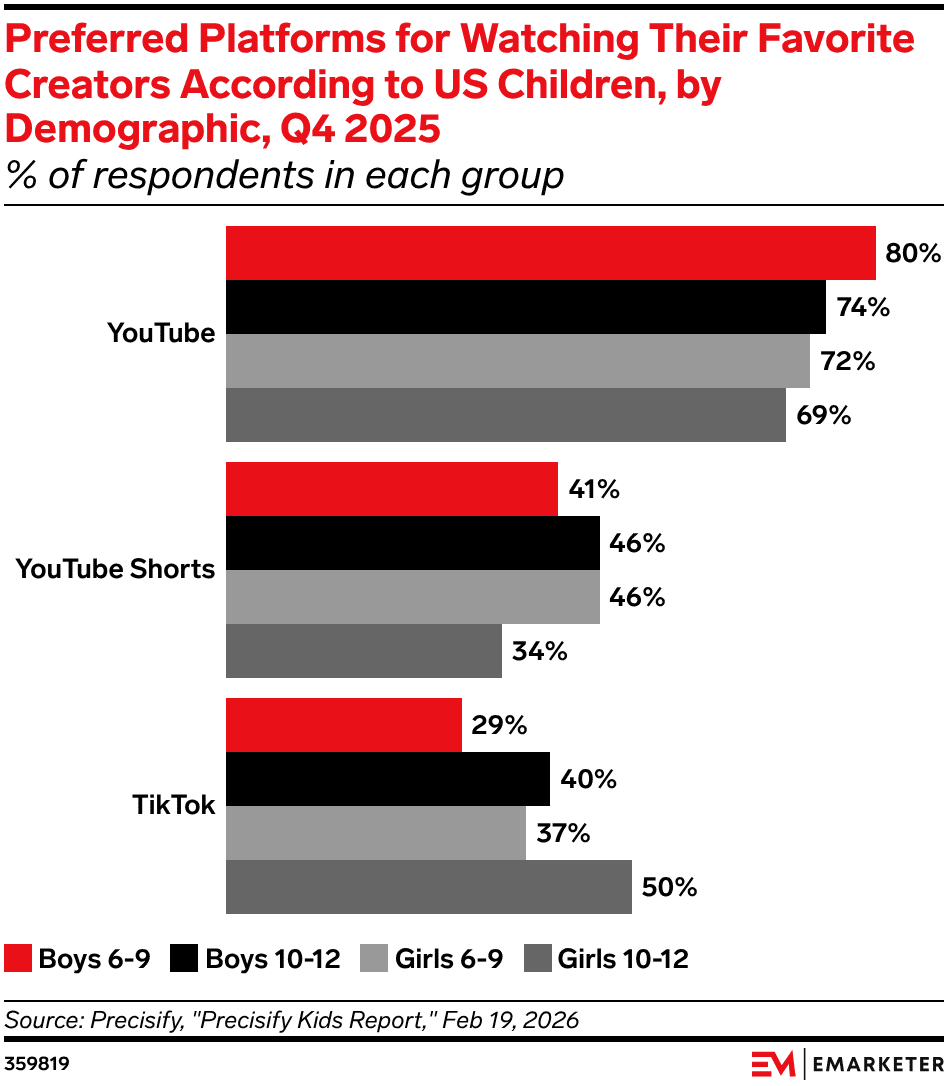
The study revealed that YouTube is a hit for:
- 80% of boys aged 6-9
- 74% of boys aged 10-12
- 72% of girls aged 6-9
- 69% of girls aged 10-12
YouTube Shorts and TikTok also have sizable audiences of child viewers. The only demographic to cross the 50% benchmark was TikTok among girls aged 10-12.
Why We Care: If you’re a kid-based brand, you might want to consider getting more involved with YouTube, since that’s where your audience is spending the most time.
Weekly Homework
- With the new AI-based updates to Yelp, take the time now to breathe some new life into your Yelp profile to enhance your local SEO strategy.
- If you (or your audience!) love CPG content, consider whether or not Pinterest could improve your reach and introduce you to new audiences.
- ChatGPT Ads are coming closer to the everyday marketer. Now is the time to decide whether this is an avenue you want to explore.
- If you are a kid-focused brand, explore ways to improve your YouTube strategy to help you land in front of the right kids.
- Give yourself an advantage and read Google’s new Best Practices documentation on the “Read More” link.
Digital Marketing News 4/11/2026 to 4/17/2026
This week: Google retires Dynamic Search Ads, Google Ads glitch disrupts campaigns, and TikTok expands AI ad creation.
Here's what happened this week in digital marketing:
1. Google Dynamic Search Ads Will Retire in September
If you’re using Google Dynamic Search Ads, you’re going to need to find another way to advertise on Google.
Google announced this week that it is retiring the legacy Search automation tools, including Dynamic Search Ads (DSA). They are doing this in favor of AI Max, an AI-powered campaign tool.
Here’s what Google said in the announcement:
- Starting in September, eligible campaigns using DSA, ACA, or campaign-level broad match will be automatically migrated to AI Max.
- Google will stop allowing advertisers to create new DSA campaigns through Google Ads, Ads Editor, and the Ads API once automatic upgrades begin.
- The company expects all eligible migrations to be completed by the end of September.
If you are a DSA user, you can continue running ads as normal until September, or you can voluntarily upgrade now. Google will be rolling out tools this week to help make it easier to move campaign history, settings, and data into AI Max. Advertisers will also start to see in-platform prompts about the upcoming move.
If you choose to wait until September, ACA campaigns will be automatically moved into AI Max with search term matching and text customization turned on by default.
If you want the most control over your ads, content, and data, start the migration process now.
2. Google Ads Glitch Triggers Mass Disapprovals
Advertisers are raising concerns after a wave of unexpected Google Ads disapprovals disrupted campaigns, despite no apparent issues with their websites.

Reports indicate that ads were flagged for DNS and server (500) errors, even when landing pages were functioning normally. In some cases, advertisers saw hundreds, or even thousands, of ads disapproved at once, causing sudden drops in traffic, leads, and revenue.
The issue appears to stem from Google’s automated review system. If its crawlers encounter temporary errors, like timeouts or DNS lookup failures, ads can be flagged under the “destination not working” policy, regardless of whether users are actually experiencing problems.
This highlights a growing challenge for marketers: performance isn’t just driven by strategy anymore, platform reliability plays a major role. When systems misfire, the impact can be immediate and costly.
Action Item: Proactively monitor your Google Ads accounts for disapprovals, regularly test landing pages across environments, and be ready to escalate or appeal quickly if issues appear to be platform-related.
3. OpenAI’s Ads Manager is Here – And It Needs Work
OpenAI is still testing its ads manager, but results haven’t been great yet.
Right now, the ads manager looks very similar to Google’s Ads Manager. However:
- Advertisers can only pay per impression
- Cost-per-click and cost-per-acquisition models are listed as “coming soon”
- Audience targeting is very basic and can only be refined by keywords, free-text hints, or country
- There is no demographic targeting or audience buying tools
- Reporting only consists of impressions and click graphics
- Audience size estimates and optimization tools are nowhere to be found
Basically, OpenAI may offer ads, but they seem to be generally out of reach for most digital marketers, especially those who value CPC and CPA ads.
4. Study Reveals 5 Characteristics That Show Whether Your Site Will Gain Organic Traffic
A recent study identified five key characteristics of sites that gain or lose organic traffic.
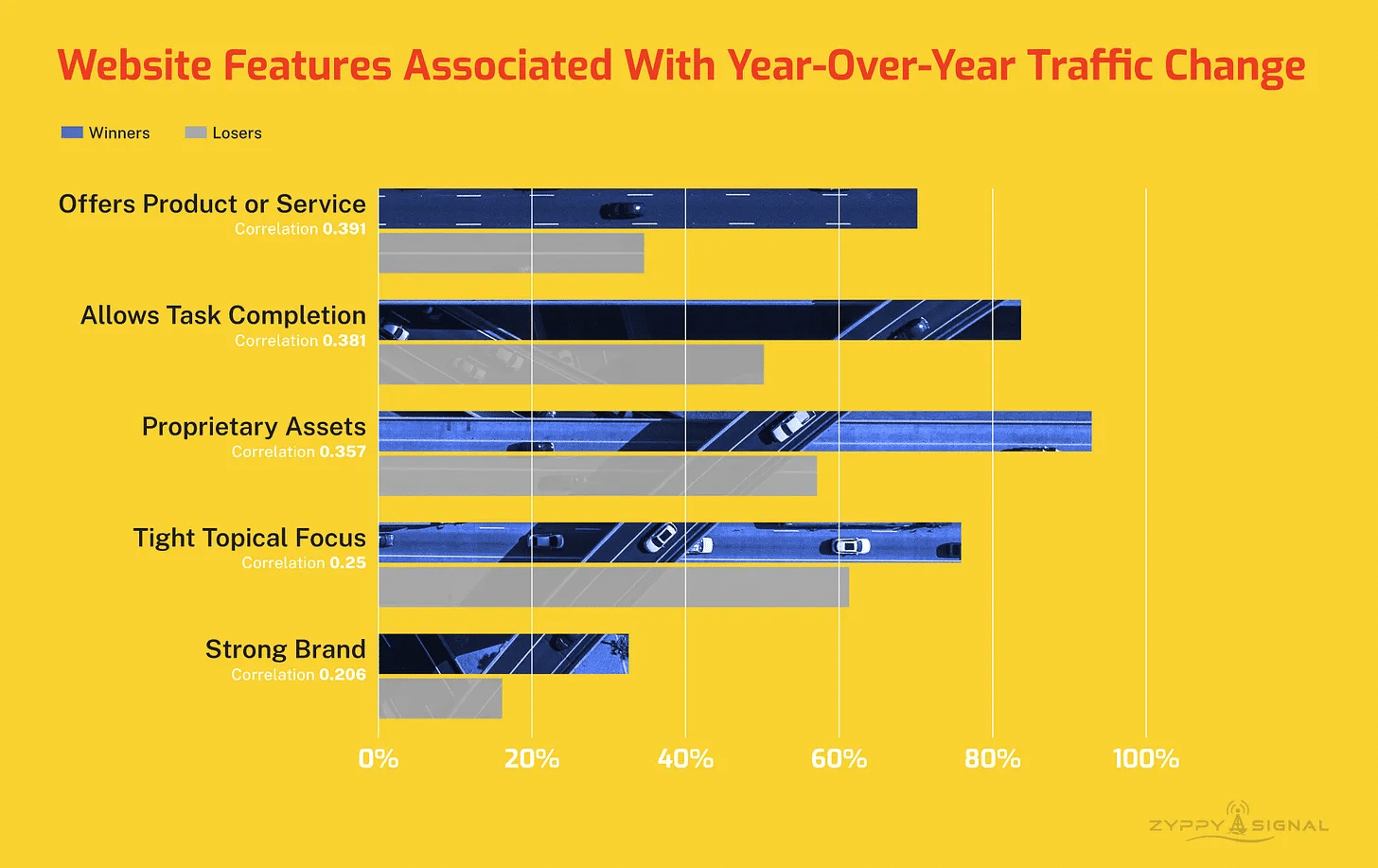
According to the findings, a site has a higher chance of winning organic traffic if it:
- Offers a product or service (+70%)
- Allows task completion (+83%)
- Offers proprietary assets such as unique datasets, user-generated content, or specialized software: (+92%)
- Has a tight topical focus: (less than +80%)
- Has a strong brand: (+32%)
What This Means: The best way to win more traffic is to post unique content, offer a product or service, or use your content to solve a problem or help your searcher complete their task.
5. Google Shares How It Picks One URL Over Another
In a recent Reddit chat, Google’s John Mueller explained how the platform picks canonical URLs.
He cited the following nine reasons:
- Exact duplicate content
- Substantial duplication in main content, such as the same article appearing in multiple places
- Too little unique content relative to template content
- URL parameter patterns inferred as duplicates
- Mobile version vs. desktop version
- Googlebot-visible version, not necessarily what users see
- Serving Googlebot alternative or non-content pages
- Failure to render JavaScript content
- Ambiguity or misclassification in the system
Bottom Line: The system is built on overlapping signals, so the best way to stand out is to produce authentic, helpful, and accurate content that you don’t post in a zillion different places.
6. 84% of Europeans Don’t Trust Their Data with US-Based Companies
A new survey published in Social Media Today revealed that the vast majority of Europeans do not trust US and Chinese-based companies with their data.
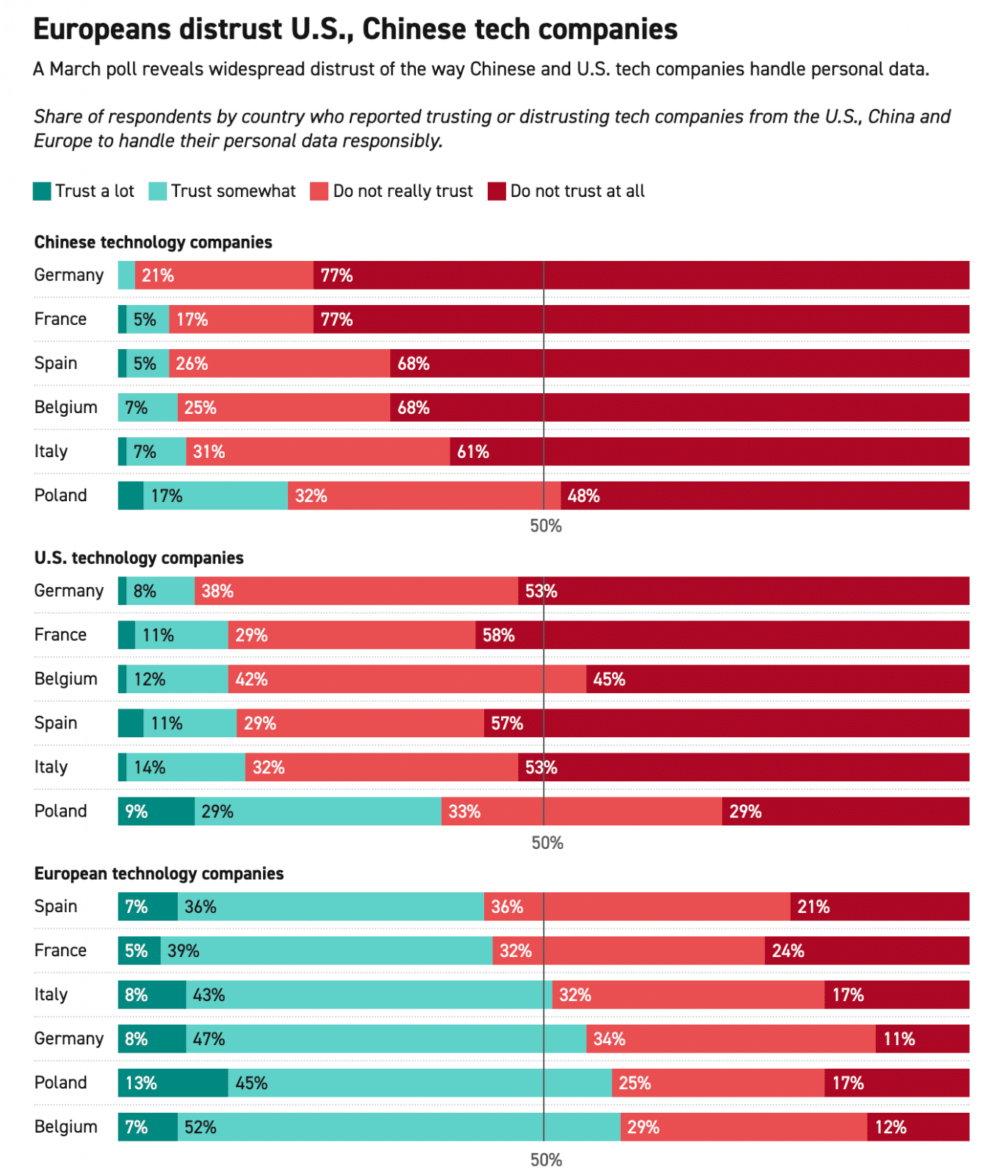
The survey found that 84% of Europeans don’t trust their data with US-based companies, and 93% don’t trust it with Chinese-based companies. The most untrusting? Users in Germany.
Europeans across the board view European companies as significantly more trustworthy. This could be due to the EU Commission’s ongoing efforts to regulate data protection and give EU users more control over who does what with their data.
Why This Matters: Reputations like this in one industry can eventually affect all US and Chinese-based companies across industries. This distrust could spread from tech companies to other industries, hurting the bottom line of brands across the board.
7. Google Simplifies Analytics and Ads Consent Rules
Big changes are coming to Google in June.
Starting on June 15th, Google Ads data collection will rely on the ad_storage consent setting when showing ads. This removes a layer of complexity that most marketers didn’t enjoy.
As of now, the ad data that flows between Analytics and Ads is influenced by Consent Mode and Google Signals outside of Google Analytics. This causes some confusion, especially for marketers who didn’t love that their controls were buried in Analytics settings rather than being readily available.
How to Prepare: While you have a bit of time before the removal, you should audit your consent implementation now, well before the June 15th deadline. Clearer rules are coming, but it makes getting consent more important than ever.
8. Increase Your Reach on X with These Tips
X’s Head of Product, Nikita Bier, recently offered some tips that brands, marketers, and creators might want to pay attention to.
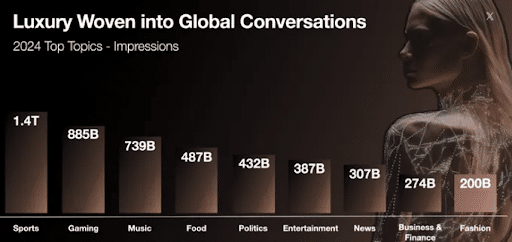
Although X, formerly known as Twitter, has had its share of issues as of late, people are still turning to the app for information on sports, gaming, music, and food.
If you’re in those industries and want to use the app to expand your reach, Bier suggests:
- Posting less links
- Sharing more content in-stream
- Add keywords like “Breaking” or Breaking News” (but only if it’s actually breaking. X will be cracking down on ragebait posters who take advantage of this)
- Don’t repost clips from other platforms, such as videos with a TikTok watermark
9. TikTok Adds New AI Video Generation to Ad Tool Kit
More AI tools are coming to TikTok! ByteDance introduced the latest Seedance 2.0 video generation model into the creator toolkit this week.
In the announcement, TikTok explained: “The model improves the consistency of products throughout content, so they remain recognizable across video segments with fewer manual corrections. Motion is also more natural, with smoother movement throughout. Together, these improvements mean less time spent fixing outputs and more time scaling your campaigns.”
If you’ve been producing TikTok ads, this could be a tool worth checking out.
10. YouTube Offers New Engagement Options
If your brand is big on going live on YouTube, pay attention to these new engagement options.
The new options include:
- Encouraging fans to send gifts on horizontal live streams
- Access to gifts in countries that previously did not have access, such as Canada, Korea, Indonesia, Thailand, Australia, and New Zealand
- Updates to the personal ad-free window after a fan shows support
- Live chat engagement
- Customizable streaming for all devices, including horizontal and vertical at the same time
More and more people are turning to YouTube Live for entertainment so the more ways to engage with your audience, the better.
11. Google Ads AI Skills to Chrome to Save Favorite Workflows
More AI tools are coming to Google’s popular Chrome browser.
This week, Google announced the launch of Skills in Chrome. This tool lets you create your own one-click workflows and prompts. Google says this will be helpful in situations such as:
- Health & Wellness: quickly calculating protein macros for any recipe
- Shopping: generating side-by-side spec comparisons across multiple tabs
- Productivity: scanning lengthy documents for important information
Google is also launching a library of ready-to-use Skills that contain prompts for common tasks and workflows.
Skills can be saved anywhere you’re signed in on a Chrome desktop device.
Weekly Homework:
- If you’re a Google Dynamic Search Ads user, start making plans to switch up your strategy before DSA ads are discontinued in September.
- Make browsing and researching easier by creating your own prompts in Skills on your Chrome browser.
- Review the five characteristics that could increase your organic traffic and decide how to use this knowledge to improve your website and increase your traffic.
- Check out the new TikTok Ads AI tools to see if it could improve your ad creation.
- Get familiar with Google’s Ad consent rules before it all switches up on June 15th
Digital Marketing News 4/4/2026 to 4/10/2026
This week: ChatGPT traffic flows to Google, AI ads drive major sales lift, and YouTube tests long unskippable ads.
Here's what happened this week in digital marketing:
1. 1 in 5 ChatGPT Clicks Go to Google
A new study found that 20% of ChatGPT’s referral traffic goes directly back to Google. When the study started in 2024, only about 14% went to Google. By January 2026, when the study ended, that number was over 21%.
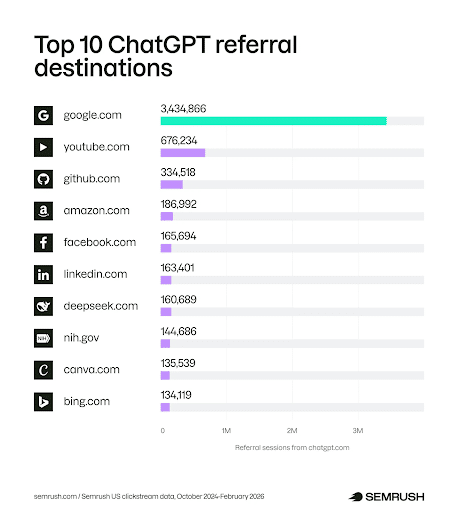
In addition to revealing that 30% of the traffic flows to just 10 domains (and 20% of that traffic is going straight to Google), the study also revealed surprising information about searcher’s habits, such as:
- 65-85% of ChatGPT prompts are conversational in language
- Most ChatGPT prompts don’t match traditional search prompts
- The majority of prompts are navigational in nature and then transactional. With the smallest percentage of prompts being informational or commercial.
If you want to improve your AI visibility and get your content found by AI chatbots, like ChatGPT, check out this study and use the data to restructure your content.
2. Some Brands Seeing Up to 80% Sales Lift from AI Ads
Google revealed this week that some brands are seeing up to 80% sales lift from using its AI-powered advertising tools.
The numbers reveal that AI chatbots, like ChatGPT, aren’t disrupting Google’s core search business as much as previously expected. In fact, it’s just the opposite:
- Alphabet Inc. surpassed $400 billion in revenue in 2025
- Q4 ad revenue was up 13.5% YoY to $82.28 billion
- YouTube Ads were up 9% YoY to $11.38 billion
Why We Care: Not only are these impressive sales lift numbers, but they also show that Google is still king when it comes to reach and brand awareness. To improve your chatbot visibility, focus on improving your visibility with Google. It’s all tied together.
3. Google March 2026 Core Update Now Complete
We shared last week that Google started its March 2026 Core Update. We can now confirm that the rollout is complete.
The rollout took 12 days and 4 hours, and Google did not release any new guidance on managing the fallout.
Pro Tip: Access your analytics dashboard to see how your site fared. Analyze your ranking and traffic changes, identify which parts of your site took the biggest hit, and adjust your content strategy accordingly.
4. Google Fixing Search Console Bug That Inflated Impressions
If you see a sudden dip in your Search Console data over the next few weeks, don’t panic, you probably didn't lose traffic; you just stopped "hallucinating" it.
Google has confirmed a long-running logging error that has been inflating impression counts since May 13, 2025. The company is now rolling out a fix to bring those numbers back down to reality.
The Details:
- The Glitch: A reporting error caused Search Console to over-report how many times your site appeared in search results.
- What’s Affected: Only Impressions are impacted. Google clarified that Clicks and other performance metrics remain accurate.
- The Timeline: The correction is being deployed now and will take several weeks to fully reflect across all accounts.
Why We Care: Reporting to clients or stakeholders just got a little awkward. Since this bug has been active for nearly a year, many year-over-year comparisons might look like a "loss" in visibility when the fix hits. Marketers should proactively communicate this "data anomaly" to stakeholders now to explain that while the reported impressions are dropping, the actual click-throughs and revenue-driving traffic haven't changed.
5. YouTube Is Testing 90-Second Unskippable Ads on TVs
YouTube is leaning further into its role as a traditional TV replacement and longer, less skippable ads are the price of admission.
While YouTube recently introduced 30-second unskippable formats, some viewers are now reporting massive 90-second ad blocks before the "Skip" button even appears. These longer interruptions are appearing primarily on connected TV (CTV) devices rather than mobile or desktop.
How it works:
- The "TV" Experience: The ads mimic traditional commercial breaks, sometimes exceeding 90 seconds in total.
- Content Agnostic: Early reports suggest these long blocks aren't tied to the length of the video, they’ve been spotted on both short clips and long-form content.
- The Pushback: Google officially stated on X that they "do not have a 90-second ad format," suggesting this may be a glitch or a very aggressive "ad pod" test where multiple shorter ads are bundled together without a skip option.
Why We Care: YouTube is successfully carving out premium, TV-like inventory that allows for longer, more impactful storytelling. For brand advertisers, this is a golden opportunity to run traditional TV-style creative with the precision of digital targeting. However, the user backlash is real; if the "ad load" becomes too heavy, we might see a surge in ad-blocker usage or a migration to "Lite" subscription tiers.
6. YouTube Expands Media Kit Insights and Tools
New Media Kit insights and AI tools are coming for YouTube creators. This week, the video platform announced expanded audience data and more AI editing tools.
The new Media Kit includes data on subscribers, video posting frequencies, and unique viewers. There is also expanded information on demographics, including parental status, household income, and more.
YouTube Create, the platform’s editing tool, added AI tools that should make it easier to edit and process complex video clips.
7. Instagram Debunks Popular Engagement “Hack”
Many “gurus” have said that reposting feed posts to Stories is a surefire way to increase engagement. This week, Instagram debunked that “hack.”
In Adam Mosseri’s weekly Q&A, he shared that “You can definitely share your own post to your Stories, or re-share your own post, but it’s not going to meaningfully change your reach overall, because Feed generally gets more reach than Stories anyway, and you can’t really re-post your own thing because it was already posted, so it won’t really change the eligibility.”
He also said that, “Generally speaking, those hack-type tactics sometimes work, usually don’t, and when we find them, we usually shut them down,” Mosseri said. “It’s more important to focus on who is your audience, what are the patterns for what’s resonating and what’s not [and] how can you double-down on those patterns, while staying true to your own goals and identity and who you are.”
Why We Care: We’ve always said that focusing on your audience is the biggest growth “hack” there is, but now we can say that Head of Instagram, Adam Mosseri, agrees.
8. 58% of Snapchat Users Turn to the App for Health and Wellness Research
Calling all health and wellness brands! If you’re not on Snapchat, you’re going to want to read this. According to a new study, 58% of daily users are turning to the app for health and wellness research.

Other interesting findings included:
- 95% of users say they have an active interest in health and wellness
- 62% say they prioritize regular check-ups
- Snapchat users are 1.2x more likely to purchase health and wellness products
- They are 1.6x more likely to spend more on high-quality products and services
- They are 3x more likely to engage with daily wellness content
- 49% feel more aware of specific treatments and products based on what they’ve seen on Snapchat
- They are 1.5x more likely than non-Snapchatters to find, compare, and remember health content and information
- 59% say they have changed real-world behaviors based on what they’ve seen on Snapchat
Why We Care: The world gets noisier by the minute. Finding this type of impact on one platform can be difficult. If you are a health and wellness brand, you should consider employing Snapchat in your social media marketing strategy.
9. Diversify Your Content to Achieve Success on Pinterest
If you want to find marketing success on Pinterest, you need to diversify your content. The search platform shared new insights into why content diversification is a key driver of engagement.
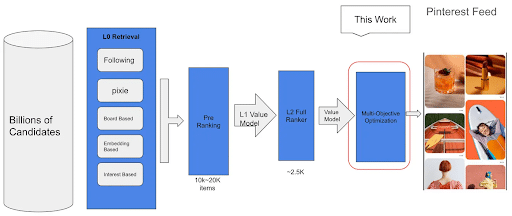
In a new blog post, Pinterest engineers explained, “While earlier stages [of the feed recommendation process] mostly optimize for certain positive actions (e.g., saves) given an impression, the multi-objective optimization layer tackles a different problem: determining the best composition of a feed served to the user. This is critical as users tend to have lower intent when visiting Home Feed and their browsing behavior will be significantly impacted by what they see. For example, visually repetitive content is less engaging and is likely to reduce the user’s session length and the likelihood that a user will revisit Pinterest.”
With over 619 million monthly active users and counting, a lot of brands are paying attention to Pinterest to improve their marketing and reach new audiences. Tips that come directly from Pinterest itself can help those brands find the success they’re looking for.
10. Meta Simplifies Pixel Setup
Any Meta ads manager knows the stress pixel setups can cause. Meta heard the noise and simplified the process.
Now, Meta Ads users can access the official Pixel template in Google Tag Manager, eliminating the need for third-party or community-built workarounds.
This new template allows advertisers to reuse their existing GA4 dataLayer. This allows events already configured for Google Analytics 4 to be leveraged without rebuilding the tracking from scratch. It will also make ad tracking faster and more reliable.
If you’re interested in learning more, log in to your Tag Manager and Meta Ads manager to see the new change.
11. Google Rolls Out Onboarding Guide for Universal Commerce Protocol (UCP)
Google published its new onboarding guide for the Universal Commerce Protocol (UCP) in the Merchant Center this week.
The documentation walks you through completing the technical implementation required before you can access onboarding.
Once that’s completed, you can fill out the interest form, and Google will notify you if you’re selected to participate.
You can learn more about onboarding to the Universal Commerce Protocol here.
12. Google Maps Rolls Out New Features
Google is making it easier for users to contribute their knowledge to Maps.
In a blog post, Google explained that: "Photos and videos you post help people better understand a place, like the overall vibe or the newest menu. Now, we’re making it easier to find the right image for sharing.”
Users can now share images and ask Gemini to create captions. They can also turn on media access in their photo settings to gain access to photos and videos from their recent experiences and directly add them to the Contribute tab on Google Maps.
Users can earn “Local Guide” points by adding photos, writing reviews, answering questions, and checking facts to improve Google Maps.
This seemingly small move will make it easier for local businesses to boost their local SEO with the help of their favorite customers.
Weekly Homework:
- Read the SEMRUSH study about ChatGPT and use the findings to guide your content strategy.
- If you’re in the health and wellness industry, consider adding Snapchat to your social media marketing strategy.
- Check out Pinterest’s suggestions on how to improve your visibility and expand your reach.
- Review your traffic and ranking data to see how the Google March Core Update affected your site and then adjust your strategy accordingly.
- If you’re interested in participating in Google’s Universal Commerce Protocol in the Merchant Center, access the new onboarding document to add your name to the list of interested merchants.
Digital Marketing News 3/28/2026 to 4/3/2026
This week: AI search favors Reddit content, Gemini traffic growth surges, and ChatGPT hits $100M ads.
Here's what happened this week in digital marketing:
1. Reddit, YouTube, and LinkedIn Dominate AI Search Citations
A new study analyzing 30 million sources reveals that AI search engines are heavily relying on third-party platforms like Reddit, YouTube, and LinkedIn to generate answers.
Reddit emerged as the most-cited source across major AI tools, including ChatGPT, Google AI Mode, and Perplexity, largely due to its depth of real user discussions. YouTube and LinkedIn also ranked highly, while platforms like Wikipedia and Forbes continue to serve as foundational authority sources. For recommendation-based queries, review sites like Yelp and G2 frequently appear.
The takeaway is clear: AI models prioritize a mix of authoritative content and authentic user-generated insights. This means visibility in AI-driven search isn’t just about your website, it’s about your presence across the broader digital ecosystem.
Action Item: Expand your content strategy beyond owned channels. Actively invest in platforms like Reddit, YouTube, and LinkedIn to increase your chances of being surfaced in AI-generated search results.
2. Google Gemini Sends 41% More Traffic to U.S. Websites than Perplexity
A recent study by SE Ranking found that Google Gemini sends more traffic to websites than Perplexity.
The study revealed that:
- Google Gemini growth started after the rollout of the 3 Gemini models
- Website visits from ChatGPT dropped by almost 22% between November 2024 and January 2026
- ChatGPT still drives nearly 80% of global AI traffic to websites
- ChatGPT web traffic jumped 53.8% after the release of GPT-5
- Gemini is currently growing at roughly 47% per month
Why We Care: Regardless of these numbers, these studies show just how volatile AI search can be. While it’s definitely going to drive traffic to some websites, just how much and which platform is the best will be anyone’s guess. If you’re going to focus on your AI web traffic, prepare yourself for spikes and dips – it’s totally normal.
3. Google’s March 2026 Core Update Has Started
Google’s March 2026 Core Update started on March 27th, and the dashboard says it could take up to two weeks to complete.
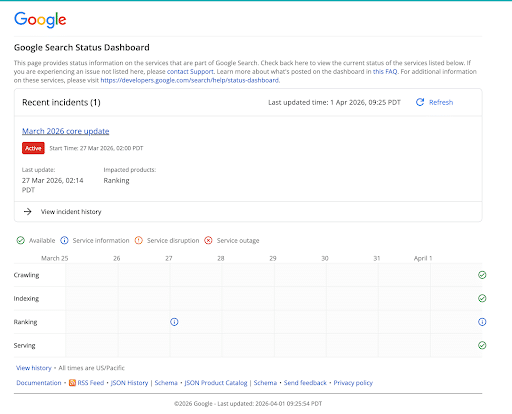
The dashboard also notes that the rankings will have the biggest impact. We aren’t sure exactly how or why, though, because Google hasn’t published a companion blog or made a specific goal announcement.
For now, it’s important to just keep an eye on your traffic – and don’t panic. Some volatility is normal, especially as the update continues to roll out.
4. ChatGPT Introduces Location Sharing for More Personalized Local Results
OpenAI is rolling out a new location-sharing feature in ChatGPT, designed to improve the accuracy of local search responses.
With user permission, ChatGPT can now access precise device location to deliver more relevant recommendations, like nearby restaurants, services, or stores. The feature is optional and can be adjusted in settings, giving users control over how much location data is shared.
For marketers, this update signals a shift toward more personalized, location-driven AI experiences. While early feedback suggests results may still vary in accuracy, the move highlights the growing importance of local relevance in AI-powered search.
Key Takeaway: As AI tools become more location-aware, optimizing for local visibility, through listings, reviews, and proximity signals, will play an even bigger role in how brands show up in AI-driven search results.
5. ChatGPT Hits $100 Million in Ad Revenue, Opening Self-Serve Ad Access in April
OpenAI hit a big milestone this week – $100 million in ad revenue.
That number was generated from fewer than 20% of eligible US free and Go tier users who see ads daily. With about 85% of those users eligible to see ads, the current revenue represents only a fraction of what the platform can eventually generate.
With more than 600 advertisers now using the platform, OpenAI announced that the self-serve ad databoard will launch to consumers this month. Based on the company's ad success in the US, it is also exploring expansion into Canada, Australia, and New Zealand.
Why This Matters: AI is changing digital marketing, including paid ads. As AI companies deepen their presence in advertising, marketers need to pay attention.
6. Why ChatGPT Ads Are Prioritizing Clarity Over Creativity
New data shows that advertising within ChatGPT is quickly evolving into a highly structured, intent-driven format, where clarity consistently outperforms creativity.
According to recent analysis, top-performing ads are short, direct, and highly contextual, often following a simple “Brand: Benefit” format. Instead of storytelling or clever hooks, successful ads focus on immediate value, using concise messaging, specific numbers, and clear calls to action to match the user’s intent in real time.
This shift reflects a broader change in how users engage with AI platforms. Rather than browsing or discovering, users are typically in decision mode, making relevance, credibility, and precision far more important than traditional brand-driven messaging.
Action Item: Rethink your ad strategy for AI platforms, prioritize concise, value-driven messaging that mirrors user intent, and test formats that emphasize clarity, proof points, and direct calls to action over creative storytelling.
7. New Controls and Features Come to Google PMax
Google just dropped new reporting and control features for Google Performance Max.
The new tools include:
- First-party audience exclusions
- Budget reporting to help project end-of-month spend
- Full audience reporting, including breakdowns for different audience demographics and segments
- Network segmentation in placement reporting to better identify where your ads have been served
With these new tools, marketers will be able to better understand the “why” behind your results. Using that information, you can create better ads and achieve a higher ROI.
8. New Ad Options Come to Meta
At its annual IAB Newsfront event, Meta announced some new ad display options.

The new tools and options include:
- New content and category lineup for Reels Trending Ads
- Expanded Creator Marketplace features
- The release of Facebook Collabs in the Partnership Ads Hub
- A redesigned Partnership Ads Hub
- UGC-style videos with avatars
- Video and image voiceover options
- Improved catalog product videos
All of the tools and options are designed to make ads as interactive and engaging as the organic content consumers love.
9. Meta Tests Instagram Plus
Meta confirmed to TechCrunch that it is testing something new – Instagram Plus.

As of now, Instagram Plus includes features such as:
- Create unlimited audience lists for Stories, beyond Close Friends
- See how many people have rewatched a Story
- Spotlight a Story (up to once a week) to get more eyes on it
- Give a vibrant, animated Superlike on Stories to show extra love
- Extend a Story for an additional 24 hours so more followers can see it
- Preview a Story without showing up as a viewer
- Search story viewer list instead of having to scroll through it
While Meta hasn’t confirmed where it’s doing these tests, social media reports indicate that users in Mexico, Japan, and the Philippines have seen the test live.
10. Reddit Adds Publisher Tools to Reddit Pro
Reddit is continuing to improve its ad opportunities. This time, with new publisher tools in Reddit Pro.
The new tools provide:
- Community snapshots: For each community discussing their links, publishers can now access a snapshot of each community’s rules, stats, and most discussed links directly in Pro
- Community notes: Publishers can also manage their own notes for each community directly in the Links tab, keeping their strategy and context in one place
Reddit will also be improving Reddit Pro profiles for all users by adding features like profile flairs that let users highlight posts and organize their stories.
The goal is to make it easier for publishers to share important stories and information with their audiences, while continuing to amplify their reach on the platform.
As part of a free public beta test, Reddit publishers can access these tools by verifying their domain in the Links tab on the Reddit Pro platform.
11. YouTube Engagement Just Got Easier
YouTube added a new feature that big brands and creators will love – Comments to Heart.
The new tool will automate engagement by allowing creators to select multiple comments and “heart” them all at once.
While this may seem like a small feature, it could save some brands hours of consumer engagement.
In addition to Comments to Heart, YouTube also announced the rollout of live stream Gifts and Jewels to more markets, including Australia, Indonesia, New Zealand, Taiwan, and Thailand. This is the second expansion since offering the product initially to U.S. creators in 2024 and then to Canadian and Korean streamers earlier this year.
12. LinkedIn Shares Tips to Increase Engagement
In a new report, LinkedIn shared tips on how you can improve the performance of your long-form articles and posts.
Those tips included these four key suggestions:
- Share insights and actual data
- Build an ongoing audience with newsletters
- Make content easy to consume by adding skimmable sections and a TL;DR recap to your posts
- Highlight experts and trusted voices to improve your credibility
While these tips are geared toward what LinkedIn is seeing among its users, they can easily be applied to any marketing platform.
13. 42% of Brands Say Limited Tool Integration Is Biggest Barrier to Marketing Personalization
Looking at consumer data, it’s becoming abundantly clear that consumers want personalization. So what’s holding brands and marketing agencies back? According to a new eMarketer survey, it’s their data stack.
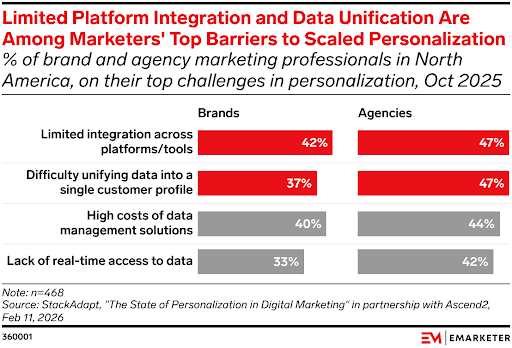
According to the survey participants, the biggest barriers to improving personalization attempts include:
- Limited integration
- Difficulty unifying data into a single customer profile
- High costs of data management solutions
- Lack of real-time access to data
The numbers vary but are pretty similar across brands and marketing agencies, leading us to believe this is an industry-wide problem. If your tech stack doesn’t appear to be working for you, just know you’re not alone.
Weekly Homework
- Keep an eye on your Google ranking and traffic, as they may be volatile due to the Google March Core update.
- Research whether ChatGPT ads could benefit your brand.
- Explore the new tools in your PMax dashboard to see if any of them could help you increase your PMax ROI.
- Check out the new ad options and tools for your Meta ads.
- Sign up for the new Reddit Pro options while the beta is still free for brands and creators.
- Take a look at your tech stack. Is it working as well as it should or could you make some chances to improve your marketing’s performance and personalization?
Digital Marketing News 3/21/2026 to 3/27/2026
This week: AI-generated content loses ranking, ChatGPT citations favor listicles, and Google tests AI headlines.
Here's what happened this week in digital marketing:
1. Study Reveals: AI Speeds Up Content Creation But Doesn’t Drive Lasting SEO Impact
A new study published by Search Engine Land found that AI-generated content might not improve your SEO visibility as much as you think.
Over 16 months, the researchers followed 20 brand-new domains across a variety of industries to see whether AI-generated content was really the marketing super-answer we’ve all been looking for.
The results revealed that:
- Month 1: 71% of new AI-generated pages were indexed within the first 36 days
- Months 2-3: Most continued to grow
- Months 3-6: Only 3% of the pages remained in the top 100
- Month 15: No site showed meaningful recovery, although 66.9% of the sites were still indexed
The study reported that the visibility crashed due to:
- Lack of authority
- No author credibility
- No unique content
- Poor site structure with no internal linking, topical organization, or clear hierarchy to help Google understand page relationships
Bottom Line: AI may have made it easier to get content posted, but you need a real SEO strategy if you want your long-form content to continue generating traffic long after you’ve posted it.
2. AI Citations Are Favoring Listicles, Articles, and Product Pages
A new study analyzing 75,000 AI-generated answers across ChatGPT, Google AI Mode, and Perplexity shows that over half of all AI citations point to just three content formats: listicles (21.9%), articles (16.7%), and product pages (13.7%). The research also reveals that user intent, not industry or model, drives what gets cited.
- Informational queries: Articles dominate, cited 2.7x more than other formats.
- Commercial queries: Listicles capture 40% of citations, nearly double any other type.
- Transactional/navigational queries: Product and category pages lead (~40% combined).
Interestingly, third-party listicles outperform brand-led lists in professional services, showing that LLMs prefer neutral, editorial comparisons. Model differences exist: ChatGPT favors articles, Google AI Mode is balanced, and Perplexity pulls heavily from forums like Reddit.
Key Takeaway: Align your content format with user intent. Articles educate, listicles drive comparison, and product pages convert. A strategic approach like this can boost AI citation visibility and ensure your content gets noticed.
3. ChatGPT Citations Are Concentrated Among a Few Domains, Favoring Broad Coverage
A recent study by Kevin Indig shows that ChatGPT concentrates citations among roughly 30 domains, which capture 67% of all citations within a topic. The research highlights that simply ranking No. 1 in Google isn’t enough, AI favors domains that cover topics broadly with long-form, cluster-based content.
- Citation concentration: Top 10 domains in product comparisons earned 46% of citations; top 30 earned 67%.
- Page retrieval vs. citation: ChatGPT retrieves ~6x more pages than it actually cites; 85% of retrieved pages never get cited.
- Content length matters: Pages 5,000–10,000 characters saw significant lift; pages over 20,000 characters averaged 10 citations vs. 2.39 for pages under 500. Finance was an exception, favoring shorter, denser pages.
- Position on page: Upper 10–20% of content earned the majority of citations; bottom sections rarely contributed.
Key Takeaway: To win in AI search, focus on building topic authority with comprehensive, long-form content rather than isolated keyword pages. Cover your topic from multiple angles, structure content strategically, and prioritize the sections that get cited most.
4. Google Tests AI-Generated Headlines in Search, Raising Publisher Concerns
Google is experimenting with AI rewriting search result titles to better match queries and boost engagement. While the test is currently small and narrow, it spans beyond news sites and can change tone, intent, or meaning in headlines.
- Example: A verbose, playful headline like “I used the ‘cheat on everything’ AI tool and it didn’t help me cheat on anything” was shortened to “‘Cheat on everything’ AI tool.”
- Title generation sources: Google considers page content, headings, meta tags, anchor text, structured data, and other prominent text.
- Publisher reaction: Editors warn AI-generated titles risk misrepresenting content, altering brand voice, and affecting CTR, potentially undermining audience trust.
Key Takeaway: If your site relies on carefully crafted headlines, start monitoring Google Search title changes closely. Be ready to adapt your SEO strategy and track click-throughs to ensure your content still resonates with readers.
5. Google Ads PMax Gets AI Animation for Static Images
A new AI-powered feature spotted in Performance Max campaigns lets advertisers generate animated clips from a single image, no video production needed. This could be a game-changer for brands running static-image campaigns without a video budget.
- How it works: Upload a source image (product, logo, or property photo) → AI generates enhanced versions → each produces two animated clips → select up to five per asset group. Faces can’t be used as source images.
- Early tests: Logos can spin, property photos get cinematic pans, simple inputs, but high-quality display-ready output.
- Placement: Clips appear in Display ad previews; broader rollout details are unclear.
Action Item: Advertisers using PMax should check their asset groups for this feature. Testing AI-generated animated clips can boost engagement and make campaigns more visually dynamic, without extra production costs.
6. OpenAI Cuts Some Features But Adds New Shopping Experiences
Change is in the air for OpenAI. The same week the platform announced it would shut down its video app, Sora, it also unveiled new shopping features.
Now, users can now either upload images of products to search for or describe products using budgeting or preference constraints. OpenAI will then present side-by-side options with key details like price, reviews, and features to help searchers make their decisions.
In doing this, they also added the option for merchants to use their Agentic Commerce Protocol (ACP) to share product feeds and promotions. Some retailers, like Target, Sephora, Nordstrom, and Lowe’s, have already integrated with the new system.
Why We Care: Any new way for people to find your product is worth paying attention to. OpenAI might be cutting options that aren’t cost-effective, but that doesn’t mean they’re shying away from other major improvements, like improving in-app shopping.
7. Bing AI New Dashboard Tool Reveals More AI Visibility Data
Thanks to a new tool, Bing AI Performance users can now connect AI citation data to specific URLs on their sites.
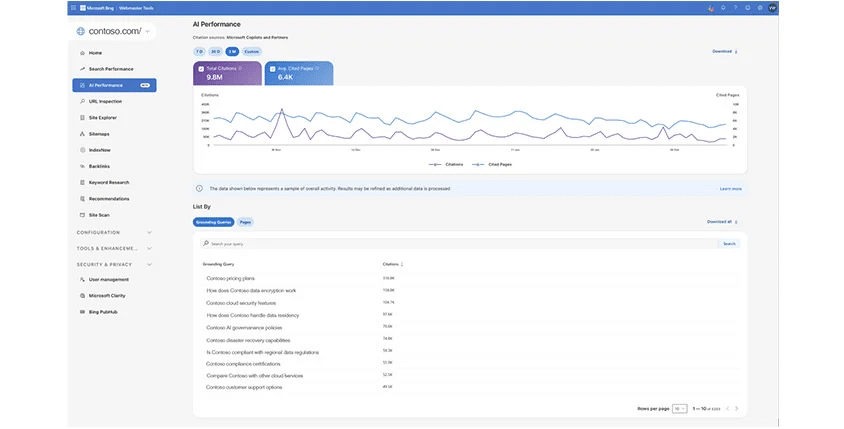
The new AI performance dashboard measures:
- Total citations
- Average cited pages
- Grounding queries
- Page-level citation activity
- Visibility trends over time
- Grounding query-page mapping
Having these valuable insights can help Bing users know what content is attracting views and which can be improved. If showing up in AI search is a priority for you (and it should be!), this tool could be a game-changer.
8. Google Business Profile Tests AI-Generated Review Replies
Google is rolling out a limited test in Google Business Profile that suggests AI-generated responses to customer reviews. Businesses can review, edit, and manually submit replies, aiming to save time while maintaining engagement.
- Feature rollout: Spotted in the U.S., Brazil, and India; availability is inconsistent and not yet widespread.
- Functionality: AI generates suggested replies, with some users reporting prompts for older negative reviews. Bulk suggestions may require review, though some reports indicate fully automated posting is possible.
- Why it matters: While timely responses can build trust and impact conversions, generic AI replies risk damaging credibility, especially on sensitive negative reviews. Authenticity and quality still matter more than speed.
Key Takeaway: If your business has a high volume of reviews, this feature could streamline responses, but always review AI suggestions to preserve brand voice and trust.
9. 68% of Small Businesses See Social Media as Path to Success
Your social media feeds might start getting a little more crowded. According to a recent study published by EMarketer, 68% of small business owners see social media marketing and paid ads as their quickest path to success.
By polling small business owners in Australia, Canada, New Zealand, the UK, and the US, Constant Contact found that the majority felt they would find more success with social media posting and paid ads.
Other options included:
- Email marketing: 41%
- In-person events: 29%
- Traditional advertising: 26%
This could mean one of two things: either you beef up your social media marketing and paid ad efforts or you lean more heavily toward things like email marketing, blog writing, or SEO strategies to cut through the noise and find your audience.
10. Reddit Ads Expand Access
A new partnership with the software company Pacvue is making it easier than ever to use Reddit Ads.

The platform’s existing user base of over 70,000 businesses will now have access to manage their Reddit ads from the same dashboard where they manage all other paid ads.
This is excellent news for advertisers who want to streamline their ad management process. With Reddit getting more attention lately because of the increase of AI chatbots citing Reddit results, making it easier to advertise on the platform could be a win-win situation for both the platform and advertisers.
11. Reddit Introduces New Ad Options
Speaking of Reddit, the platform also rolled out some new advertising options this week.
Advertisers can now access opportunities such as:
- Collection Ads - pairing a lifestyle hero image with shoppable product tiles in a single DPA carousel
- Community Overlays - the ability to indicate products that are already resonating with Reddit users
- Deal Overlays - the ability to automatically call out discounts and sale pricing
- Shopify Integration - the ability to automatically identify which products to show to each user with a simplified catalog and pixel set up
With these improved ad options and easier access to ad management, now is a good time to explore Reddit Ads for your business. This is especially true, as 84% of Reddit shoppers feel more secure about their purchases after searching on the platform.
12. YouTube Makes It Easier to Connect Brands and Content Creators
If YouTube is one of your main content platforms, you’re going to love these new tools from its creator partnership program.
The new platform is meant to streamline BrandConnect with the Creator Partnerships Hub to deliver:
- Improved brand deal matching and outreach
- Sharing channel insights
- Collaboration features, such as YouTube’s Media Kit and Open Call elements, are built in
- AI-powered brand partnership recommendations
Influencer marketing remains a valuable part of the content marketing puzzle, especially given that 83% of Gen Z prefer watching their favorite creators to other studio-produced content. This new platform will streamline the process of finding the right influencer to partner with for your brand.
13. Human Speech Improves Reels Retention by 25%
Struggling to get traction on Instagram? Try adding human speech to your Reels!
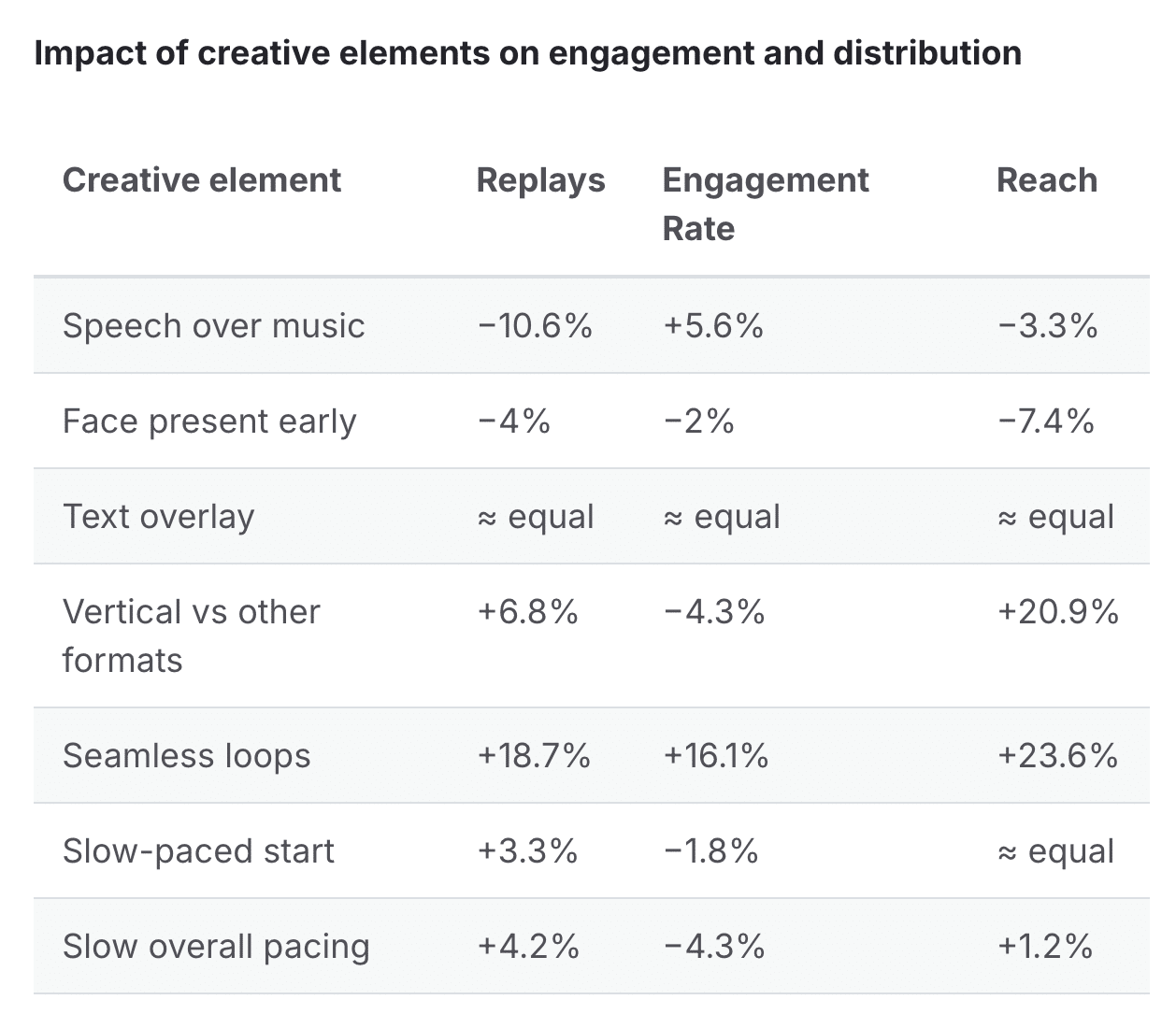
A new study by Emplifi revealed that videos that start with human speech, rather than music, can improve retention by:
- 3-second retention: +11.7%
- 10-second retention: +24.7%
- 30-second retention: +6.6%
Speech-based videos also see a 5.6% higher engagement rate over music-only content. With 61.8% of brand Reels still not containing any speech, this could be a way to stand out from your competition.
Other ways to improve Reels retention include:
- Human faces
- Text overlay
- Vertical formats
- Seamless loops
- Slow-paced start
- Slow overall pacing
This is a great time to jump into Reels, especially since Instagram just released a new way to transition between still images to create a Reels clip.
As Instagram explains: “You can use AI transition to create a seamless video from multiple photos in your Instagram story. To use AI transition, you must agree to the Meta AI terms. You’ll be prompted to do so the first time you use AI transition if you haven’t already.”
14. Google’s March 2026 Spam Update is Complete
Google started rolling out the March 2026 spam update on March 24th. It’s already completed.
The update was completed within 20 hours. To put this into perspective, the August 2025 spam update took 27 days to complete, and the December 2024 spam update took 7 days.
While this update was incredibly fast, keep an eye out for ranking or traffic changes in the next few days. Any changes could be due to this update or the Google February Discover update.
15. Google Expands Universal Commerce Protocol
Google’s Universal Commerce Protocol, or UCP, has some great new updates that will encourage a simpler path for retailers.
New capabilities include:
- New Cart option that lets agents save multiple items to a cart at one time
- New Catalog option that lets agents receive real-time product information when necessary
- New Identity Linking option that allows shoppers on UCP platforms to receive the same loyalty or member benefits as they would when shopping directly from a retailer’s website
In addition to these shopper improvements, Google also added new onboarding options in the Merchant Center that will make it easier for merchants to navigate through the UCP. While some merchants already have access to this new onboarding experience, others may have to wait a bit. But don’t worry. Google says that the new experience will be rolled out to everyone in the US within the next few months.
Weekly Homework:
- Consider whether you want to fight against the 68% of small businesses that are leaning heavily into social media marketing and paid ads, or pivot your marketing strategy to capitalize on the opportunities they leave in other avenues.
- Keep an eye on your organic traffic and ranking status. If it drops, you could have been affected by Google’s recent updates.
- Are you a Google UCP marketer? Check out the new tools and opportunities that were recently added to the platform.
- Interested in how your content is performing with AI? Check out Bing’s new AI dashboard.
- Explore the new Reddit Ads opportunities to see if any of them could fit into your existing strategy.
- Review the Search Engine Land study about AI-generated content to see how you can use its findings to improve your website’s ranking.
- Try to post some more human-first Reels on Instagram and Facebook. See if adding a face and a voice to the opening of your Reel makes a difference in your retention.
Digital Marketing News 3/14/2026 to 3/20/2026
This week: ChatGPT models show citation gaps, OpenAI builds dedicated Ads Manager, and Reddit ads drive 82% ROAS growth.
Here's what happened this week in digital marketing:
1. Study Reveals Major Differences in Citations Depending on ChatGPT Models
A new analysis revealed that you may get different answers depending on which ChatGPT model you use.
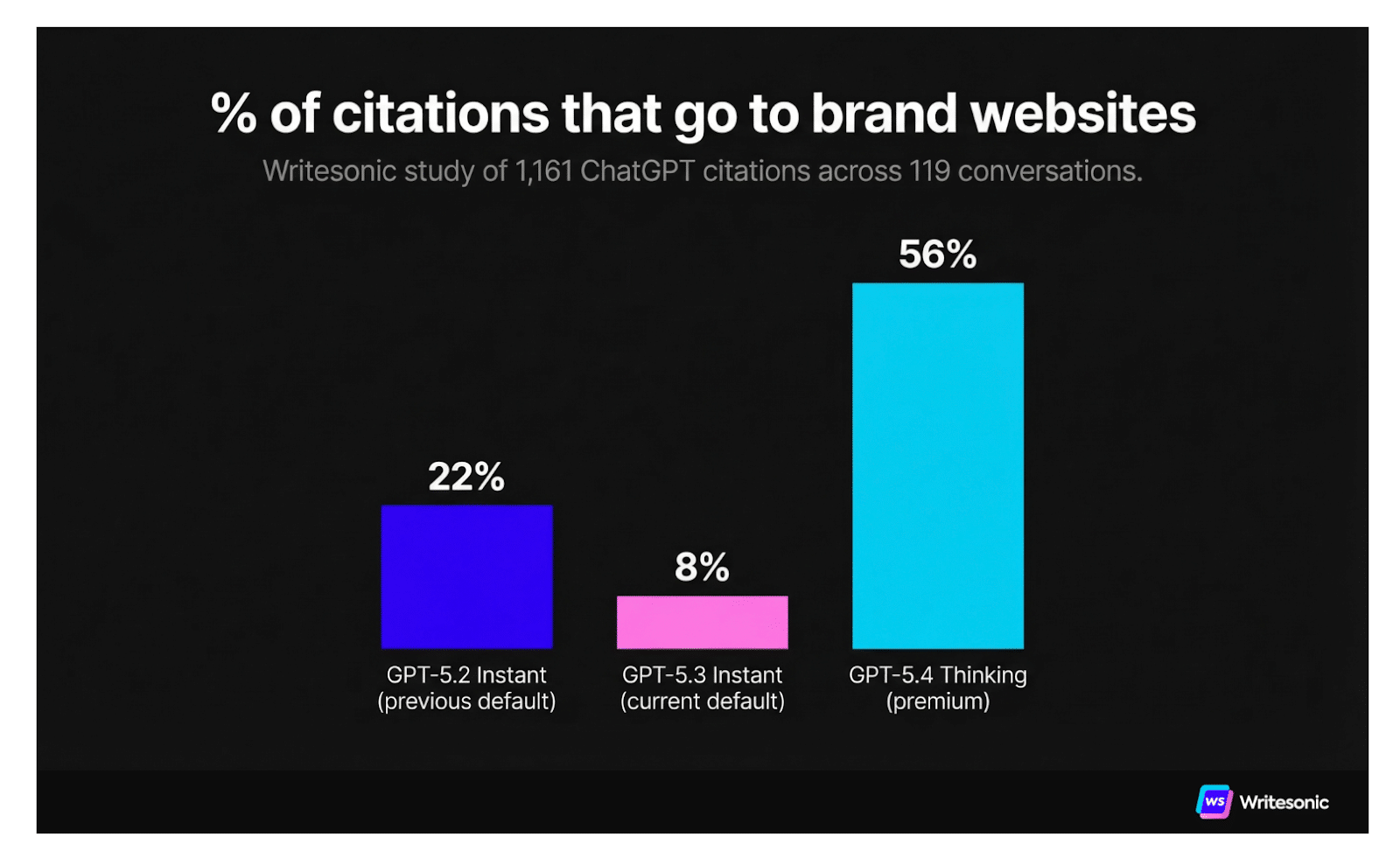
According to the data, different models will display different results. For example, brand websites appear in the following citations:
- GPT-5.4 - 56%
- GPT-5.3 - 8%
- GPT-5.2 - 22%
The current default model, GPT-5.3, returned mostly third-party content. This includes blog posts and articles on sites like Forbes, TechRadar, and Tom’s Guide.
The current premium model, GPT-5.4, returned mostly brand homepages, pricing pages, and product pages.
Why We Care: Brands are clamoring to get mentioned in AI responses. Understanding what each model is looking for is the first step to achieving that goal.
2. OpenAI Tests New Ads Manager
As more advertisers use ChatGPT, OpenAI has realized it needs a place for people to organize those ads. Introducing the Ads Manager dashboard.

OpenAI confirmed this week that it is beginning to build the infrastructure for a formal ad management system, suggesting that ChatGPT ads are here to stay.
This system is currently available to early adopters, but we’ll continue to follow this to see when it is released to more brands.
3. Ads Could Be Coming to Google Gemini
Speaking of AI ads, Google seems to have changed its stance of no ads on the app – ever.
While Google DeepMind CEO Demis Hassabis told reporters at Davos in January that there were no plans to bring ads to Gemini, SVP Nick Fox said otherwise.
In an interview with WIRED, Fox said that Google is “not ruling out” ads, saying what they’ve learned from ads in AI Mode will “likely carry over” to Gemini.
Google isn’t rushing into adding ads to the AI bot, but they are using AI Mode to guide their testing grounds by:
- Keeping ads separate from organic results
- Clearly labeling ads
- Only showing ads if they’re relevant to the search
While the testing still seems to be a ways out from hitting even the beta market, it’s something that marketers might want to start preparing for, especially if you’re already using ads in AI Mode.
4. Google Held 73.7% of US Search Market Share in Q4 2025
A new report revealed that Google is still going strong, but sites like Amazon, Bing, and YouTube are also receiving search traffic.
When it comes to product searches, the data revealed that:
- Traditional Search Engines: 80.76%
- Commerce Platforms: 9.76%
- Social Networks: 5.37%
- AI Tools: 3.19%
- Other Verticals: 0.91%
While people are still searching on traditional engines, like Google, Yahoo, and Bing, they are also turning to commerce platforms like Amazon, Walmart, and eBay.
What This Means: If you are an ecommerce brand, you need to ensure your product descriptions are on point and up to date. You should use the same keywords in these descriptions that you use in website copy.
5.Reddit Ads: +82% ROAS Increase
In Fospha’s State of Retail Commerce 2026 Report, it was revealed that Reddit ads are working. Retailers are reporting up to 82% ROAS when using the platform in their marketing.

The report revealed that if you want visibility, you should use:
- TikTok
- Meta
- DemandGen
- YouTube
If you want sales, you need to use:
- Amazon
- Web Search
- TikTok Shop
The biggest reveal of all, though? Reddit. When including Amazon sales, Reddit Ads have an impressive ROAS increase of 82%
You can download the entire report here.
6. Meta Switches Ad Transparency
Meta is making a ton of changes to its ad processes. One of those changes is how it marks something as an ad.
Instead of the previous “Sponsored” language being prominently displayed on the ad, now a simple “Ad” marker is displayed.
While this may seem like a pretty insignificant change, some people think it will make more users see these ads as organic updates rather than paid reach. It could help with CTRs, but it’s also something EU regulators are likely to be watching.
7. Instagram Tests Links in Captions
One of the most annoying things about Instagram is that you can’t place links in your captions. That is now changing – for some paid users.
Instagram has long resisted this, since it would make it easier for users to leave the app. But the app is now testing the option with a select group of verified users.
Creators in the test group can share up to 10 links in a post, per month. It’s important to note that this is currently only available to Meta Verified creators, not publishers or brands.
Why We Care: Links in Instagram captions could be a great asset for marketers, as they make it easier for scrollers to click through to your site. However, since it is currently only available to creators, brands will need to partner with a creator to get their link included in a caption. This could lead to an uptick in influencer brand deals in the coming months.
8. Google Discover Core Update: Some Publishers Lost More than 20% of Placements
Recent analysis of Google Discover data revealed that some local publishers lost more than 20% of their national placements during the most recent Core Update on February 5th.
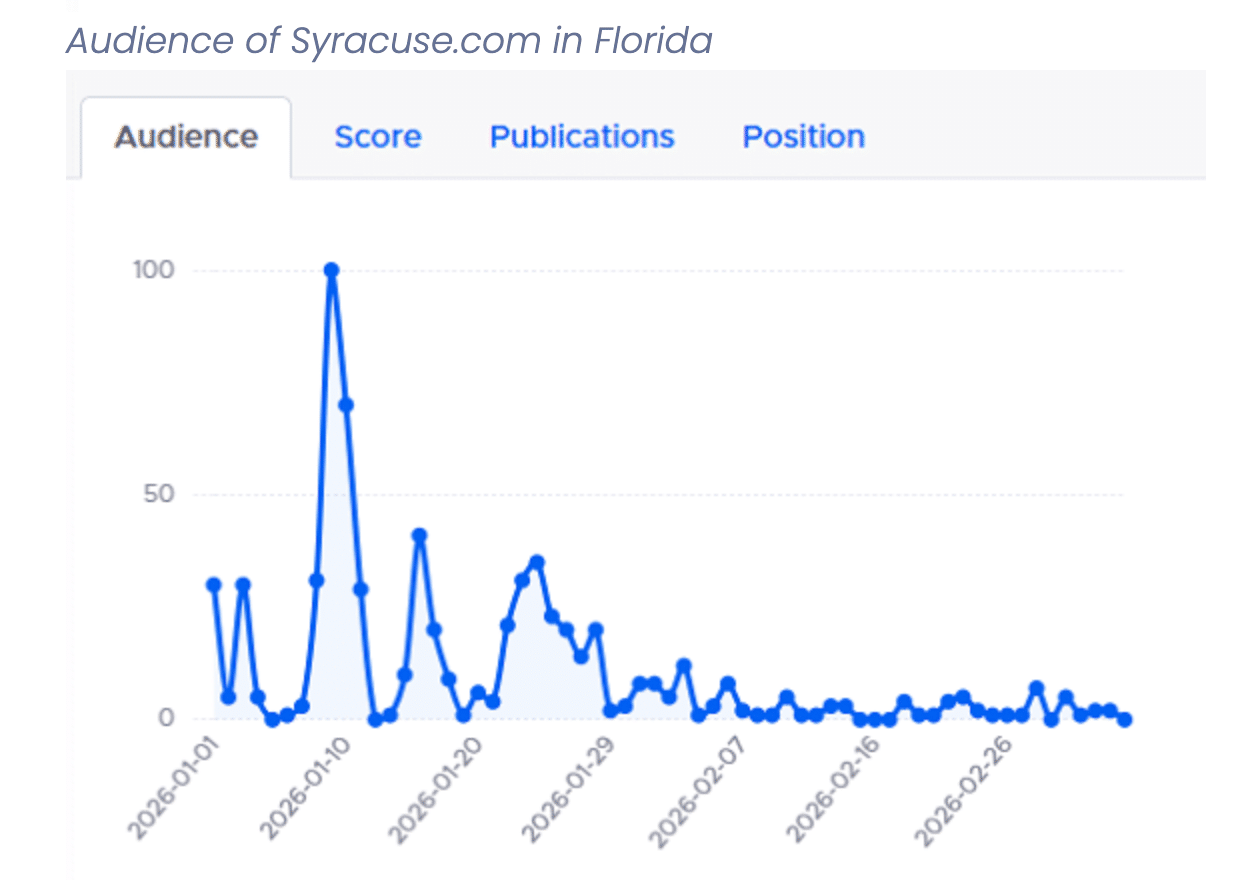
The data revealed that the sites that lost the most traffic included:
- X
- Yahoo
- Fox News
- Go
- CBS 6 Albany
- Syracuse.com
- Economic Times
- NJ.com
- Forbes
- KTLA
The biggest winner? A student publishing site called GEEditing.com, followed by Parade, Ecoticias (a Spanish news site), Axios, Fortune, and Newsweek.
Why We Care: If you noticed a big drop in traffic, specifically national traffic, you’re not alone. This update seems to have shaken up a lot of things, including giving a random student essay editing site a 531% boost in publication mentions.
9. Google Is Testing “Sponsored Shops”
There’s a new way to advertise on Google – Sponsored Shops.
These new blocks will consolidate all sponsored items into one place, rather than displaying single-product listings. It groups products from the same shop into a single block while also displaying ratings, reviews, and other information. It essentially creates a little mini storefront right there in the Google shopping results.
This update is still in the testing phase. Google has not revealed when it will become available to all advertisers.
10. Pinterest Shares Spring 2026 Trends
If you’re wondering how to connect with your audience this spring, Pinterest has some suggestions.

The biggest finding is that searches are revealing a shift away from perfectionism and reinvention. Instead, consumers want brands that improve self-expression, comfort, and positive vibes.
The report highlighted 4 specific trends:
- Curated comfort makeovers
- Spring soups and creative recipe choices
- Tiny sanctuaries and intentional connection
- Spring cleaning and organizing
Basically, consumers want real, authentic, and intentional content that will make them feel good – not perfectionism that will make them feel worse.
Weekly Homework:
- Review the ChatGPT study to get a firm grasp on what each model is looking for when it returns results to searchers, and then align your content to those results.
- Explore whether Reddit ads could fit into your marketing strategy and goals.
- Download Fospha’s State of Retail Commerce 2026 Report to see if any of the findings could impact or improve your current marketing strategy.
- If you want links in your Instagram captions, you need to look into getting a Meta Verified account.
- If you use Google Ads for your ecommerce brand, explore whether the new Sponsored Blocks could benefit your business.
- Monitor your organic traffic. If you see a large dip, it could be due to Google’s February Discover Core Update.
- Download the Pinterest report to get insights on what spring consumers are searching for.
Digital Marketing News 3/7/2026 to 3/13/2026
This week: AI assistants dominate global search, Google Maps launches AI concierge, and YouTube becomes largest media platform.
Here's what happened this week in digital marketing:
1. AI Assistants Make Up 56% of Global Search Volume
A new study from Graphite.io revealed that AI assistants, including ChatGPT and Gemini, now account for up to 56% of global search volume and 34% of all U.S. search volume.
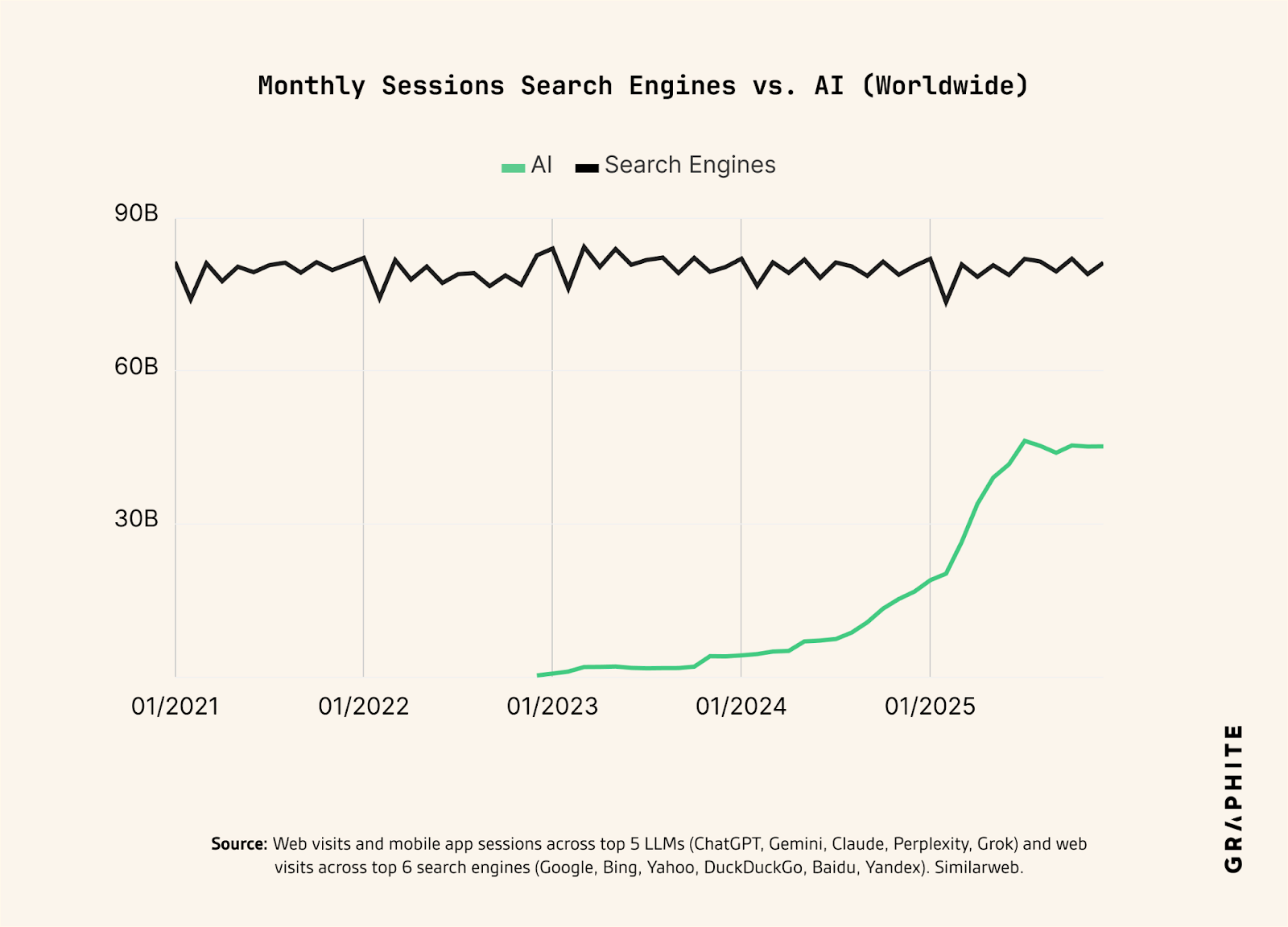
The most popular platforms include:
- ChatGPT
- Gemini
- Perplexity
- Grok
- Claude
Some of the most important findings include:
- AI platforms generate 45 billion monthly sessions worldwide.
- In the U.S., AI accounts for 5.4 billion monthly sessions.
- 83% of global AI usage occurs inside mobile apps (75% in the U.S.).
- ChatGPT dominates AI usage, representing 89% of global AI sessions.
- When isolating search-like prompts (“asking”), AI usage equals 28% of search worldwide and 17% in the U.S.
Why We Care: We’ve been saying it for a while now, but let these numbers show: you cannot avoid AI search when planning your SEO strategy.
2. Study: Retail and Grocery Brands Make Up 44% of ChatGPT Ads
We shared last week that ChatGPT ads are taking off. Now, we have some data on who is cashing in.
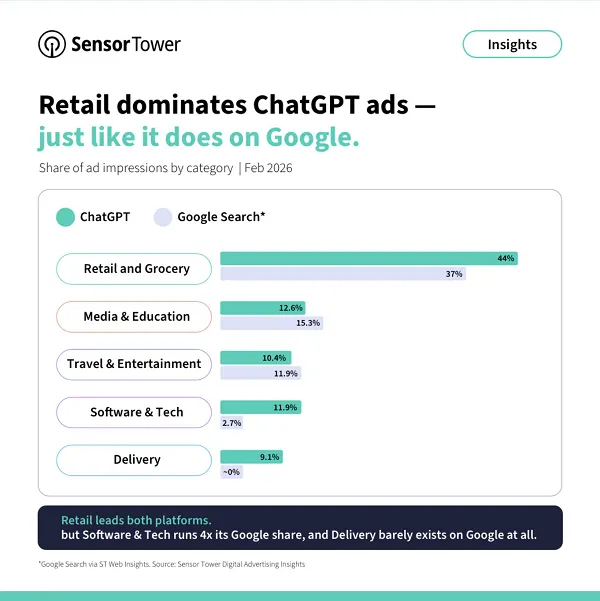
According to a recent SensorTower study, retail and grocery ads account for 44% of ChatGPT ads. Other industries spotted on the site include:
- Media & Education: 12.6%
- Travel & Entertainment: 10.4%
- Software & Tech: 11.9%
- Delivery: 9.1%
These numbers are pretty similar to the types of businesses popular on Google.
Some of the 100+ brands spotted using ChatGPT ads include:
- Retail & Grocery: Best Buy, Target, Chewy, Wayfair, and Ulta Beauty
- Travel & Entertainment: Expedia, Marriot, and Airbnb
- Software & Tech: Canva, Hubspot, Zoom, and Asana
- Media & Education: Netflix, Audible, Coursera, and Spotify
- Delivery: UberEats, HelloFresh, and Factor
While ChatGPT ads are still pretty much in their infancy, it’ll be interesting to follow along and see which brands continue to find success here, and which brands jump ship.
3. Meet Google Maps’s New AI-Powered "Ask Maps"
Google is officially turning its navigation app into a high-level concierge. By injecting Gemini AI into the platform, Google Maps is moving away from being a digital directory and becoming a conversational partner.

The new “Ask Maps” feature allows you to ditch the manual filters and simply ask complex, human questions, like “Is there a public tennis court with lights on that I can play at tonight?”
It analyzes data from over 300 million places and 500 million contributors to give you personalized, conversational answers that factor in your past preferences, like a fondness for vegan food or specific neighborhoods.
Action Item: Since Ask Maps pulls from 300 million places and user reviews to answer conversational queries, local businesses must ensure their Google Business Profile and reviews highlight specific "vibe" keywords (e.g., cozy, quiet, good for groups) to show up in AI-generated itineraries.
4. Google Search Console Launches Branded Queries Filter for Easier Traffic Segmentation
Google Search Console now lets you separate branded and non-branded search traffic natively in the Performance report.
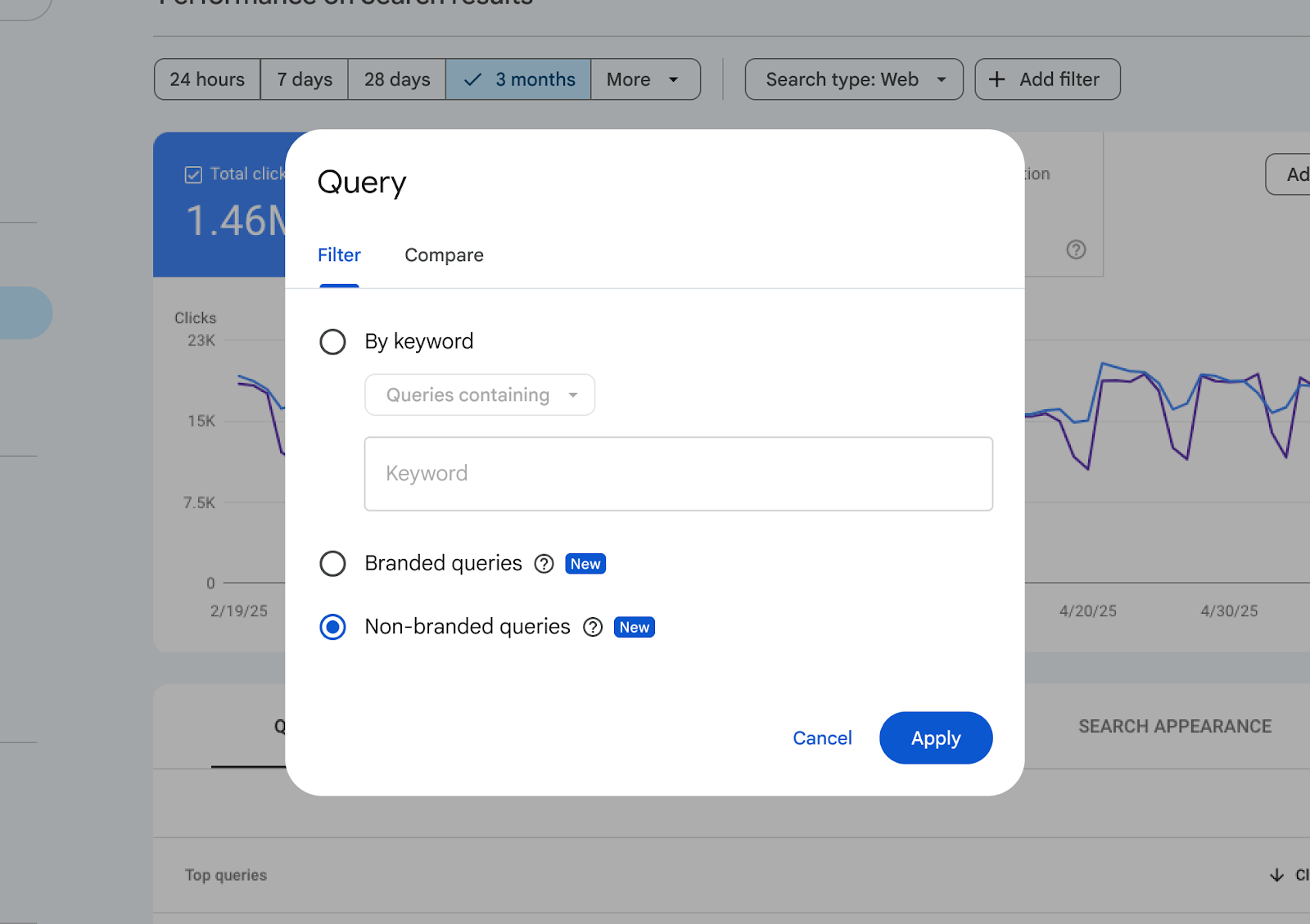
Previously, SEOs and site owners had to manually build complex regex strings or keyword lists to separate people who already knew their name from those who discovered them via general topics. Now, Google uses an internal AI-assisted system to automatically categorize these queries.
The tool is available to all "eligible" sites (those with enough data volume) across Web, Image, Video, and News searches. It allows you to see specific metrics like impressions and CTR for each group and even includes a new visual card in the Search Console Insights report to compare brand recognition against brand discovery.
Key Takeaway: You can now easily see how much traffic comes from people already familiar with your brand versus those discovering your site for the first time.
5. Google Ads Updates Asset Optimization Panel for Demand Gen
Google has just overhauled the Asset Optimization section for Demand Gen campaigns, stripping away the manual clutter and replacing it with a sleek, AI-powered control center.
Think of it as a "command toggle" for your creative assets. Instead of manually cropping videos or hunting for the perfect landing page image, advertisers can now use a centralized panel to let Google’s AI do the heavy lifting.
The update focuses on three big wins:
- Auto-generated shorter videos: AI trims existing video assets into shorter cuts to qualify for additional placements.
- Automatic video resizing: Videos are adapted across multiple aspect ratios to maximize inventory coverage.
- Landing page image pulls: Images are sourced directly from an advertiser’s landing page to generate additional creative variations.
This shift signals a new era for Google Ads: your job is to provide the high-quality raw materials, and Google’s AI handles the distribution and formatting to ensure you're hitting every possible corner of the ad network without the extra production hours.
Action Item: Head into your Demand Gen Asset Optimization panel to enable "Video Resizing" and "Landing Page Image Pulls". These are high-impact, low-effort wins that expand your reach without requiring a single minute of extra creative production.
6. US Users Spend 11.4 Billion Minutes a Day on YouTube
YouTube is now officially the world's largest media platform. According to an eMarketer article, the video platform has officially claimed the top spot, surpassing Netflix, Facebook, and Instagram.
According to the report, US viewers spend:
- 11.4 billion minutes a day on YouTube
- 10 billion minutes a day on Netflix
- 5.4 billion minutes a day on Facebook
- 4.7 billion minutes a day on Instagram
The report also reviewed that YouTube’s ad revenues were more than $40 billion in 2025, which is significantly more than the $37.8 billion in revenue earned by NBCUniversal, Paramount, Warner Bros. Discovery, and Disney – combined.
Why We Care: Is YouTube the missing piece to your content marketing puzzle? With numbers like these, you might want to consider adding the channel to your toolbox.
7. Online Ads Expected to Bypass Traditional Media Ad Spend by 2028
A new report from eMarketer revealed that traditional media will continue to trend downward, even being surpassed by online advertising by 2028.
The forecast revealed that Google, Meta, and Amazon will continue to trend upward, with more brands turning their attention to online platforms. By that ad spend money has to come from somewhere, and it appears that companies will continue to divert funding previously used for traditional advertising away from those outlets and repurpose it with online advertising.
8. 8 out of 10 PMax Advertisers Are Also Running CTV Ads
Speaking of CTV and non-traditional marketing, a new study by Smarter Ecommerce revealed that 8 out of 10 PMax Advertisers are now running CTV ads.
When CTV (connected TV) Ads first appeared on the market, they required a specialist buy. This made them incredibly difficult and complex to access, leaving many advertisers in the dark.
Now, PMax advertisers can run CTV ads straight through their Google Ads account – improving accessibility, impressions, and reach.
This is a significant jump, considering that in January 2023, just over 20% of all PMax advertisers were running CTV ads. Thanks to the approved accessibility, now 80% are.
Action Item: If you are running PMax Ads and want to get into the CTV game, just go to your Google Merchant Center feed to see if your campaigns are eligible for CTV or even shoppable CTV formats. If they are, run a test. If they aren’t, tweak your creative so that they will. Advertisers who have specifically used purpose-built video assets designed for TV screens are outperforming those using auto-generated formats.
9. Medium Engagement Rates Down for Instagram, LinkedIn, and Threads
If you’ve noticed a dip in your engagement last year, you’re not alone. According to a Buffer report, engagement rates on Instagram, LinkedIn, and Threads were down in 2025.
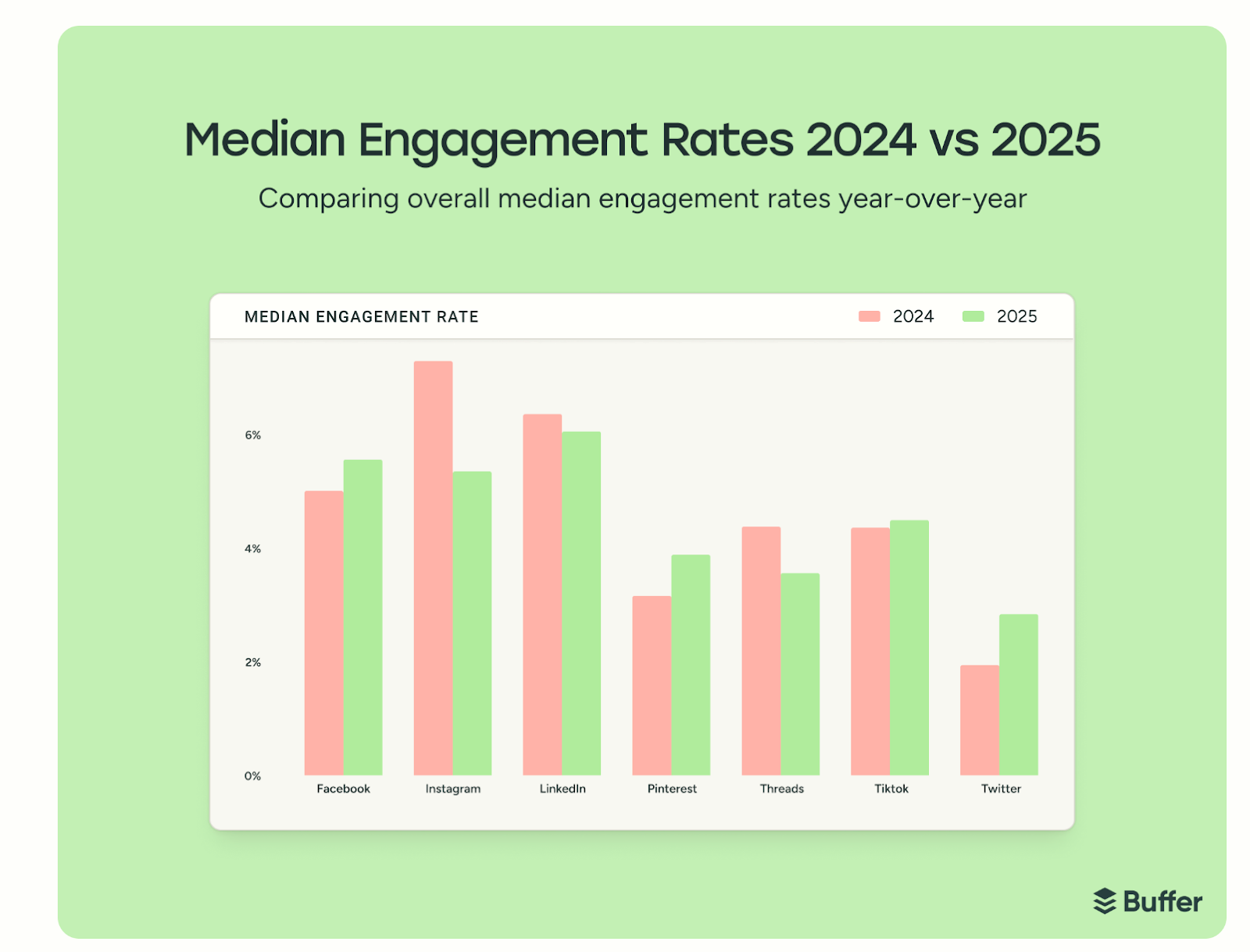
In Buffer’s State of Social Media report, the platform revealed trends including:
- X/Twitter: +44% overall from 2.0% to 2.8%
- Pinterest: +23% overall from 3.2% to 3.9%
- Facebook: +11% overall from 5.0% to 5.6%
- TikTok: +3% overall from 4.4% to 4.5%
- LinkedIn: -5% overall from 6.4% to 6.1%
- Threads: -18% overall from 4.4% to 3.6%
- Instagram: -26% overall from 7.3% to 5.4%
The biggest way to increase your engagement? Reply back. On Threads alone, posts where the creator has replied to comments see a 42% increase in engagement overall.
Why We Care: Obviously, as social media marketers, we want to make the most of our strategies, and that includes posting where we get engagement. While it will vary across businesses and industries, it’s important to note that engagement is technically down on LinkedIn, Threads, and Instagram, but all three platforms still have higher engagement rates than X/Twitter or Pinterest.
10. Meta Ad Prices Increase in 6 Countries
Speaking of Meta Ads, the company has increased its prices in 6 countries, including Austria, France, Italy, Spain, Turkey, and the United Kingdom.
The news was delivered via pop-up with the Ads Manager, and some advertisers have shared it on multiple social media platforms.
Meta explained the increase by saying, “When your ad is delivered to an audience in a jurisdiction with location-specific fees, such as a digital service tax (DST), a location fee will be added to your bill. This fee is separate from your campaign budget and will appear as a distinct line item on your invoice or transaction statement.”
The increase varies by country, but advertisers can expect to see the following impacts:
- Austria: 5%
- France: 3%
- Italy: 3%
- Spain: 3%
- Turkey: 5%
- United Kingdom: 2%
If you are trying to reach audiences in these countries, be sure to factor in this new increase when determining your PPC budget.
11. Meta Expands Social Media Empire with Purchase of Moltbook
Social media giant Meta has made another platform purchase. This time, they’ve acquired Moltbook, a new social network for AI bots.
While humans can read through the discussion, the content on Moltbook is completely generated by AI bots interacting with other AI bots.
In a confirmation to TechCrunch, Meta said, “The Moltbook team joining MSL opens up new ways for AI agents to work for people and businesses. Their approach to connecting agents through an always-on directory is a novel step in a rapidly developing space, and we look forward to working together to bring innovative, secure agentic experiences to everyone.”
Why We Care: With Meta now owning this platform, it could potentially be another place to run Meta Ads in the future.
12. Over 25% of Marketers Are Unhappy with Influencer Pay Agreements
According to new data from the Association of National Advertisers, the US influencer economy is expected to reach almost $44 billion by the end of 2026. With more money comes more calls for pay transparency.
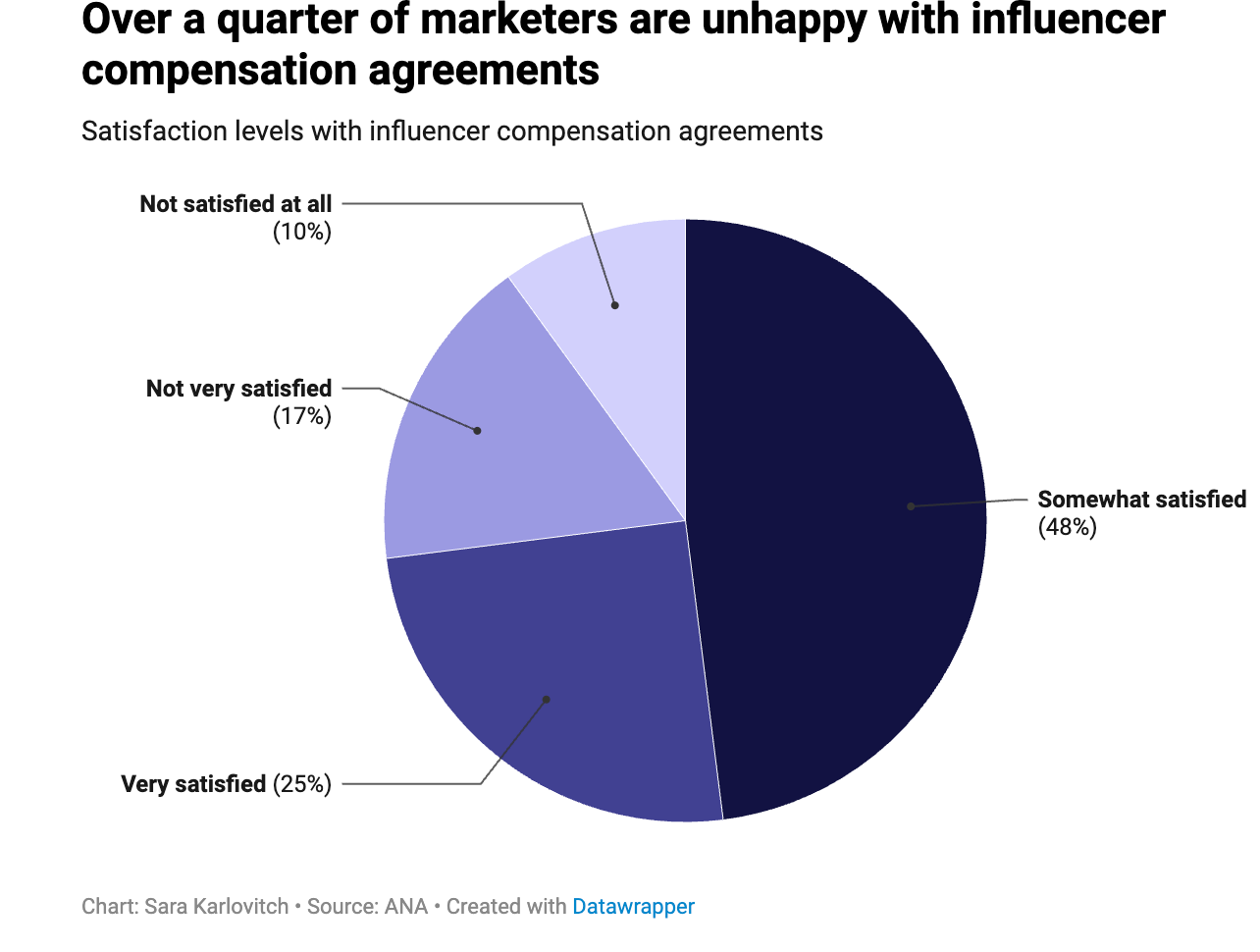
The study revealed that:
- 48% of marketers are only somewhat satisfied with influencer pay agreements
- 10% are not satisfied at all
- 52% take a mixed approach when managing influencer relationships, relying on both in-house and external partnerships
- 16% strictly handle influencer relationships in-house
- 55% said they use a project-based payment model
- 45% use a retainer-based payment model
- 25% tie influencer payment to key performance indicators
Given the frustration with the lack of transparency and satisfaction, 55% of respondents said they are looking to change their influencer compensation strategy within the next year. Only 13% said that they won’t even look into a different model.
Why We Care: Influencer marketing is a major source of income and reach for many brands. Any shake-up, especially in pay transparency and process, will most definitely affect how brands across industries work with influencers and content creators in the near future.
13. 14% of US Workers Are Experiencing “Brain Fry” from AI Overuse
Is AI increasing mental fatigue? According to new research published in Search Engine Journal, it might be.
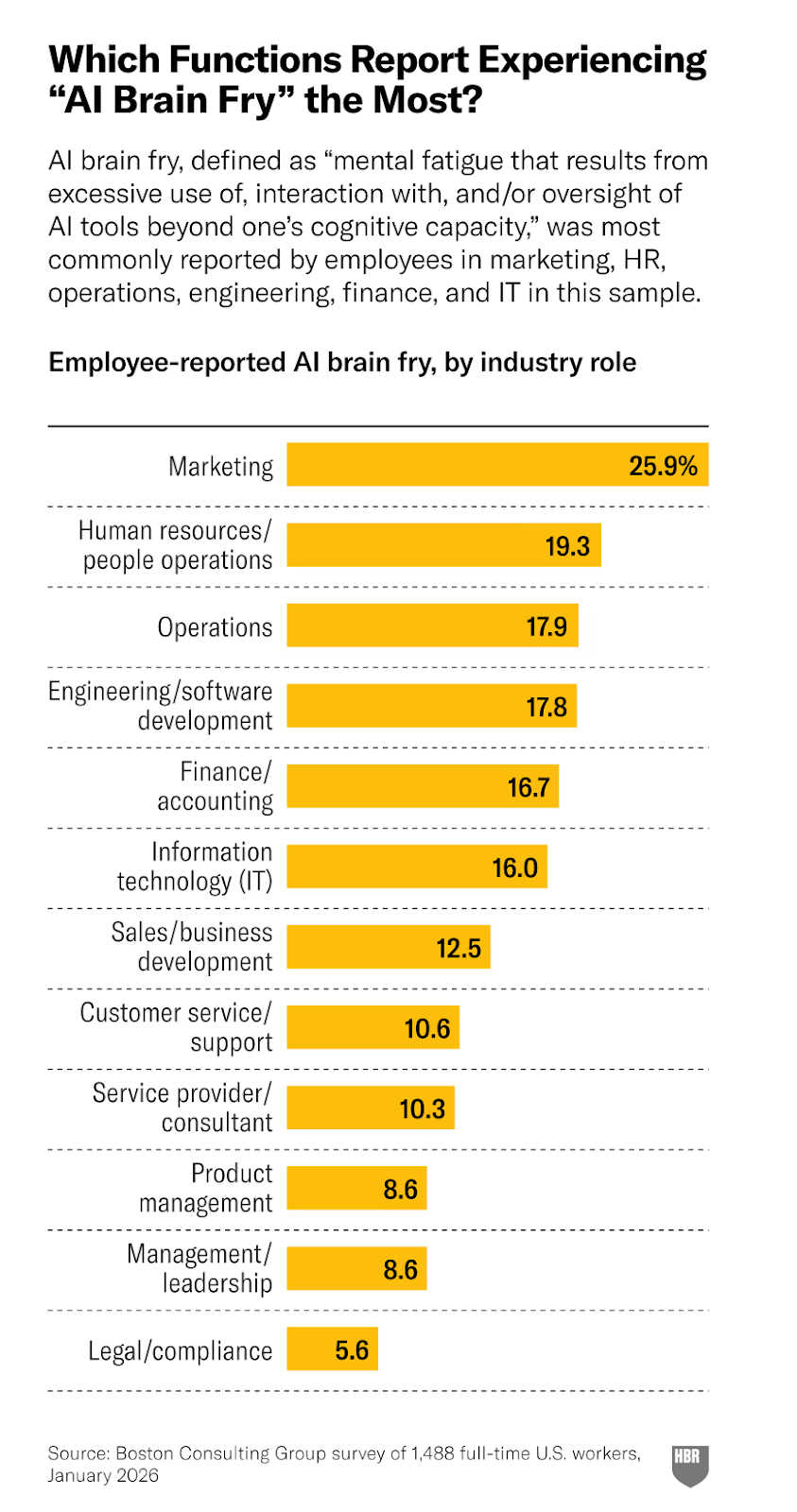
The research, conducted by the Harvard Business Review, revealed that 14% of US workers say that they are experiencing “brain fry” from AI use. This includes “mental fatigue that results from excessive use of, interaction with, and/or oversight of AI tools beyond one’s cognitive ability.”
The most affected group? Marketers.
One participant was quoted as saying, “I had one tool helping me weigh technical decisions, another spitting out drafts and summaries, and I kept bouncing between them, double-checking every little thing. But instead of moving faster, my brain just started to feel cluttered. Not physically tired, just… crowded. It was like I had a dozen browser tabs open in my head, all fighting for attention. I caught myself rereading the same stuff, second-guessing way more than usual, and getting weirdly impatient. My thinking wasn’t broken, just noisy—like mental static. What finally snapped me out of it was realizing I was working harder to manage the tools than to actually solve the problem.”
Regardless of where you stand on the AI debate, the study’s findings are interesting and worth paying attention to. How much AI is too much?
Weekly Homework:
- Explore adding a YouTube channel to your content marketing strategy or improving your existing channel.
- Log in to your Google Ads Merchant Center to see if you are eligible for CTV ads. This could expand your reach and introduce you to new audiences.
- Check your Meta Ads account to see if you are subject to the new fees and rates.
- Audit your influencer marketing pay process to make it more transparent and ethical.
- Consider whether you’re relying too much on AI, or if you’re a victim of “brain fry.” If you are, brainstorm ways to become less dependent on AI tools.
- Explore whether or not you want to add ChatGPT Ads to your strategy, specifically if you fall into one of the top 5 industries using them right now.
- Audit your SEO strategy to ensure that you’re also optimizing for AI bots.
Digital Marketing News 3/1/2026 to 3/6/2026
This week: TikTok dominates search behavior, ChatGPT carousels favor Google Shopping, WordPress vulnerabilities threaten sites.
Here's what happened this week in digital marketing:
1. Nearly 1 in 2 Consumers Use TikTok as a Search Engine
New data reveals that TikTok is still holding its own as a Google alternative.
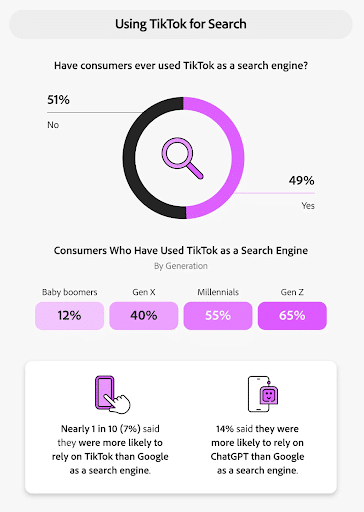
The Adobe study revealed that nearly 1 in 2 consumers (49%) use TikTok as a search engine. This is true across all demographics, including:
- 12% of Baby Boomers
- 40% of Gen X
- 55% of Millennials
- 65% of Gen Z
Other interesting data revealed that:
- 1 in 10 respondents rely on TikTok over Google as a search engine
- 14% said they were more likely to rely on ChatGPT than Google
- 38% of business owners use TikTok influencers for sales or promotions
- 38% of businesses plan to increase investment in TikTok affiliate marketing over the next year
If you want to learn more about TikTok and how brands are using it to expand their reach, read the entire Adobe report here.
2. ChatGPT’s Product Carousels Are Almost Entirely Powered by Google Shopping
A new study reveals that ChatGPT’s product carousels are overwhelmingly sourced from Google Shopping. Analyzing over 43,000 carousel products across 10 industry verticals, researchers found that more than 83% of carousel items appear in Google’s top 40 organic shopping results, while Bing accounts for just 11%, with almost no products unique to its index.
The study shows that ChatGPT favors higher-ranked Google products, with 60% of matches coming from the top 10 results and nearly 84% from the top 20. Shopping queries used to populate carousels are shorter and fewer than normal search queries, emphasizing that AI is pulling structured product listings rather than context-heavy web pages.
Why this matters: For brands and retailers, ranking well on Google Shopping is more important than ever. Products that appear near the top are far more likely to be featured in ChatGPT carousels, boosting visibility and potential traffic. Beyond rankings, overall product sentiment and online presence may also influence AI selection, making a holistic digital strategy essential.
3. TikTok Won’t Commit to End-to-End Encryption of Messages
Some users have been asking TikTok for end-to-end encryption of its messages, but the short-form video platform said no.
Users say that it will make the app safer, but TikTok said that its messages will remain protected with standard encryption and only authorized employees can access direct messages.
End-to-end encryption has been the default technology used for apps like Signal, WhatsApp, Facebook Message, Apple’s Messages, and Google Messages.
4. TikTok Experiences Second Outage Since Oracle Sale
There’s a lot of TikTok news this week! The US-arm of the social app experienced its second outage in the short time since Oracle took over this week.
While Oracle has not yet identified the cause of the outage, it left users feeling frustrated and annoyed, especially since this is the second time Oracle has contributed to a major TikTok outage in just a few months.
5. Google AI Overviews Move Beyond the First Page
It was previously thought that Google only pulled information for its AI Overviews from the first page of the SERP. New data has been released that shows that may not be true.
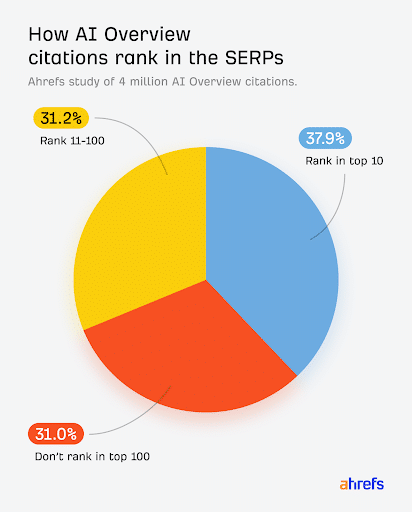
A recent Ahrefs analysis revealed that:
- 37.10% rank in the Top 10
- 26.2% rank in spots 11-100
- 36.70% don’t rank in the top 100
- 18% of non-ranking citations come from YouTube
What This Means: If you’ve been stressing out about ranking on page 1 with the end goal of ending up in an AIO, you might not need to. It seems that Google is considering a range of signals when creating the blurbs, and a single top-10 position appears to be the weakest.
6. New Google Patent Causes Confusion About AI-Generated Landing Pages
A new Google patent is causing a bit of an uproar in the digital community, with some people worried it will replace sites with landing pages.

This new patent describes a system that can generate a search results page tailored to each individual user, specifically for advertising purposes.
Some experts have been concerned that this means Google will create an entirely new landing page based on information Google finds on its SERPs. With that information, it could create an “updated search result page with a navigation link leading to this custom AI-generated page rather than the standard URL.”
However, a careful review of the patent shows that this is not true. While it’s true that the patent is about advertising, it goes on to explain that:
- “In some instances, the navigation link can be included in a sponsored content item.
- In some instances, the landing page score can be determined based on a conversion rate associated with the first landing page.
- In some instances, the AI-generated page can include a call-to-action button to a product page…”
- In some instances, the AI-generated page can include a product feed that provides an overview of a product…
- In some instances, the AI-generated page can include a sitelink to a product detail page.”
Why We Care: While we still aren’t exactly sure how (and if) Google will use this new technology it's working on, you can rest assured that Google isn’t going to create new AI-generated landing pages for your content if it feels the one you created isn’t good enough.
7. Google Ads API: Customer Match Uploads Ending for Inactive Tokens
Starting April 1, 2026, Google will block inactive developer tokens from uploading Customer Match data via the Google Ads API. If your token hasn’t been used for Customer Match uploads in the last 180 days, any attempt through the Ads API will fail.
Google recommends moving these workflows to the Data Manager API, a more secure, modern solution that offers features like confidential matching and enhanced encryption. Other Ads API functions, campaign management, reporting, and other tasks, will continue as usual.
Why it matters: Brands and agencies relying on Customer Match need to audit their developer tokens and migrate active workflows to the Data Manager API. Failing to do so will result in errors and failed uploads after the April 1 cutoff.
8. WordPress Faces a Number of Critical Vulnerabilities
If you’re a WordPress user, you'd better check on your site. Multiple critical vulnerabilities were announced this week, including:
- User Registration & Membership plugin: Installed on over 60,000 websites, this 9.8/10 vulnerability allows attackers to create administrator-level accounts and take over entire websites.
- Page Builder by SiteOrigin: Used on more than 500,000 websites, this 8.8/10 vulnerability requires the attacker to have Contributor-level access or higher, but once inside, they can upload files to the server.
- LatePoint - Calendar Booking: This 8.8/10 vulnerability makes it possible for attackers to gain elevated privileges by linking a customer to an arbitrary user ID and then resetting that user’s password.
How to Protect Your Site: Make sure all of your plug-ins are updated to the newest versions to help block out attacks.
9. Pinterest Releases Best Practices for Shopping Templates
Looking to increase your reach on Pinterest? Check out the platform’s new best practices.

The new guidance from Pinterest suggests:
- Putting templates at the center of your lower-funnel strategy
- Design for ideas, not just inventory
- Design scalable systems that allow for branding and offer updates
- Use Smartly to create pins people can’t resist
If you’ve been thinking of exploring Pinterest, this new release is a good place to start.
10. Google Updates Best Practices, Provides Clearer Guidance for Image SEO and Google Discover
Google updated its best practices for both image SEO and Google Discover this week.
The new documentation on Image SEO shares that marketers should:
- Choose an image that’s relevant and representative of the page.
- Avoid using a generic image (for example, your site logo) or an image with text in the schema.org markup or og:image meta tag.
- Avoid using an image with an extreme aspect ratio (such as images that are too narrow or overly wide).
- Use a high resolution, if possible.
The documentation for Google Discover image selection shared that “Google tries to automatically crop the image for use in Discover. If you choose to crop your images yourself, be sure your images are well-cropped and positioned for landscape usage, and avoid automatically applying an aspect ratio. For example, if you crop a vertical image into 16×9 aspect ratio, be sure the important details are included in the cropped version that you specify in the og:image meta tag).”
Be sure to catch up on the latest updates to Image SEO and Google Discover Image selection to keep your work aligned with the recommendations.
11. Google Releases Universal Commerce Protocol Help Page
In addition to updating various best-practice documents, Google also released new guidance on its Universal Commerce Protocol.
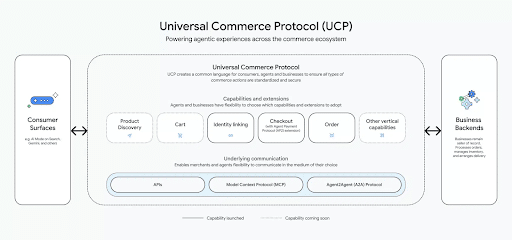
The documentation explains how UCP and UCP-powered checkouts enable a native Buy button that moves the transaction to Google’s services, even when the actual merchant remains the seller of record.
Why We Care: With formal documentation now available to the public, it’s clear that UCP is moving beyond a concept and becoming a core part of Google’s commerce strategy. This is important for all ecommerce sellers who want to reach new audiences on Google.
12. Google Says Frequent Crawling Is a Good Sign for Your Site
Google has published a new help document on how its crawlers work, aimed at educating site owners about the basics of web crawling. One key takeaway? Frequent crawling is a positive signal.
According to Google, if your site is crawled often, it usually means your content is fresh, relevant, and in demand. Ecommerce sites are a prime example, Google crawls them frequently to keep prices, promotions, and inventory status up to date in search results.
The document also covers other important points: how Google crawlers operate, respect site settings, repeat crawls to capture updates, and optimize crawling automatically as pages grow more complex.
Why it matters: Crawling is the foundation of SEO. Understanding how and why Google crawls your site can help you improve visibility and ensure your content shows up when users are searching. Frequent crawls are a sign that Google sees value in your site, so focus on keeping content fresh, structured, and crawl-friendly.
13. Consumers Spent 108 Billion Hours on Social Media in 2025
If you want to find your audience, chances are they’re on social media. A new study from eMarketer revealed that people worldwide spent 108 billion hours on social media apps last year.
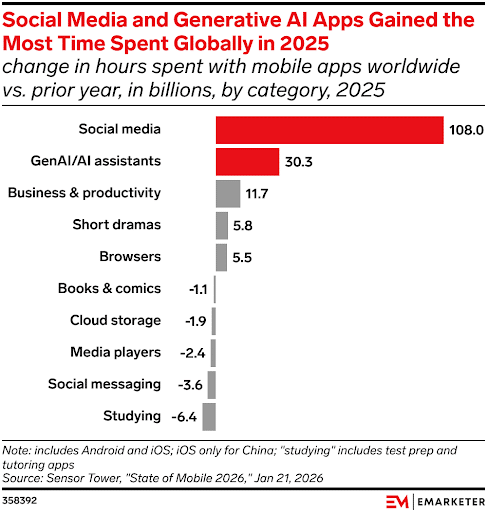
The apps that saw the most usage included:
- Social media - 108 billion hours
- GenAI/AI Assistants - 30.3 billion hours
- Business and productivity - 11.7 billion hours
- Short dramas - 5.8 billion hours
- Browsers - 5.5 billion hours
While the time spent on AI assistant apps increased 425% worldwide since last year, social media is still king.
Weekly Homework:
- Read through the Adobe TikTok report to get inspiration on how to use TikTok to expand your brand’s reach.
- If you have a WordPress site, make sure all of your plug-ins are updated to the latest possible version so you aren’t vulnerable to hacker attacks.
- Read through Google’s updated Best Practices for image search and Google Discover to ensure that your images are up-to-date and aligned with Google’s recommendations.
- Explore Pinterest’s newest best practices to see how you can improve the ROI of your Pins and Pinterest Ads.
Digital Marketing News 2/21/2026 to 2/28/2026
This week: OpenAI tests ChatGPT ads rollout, Google unveils Nano Banana 2, and TikTok dominates social growth metrics.
Here's what happened this week in digital marketing:
1. ChatGPT Ads Are Here
We’ve been talking about OpenAI adding ads to ChatGPT for a while now, and they’re finally here!
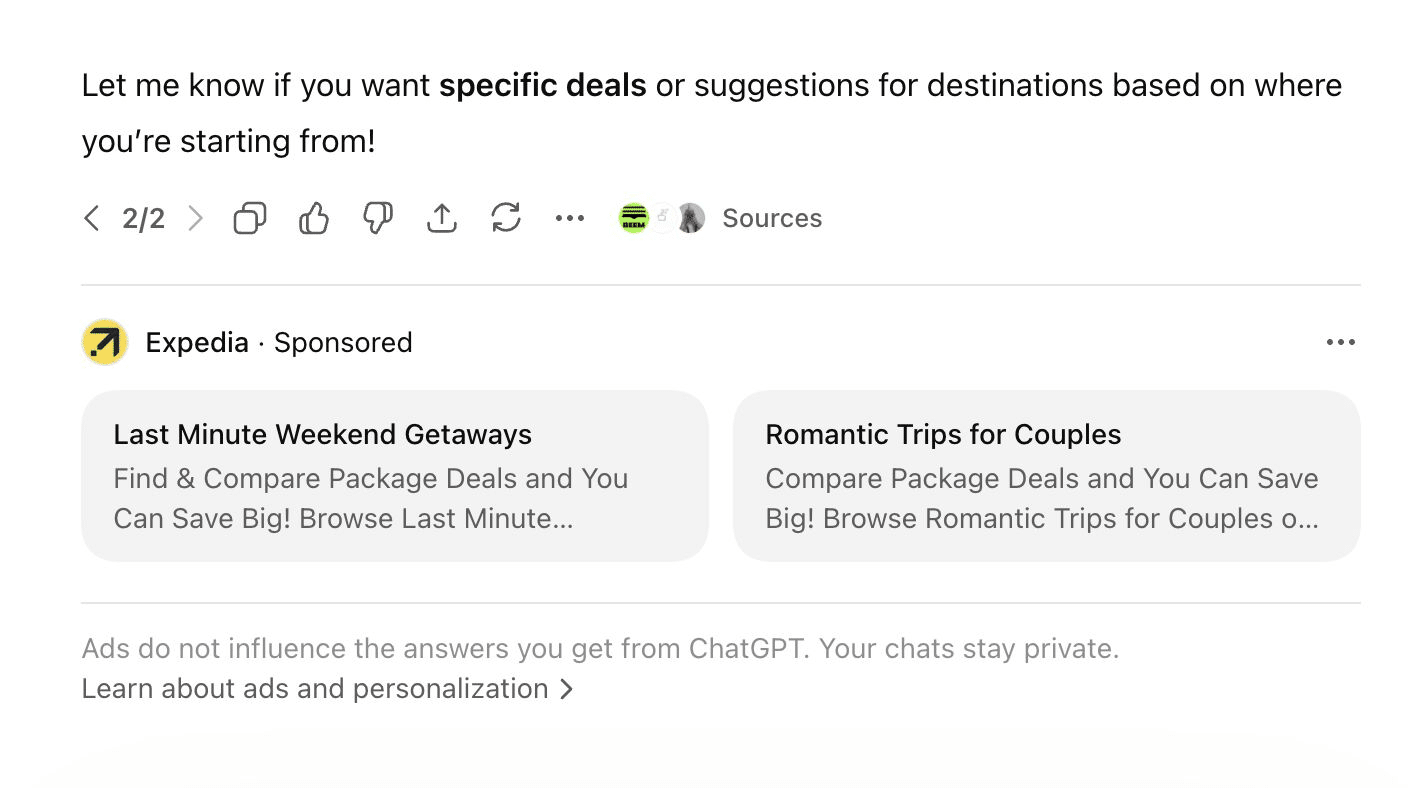
The ads feature a very prominent brand favicon and are clearly labeled as “sponsored” content, but it looks a little different than what OpenAI had said in the past.
Why We Care: Even if OpenAI decides that they don’t love the idea of offering ads and takes this opportunity back, they’ve opened Pandora’s Box. For marketers, that means considering yet another medium to add to their AI search strategies.
2. OpenAI Charges Premium Rates for Ad Space
Speaking of ChatGPT Ads, if you want to get a space, you’re going to have to pay for it.
OpenAI started rolling out ads to U.S.-based users, and reports are saying that they’re charging rates as high as $60 CPM, with a minimum buy-in of $200,000. If you don’t want to go directly through OpenAI, partners like Shopify are also offering advertisers the opportunity to test out the platform through Shop Campaigns.
While OpenAI’s COO Brad Lightcap says that adding ads to the platform will be “an interative process,” it’ll be interesting to see how the experience evolves the more brands –and consumers – are exposed to it.
3. Google Drops Nano Banana 2
Google just launched Nano Banana 2, a new AI image model that mixes Pro-level quality with super fast speed. It builds on earlier versions from Google DeepMind. You can now create high-quality, realistic images in seconds, without sacrificing detail or accuracy.

Key upgrades include:
- Smarter images: Uses real-world knowledge + live web data
- Better text in images: Clear writing + translation inside visuals
- Consistent characters: Keep the same look across scenes
- More control: Follows your exact instructions closely
- 4K-ready visuals: Perfect for ads, social, or websites
Bottom line: AI visuals are no longer “nice to have”. They’re becoming a core marketing tool.
4. Google Ads Support Issues New Requirements
If you want to contact Google Ads, you’re going to have to authorize support-led account changes before they can help you.
Advertisers are noting a new authorization button that gives a Google Ads specialist the ability to make changes to the account. The fine print? Google does not guarantee any results, and advertisers must be aware that any changes are made at their own risk – even if someone acting on behalf of Google is making the changes.
Why We Care: It’s not necessarily a bad thing, but it is important to note that you’ll be handing over control of your account while still keeping full accountability for what happens next.
5. No Sitemap Necessary? Google Says Maybe Not
We’ve been told for a long time that a valid sitemap is important for SEO, but now Google says that might not always be the case.
On a recent Reddit thread, a poster explained that “I’m encountering very tricky issue with sitemap submission immediately resulted `Couldn’t fetch` status and `Sitemap could not be read` error in the detail view. But i have tried everything I can to ensure the sitemap is accessible and also in server logs, can confirm that GoogleBot traffic successfully retrieved sitemap with 200 success code and it is a validated sitemap with URL – loc and lastmod tags.
…The configuration was initially setup and sitemap submitted in Dec 2025 and for many months, there’s no updates to sitemap crawl status – multiple submissions throughout the time all result the same immediate failure. Small # of pages were submitted manually and all were successfully crawled, but none of the rest URLs listed in sitemap.xml were crawled.”
Google’s John Mueller responded and said, “One part of sitemaps is that Google has to be keen on indexing more content from the site. If Google’s not convinced that there’s new & important content to index, it won’t use the sitemap.”
Interesting insight into the importance of a sitemap, especially if you aren’t producing content that Google finds important.
6. Brands Report Over 200% Increase in Followers on TikTok
A new study from Emplifi finds that brands are growing faster on TikTok than on any other platform.
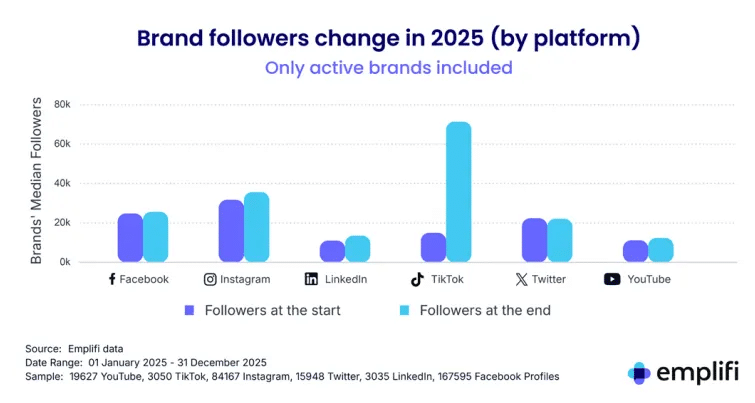
Emplifi’s 2026 Social Media Benchmarks report showed that:
- The average median followers on TikTok rose from a little under 20,000 to 65,000
- Median followers on Facebook, X, and YouTube remained relatively the same
- Median followers on Instagram and LinkedIn grew slightly
TikTok didn’t just see an explosion in median follower count. It also took over for median interaction and engagement, as well as organic reach.
You can find out more about what Emplifi discovered, including which types of posts performed the best, by downloading the entire report here.
7. Meta: Meet Graph API v25.0 and Marketing API v25.0
Meta announced some big changes and updates to its Graph API this week.

In the announcement, Meta shared that “[b]y the end of June 2026, we plan to introduce Page Viewer Metric in the Graph API. Viewers metric is intended to replace the legacy reach metric and provide a consistent cross-platform measurement (Facebook and Instagram) of how many people saw a piece of content.”
There are additional technical changes, as well, making it incredibly important that Meta marketers who use third-party apps and tools make sure that they are using the latest versions of Meta’s AI tools, especially when using Advantage+.
8. Pinterest Says “Screen Free Activities” Search is Up Over 200%
If your brand is in the parenting space, you might be interested in these recent findings published in Pinterest’s first-ever Parenting Trend Report.
In addition to searching for “screen free activities” and “family tradition ideas,” parents are also searching for:
- Educational activities +280%
- Outdoor learning +65%
- Family Trip Vision Board +545%
- Life Skills Activities for Kids +100%
In addition to looking for activities and opportunities, 64% of parents say they use Pinterest monthly to research products before making a purchase.
9. 40% of US Consumers Say They’re Looking for a Deal
If your sales have been slow, you’re not alone! A new article from Marketing Dive found that nearly 40% of U.S. consumers say they’re only buying things on sale, using coupons or discount codes, or are cooking at home.
Although December retail sales rose by more than 4% when compared to the same period last year, major economists are saying to expect the 2026 consumer to be “functional but fragile.”
It’s a common belief that this is due to the K-shaped economy, but other global issues also play a role.
Why We Care: If you’re going to stand out in a shaky economy, you need to make it count for your consumers. If sales are slow, consider offering coupons or discount codes to encourage consumers to return to you.
10. 67% of Consumers Say Brands Value New Customers More than Existing Ones
Speaking of inspiring consumers to come back to you, a new survey by GetResponse revealed that two-thirds of loyal customers don’t think they matter to brands as much as new consumers.
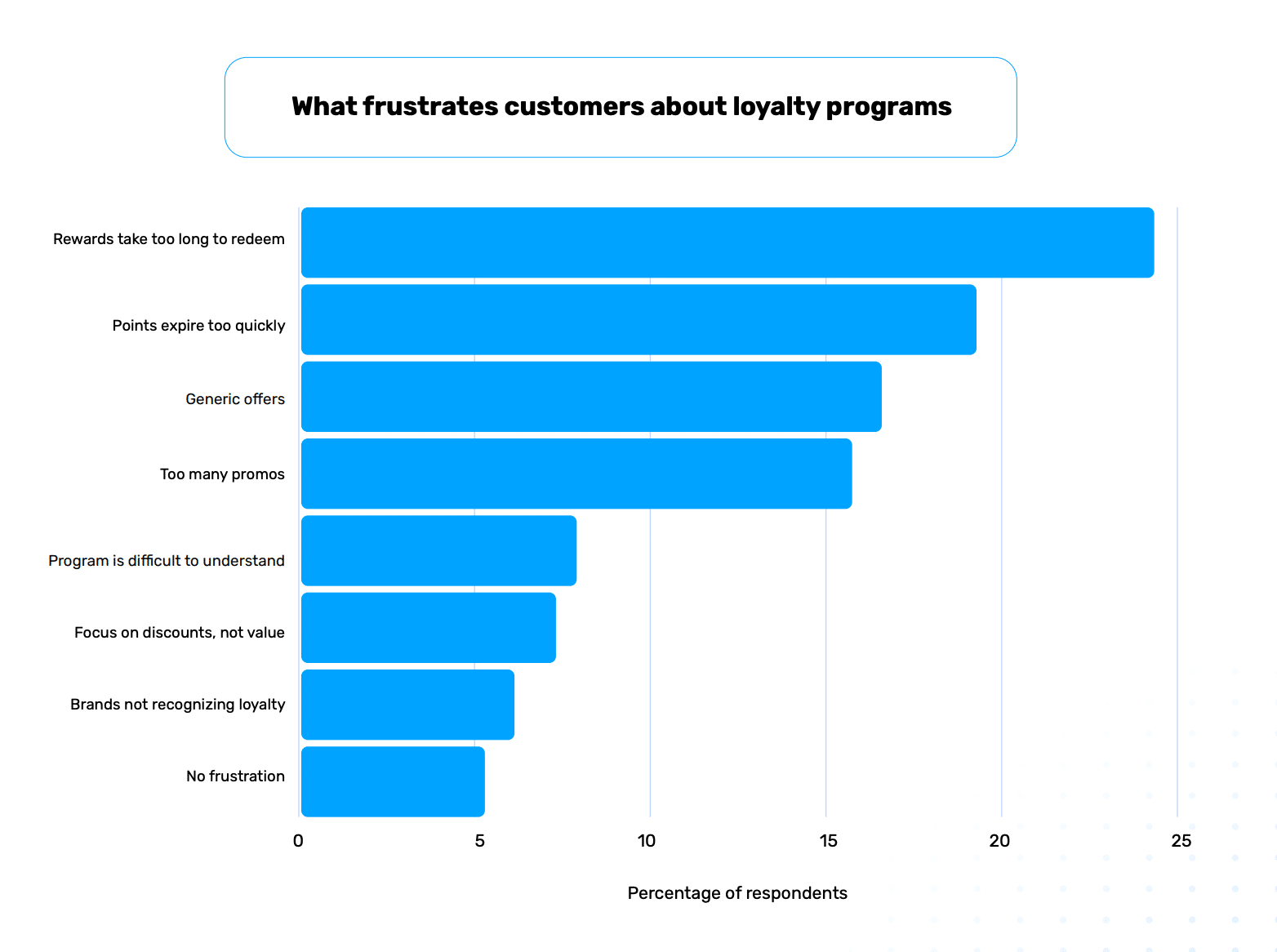
While loyalty programs are great, the consumers surveyed said that they get most frustrated by:
- How long it takes to earn rewards to redeem
- Points expiring too quickly
- Generic offers that aren’t customized to their needs
- Too many different promos
The report revealed a lot of interesting information, so if boosting your loyalty program is on your 2026 to-do list, download it and see how you can use this information to improve your program and keep your customers coming back for more.
11. Apple Rolls Out Age Verification Tools
In an effort to stay ahead of global child safety laws, tech giant Apple has rolled out a new suite of age-verification tools.
These new tools will determine the user’s age range without accessing important personal information, such as the date of birth. From there, they will block certain sites and downloads deemed not child-friendly.
The new changes are already live in Brazil, Australia, and Singapore, with additional features being developed to comply with laws in Utah and Louisiana. Safety features being developed in Texas have been put on the back burner while litigation plays out.
Why We Care: If kids and teens are your prime target audience, you’re going to need to make sure your content is kid-friendly enough to not get blocked by these new tools.
Weekly Homework
- Are you looking to grow quickly on social media? Download Emplifi’s newest social media benchmark report to learn what apps are working best.
- If you’re using third-party apps for your Meta Ads, make sure they are compatible with the new upgrades to the technical backend.
- Is your loyalty program failing? Read the new report from GetResponse to get ideas on how to make it more consumer-friendly.
- Interested in how to reach more people in the parenting space? Download Pinterest’s new parenting report for valuable insights.
Digital Marketing News 2/14/2026 to 2/20/2026
This week: Google Ads re-enable paused keywords, Perplexity AI drops ads for accuracy focus, Apple Podcasts expands into video.
Here's what happened this week in digital marketing:
1. Meta Launches Manus AI – a New Advertising Tool
Have you noticed something new on your Facebook page? Meet Manus AI, a new tool to improve advertising.
Meta believes that this new tool will improve your Meta Ads by:
- Uncovering new insights through research
- Generated reports with in-depth analysis
- Scheduling recurring tasks to save time
The jury is still out on whether this will actually improve Meta Ads, but it’s worth experimenting with. You can access Manus AI in your Meta Ads Manager under the Tools listing.
2. Pinterest Hits 619 Million Monthly Active Users
If you’ve been looking for an additional way to reach your audience, Pinterest might be the platform you’ve been looking for.
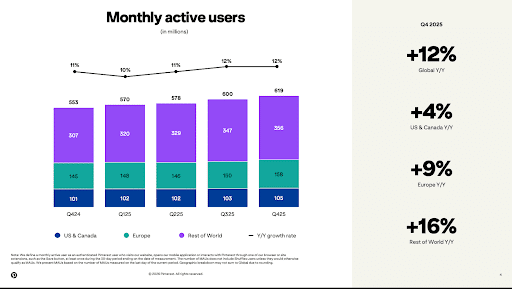
According to its latest quarterly earnings report, the site is up to 619 million monthly users, up from 553 million in Q424. This number accounted for year-over-year growth, including:
- 12% overall
- 4% in the US & Canada
- 9% in Europe
- 16% in the rest of the world
Other notable statistics include:
- 14% increase in year over year global revenue to $1,319 million
- 42% increase in global average revenue per user
- 64% increase in global monthly revenue
Why We Care: There’s always a race to find a new and exciting way to reach your audience when typical marketing platforms start to become too convoluted. With rising numbers like these, Pinterest could be your next opportunity.
3. Google Ads Automatically Re-Enabling Paused Keywords
Are you seeing unexpected campaign expenses? It could be because Google Ads automatically re-enabled paused keywords for some advertisers without notice.

Some advertisers reported seeing entries tied to “low activity system bulk changes.” The entry in the log appears as an automated bulk update with a visible Undo option.
This unexpected reactivation could result in unwanted impacts to:
- Campaign delivery
- Budgets
- Ad pacing
- Performance
Why We Care: This could significantly impact your well-strategized Google Ads campaigns. Make sure to check your dashboard to see if you’re affected.
4. Google Shares More Campaign Guidance
There are a lot of strong opinions out there about campaign and ad group consolidation, and Google has finally weighed in.
On a recent episode of Google’s Ad Decoded podcast, Brandon Ervin, Director of Product Management for Search Ads, shared that: “the big shift we’ve seen with the rise of Smart Bidding and AI, the machine in general can do much better than most humans. Consolidation is not necessarily the goal itself. This evolution we’ve gone through allows you to get equal or better performance with a lot less granularity.”
With Google’s algorithms constantly evolving and new tools coming onto the market, Google emphasized that advertisers should continually evaluate whether their current ads structure still supports their goals, or if they should switch it up. Regardless, keep in mind that while you don’t necessarily need to consolidate campaigns, you should try to reduce unnecessary structural complexity.
5. Roku Video Advertising Grew 18% since 2025
According to Roku's recent earnings statement, video advertising revenue grew to $4.15 billion in 2025.
The report also included other interesting stats, such as:
- Streaming hours increase 15% to 145.6 billion
- Roku Channel was the #2 app for engagement in the US, second to YouTube
It also talked about how Jennifer Aniston’s haircare brand, LolaVie, selected Roku as its first CTV partner. That campaign contributed to a 40% lift in sales and a 53% YoY increase in new customers.
Why We Care: CTV is a growing advertising medium, and depending on your brand’s goals, it may be worth exploring its opportunities in 2026.
6. Perplexity Abandons Advertising Testing
ChatGPT may be jumping into the ads game, but Perplexity is leaving. The AI platform announced this week that it is abandoning its current ad testing program.
Testing began in 2004, but Perplexity has since discontinued the test. One executive said, “A user needs to believe this is the best possible answer,” and having ads appear could make them question the platform’s integrity.
The platform will continue rolling out shopping features, but it won’t take a cut of sales. Another executive was quoted as saying, “We are in the accuracy business, and the business is giving the truth, the right answers.” Instead of generating revenue from ads and sales, the platform earns profits from subscriptions priced from free to $200 per month.
Although OpenAI is testing ads in ChatGPT and Google runs ads in AI Mode and AI Overviews within Search, Perplexity isn’t the only platform to swear off ads. Anthropic has said that Claude will remain ad-free.
7. YouTube Ads Auto Captions to Muted Videos
A lot of video creators add captions to their videos to improve accessibility, but if you don’t, YouTube will now do it for you.
In a recent video, the video platform announced that a new playback function will automatically switch on captions whenever a user mutes their device, saying that “When the user unmutes their device, captions are turned off. This is not currently available for Shorts. The setting is turned on by default for all users. However, you can turn it off in the caption settings.”
While this is great news for accessibility, it’s also good news across the board, as many people watch videos without sound. The auto-captions will make it easier for viewers to follow the content without the creator having to add them to the video manually.
In the same announcement, YouTube also unveiled a new profile animation feature, new options and features for paying subscribers, and improved AI personalization tools.
8. TikTok Joins European Advertising Standards Alliance
If you’re using TikTok to reach European audiences, listen up! TikTok has officially signed the European Advertising Standards Alliance (EASA).
The alliance provides guidance to advertisers on how to be “legal, decent, and truthful” with their advertisement campaigns. EASA also states that “member ads should be ‘prepared with a sense of social responsibility and created with due respect to the rules of fair competition.’”
In a press release announcing the signing, TikTok stated, “Joining as a Full Member, TikTok will support 28 advertising self-regulatory organizations across Europe, formalizing its contribution to advancing industry-wide standards globally.”
While it’s big news that will help keep TikTok in Europe without having to sell the company as it did here in the US, it’s also important for advertisers to ensure they follow EASA guidance if they want to advertise on TikTok in Europe.
9. Changes Are Coming to Google’s AI Overviews
Google is changing up AI Overviews and AI Mode. In a new release this week, Google announced it will add link pop-ups to AI Overviews and AI Mode when viewed on desktop.
Robby Stein, VP of Product for Google Search, announced this week that the redesigned link experience will be added to AI Overviews and AI Mode on desktop.
As more companies worry about zero-click searches, this could be a way to regain some of the traffic they've lost.
10. New Video Experience is Coming to Apple Podcasts
Apple Podcasts is getting into the short-form video game. The popular audio platform announced that it will launch a new video experience this spring.
Recent research shows that 51% of the U.S. population has watched a video podcast, and 37% consume this type of content monthly. Apple wants to capitalize on this by adding a video component to its popular audio-only platform.
In the announcement, Apple’s senior vice president of Services, Eddy Cue, said, “Twenty years ago, Apple helped take podcasting mainstream by adding podcasts to iTunes, and more than a decade ago, we introduced the dedicated Apple Podcasts app. Today marks a defining milestone in that journey. By bringing a category-leading video experience to Apple Podcasts, we’re putting creators in full control of their content and how they build their businesses, while making it easier than ever for audiences to listen to or watch podcasts.”
While it won’t officially launch until spring, some users will start seeing the beta version on iOS 26.4, iPadOS 26.4, and visionOS 26.4 this week.
Why We Care: If you’re already producing video podcast footage for other platforms, it would make sense to explore the opportunities to reach your audio audience on Apple Podcasts, too.
Weekly Homework
- If you’re a Meta Ads user, check out the new Manus AI tool to see if it could help streamline your ad experience.
- As Pinterest continues to grow, it may be worth considering adding the platform to your social media marketing strategy. Check out the options to see if it might be a good fit for your brand.
- Log in to your Google Ads account to make sure your keywords haven’t been automatically unpaused.
- Explore the option of adding CTV ads through Roku to your marketing strategy in 2026.
- If your brand has a podcast, consider adding a video component to take advantage of Apple Podcasts’ upcoming video experience.
Digital Marketing News 2/7/2026 to 2/13/2026
This week: Google rolled out a Discover-focused Core Update, OpenAI officially began testing ads in ChatGPT, and Bing introduced a new AI citation report to track visibility in generative answers.
Here's what happened this week in digital marketing:
1. Google’s Core Update Targets Discover Feed
Google launched its February Discover Core rollout late last week.
Expected to take two weeks to complete, the update addresses user experience by:
- Showing more locally relevant content
- Reducing sensational content and clickbait in Discover
- Showing more in-depth, original, and timely content from websites with expertise
- Showing more content that is personalized based on the users’ creator and source preferences
As with any Core Update, it may cause traffic fluctuations, but they should all shake out eventually. The update is currently being released to English language users in the US and will expand to all countries and languages within the next few months.
2. Google Revises Discover Guidelines
In addition to launching the Discover Core Update, Google also revised its “Get on Discover” documentation. Google Revises Discover Guidelines Alongside Core Update
The update includes ways to increase your likelihood of being featured on the Discover page, including:
- Avoiding clickbait and similar tactics
- Using page titles and headlines to capture the true essence of your content
- Avoiding sensationalism that caters to morbid curiosity, titillation, or outrage
- Providing content that is necessary and timely
- Including compelling, high-quality images within the content
- Providing an overall great page experience for the reader
Why We Care: Any time you can improve your content and get it in front of more people, the better! Following these tips from Google could help you maximize your reach and find new audiences.
3. OpenAI Ad Testing Starts
If you use ChatGPT’s U.S. free or Go subscription tiers, you should start seeing ads soon. OpenAI announced this week that it has started testing sponsored content.
Here’s some information you should know:
- Ads will not be shown to users under 18 years of age
- Ads are not eligible to appear near sensitive or regulated topics like health, mental health, or politics
- Not everyone is allowed into the advertiser program
- Chats will remain private and never be shared with advertisers
- Ads will be shown depending on what you’re discussing, ads you’ve previously engaged with, or your past chats or memories
OpenAI is also giving users control over the ads they see inside the program. Users will be able to access their ad history, share interests, and opt in to (or out of!) personalized ads based on past chats and memories.
4. Meta’s Marketing Messages API Ended This Week
If you used Meta’s Marketing Messages API to send follow-up messages, you’ll need to find another way. The social media giant discontinued the ability to send these messages on February 10th.
In the discontinuation announcement, Meta shared that “Marketing messages (also known as recurring notifications) lets businesses send promotional content to opted-in users via Messenger. This feature on Messenger API will go away on 10 February 2026.”
Users will now only be allowed to send one message per subscriber every 48 hours. Access will also be limited to existing partners and businesses. No new integrations will be allowed.
If you’ve been using this tool, click here to catch up on the news, as well as learn what to do next.
5. U.S. TikTok Addresses Privacy Concerns
When the new U.S. TikTok deal was announced a few weeks ago, many users became concerned over the updated privacy settings. The TikTok U.S. has finally addressed these concerns.
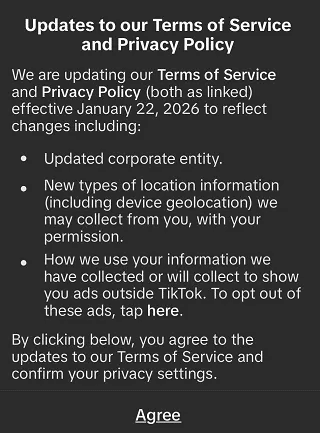
In a press release late last week, TikTok U.S. said: “Our U.S. Privacy Policy aligns with data privacy laws, mirroring language used in state laws like the California Consumer Privacy Act (CCPA). These laws require companies to describe broad categories of personal information that could be processed, including when that information is shared voluntarily by you - for example, in the content you post to platforms. When you voluntarily post to TikTok, we process the information you share, and we're required by law to tell you this. TikTok has included this type of language in its privacy policy since 2024, and similar language appears in the privacy policies of other platforms subject to the CCPA.”
To make a long story short, there isn’t much need to be concerned. What TikTok U.S. is doing is consistent with other social media platforms, with no new requirements to allow the app to track you and your location.
6. TikTok U.S. Launches Local Feed
So you don’t have to provide your precise location data, but if you want to, you’ll gain access to TikTok U.S.’s new and improved Local Feed.
Already active in select European markets, including the U.K., France, Italy, and Germany, the new hyper-local feed is designed to help users stay connected to their local community and discover new opportunities.
This feature will be available only to users aged 18 or older and will collect information only when the app is in use. From that data, the feed will be curated to include recommendations for new restaurants, local events, shopping, and more. With 84% of small-business users on TikTok reporting that the platform has already helped them grow their brand, this could be an excellent opportunity.
Why We Care: If you’re a small business looking to boost your local foot traffic, this could be an incredible opportunity for you to expand your reach with new customers.
7. TikTok Launches New Enhanced Shops Promotion Program
A new seller program is coming to TikTok! The short-form video platform announced that the Smart Promotion Program, launched last month, will replace the existing Co-funded Promotion Program.
Smart Promotion Program registrants can expect:
- Point rewards to improve conversion and repeat purchasing rates
- Transparent fee structure
- Guaranteed ROI through February 28, 2026
- Enhanced product exposure through pop-up messages and surprise placements
- And more
Those monetizing their TikTok can learn more about this program, including who is eligible and how to enroll here.
8. Amazon Enables Communication Between AI Agents and Amazon Ads API
Amazon is testing a new platform to improve its ad offerings.
This best test integrates Amazon Ads with a range of AI agents to improve campaign integration and streamline ad creation. According to the mega-retailer, the new Amazon Ads MCP Server is built on the Model Content Protocol, an open standard that will allow AI platforms to communicate with external tools.
Paula Despins, Vice President of Ads Measurement at Amazon Ads says that it will “act as an instruction manual for AI agents to turn the complex, multistep operations of advertising workflows into simple actions that can be handled through natural language prompts. For example, if an advertiser is running campaigns in the U.S. and Canada, we have a tool that enables them to quickly expand it to another country with a single prompt.”
Why We Care: If you’re an Amazon Ads user, being able to launch different campaigns in different countries with just a click of a button could really boost your bottom line.
9. Bing Webmaster Tools Adds AI Performance Report
A new performance report has come to Bing’s Webmaster Tools. Launching in beta, this report will help you see where and how often your content is cited in AI-generated answers across the Microsoft ecosystem.
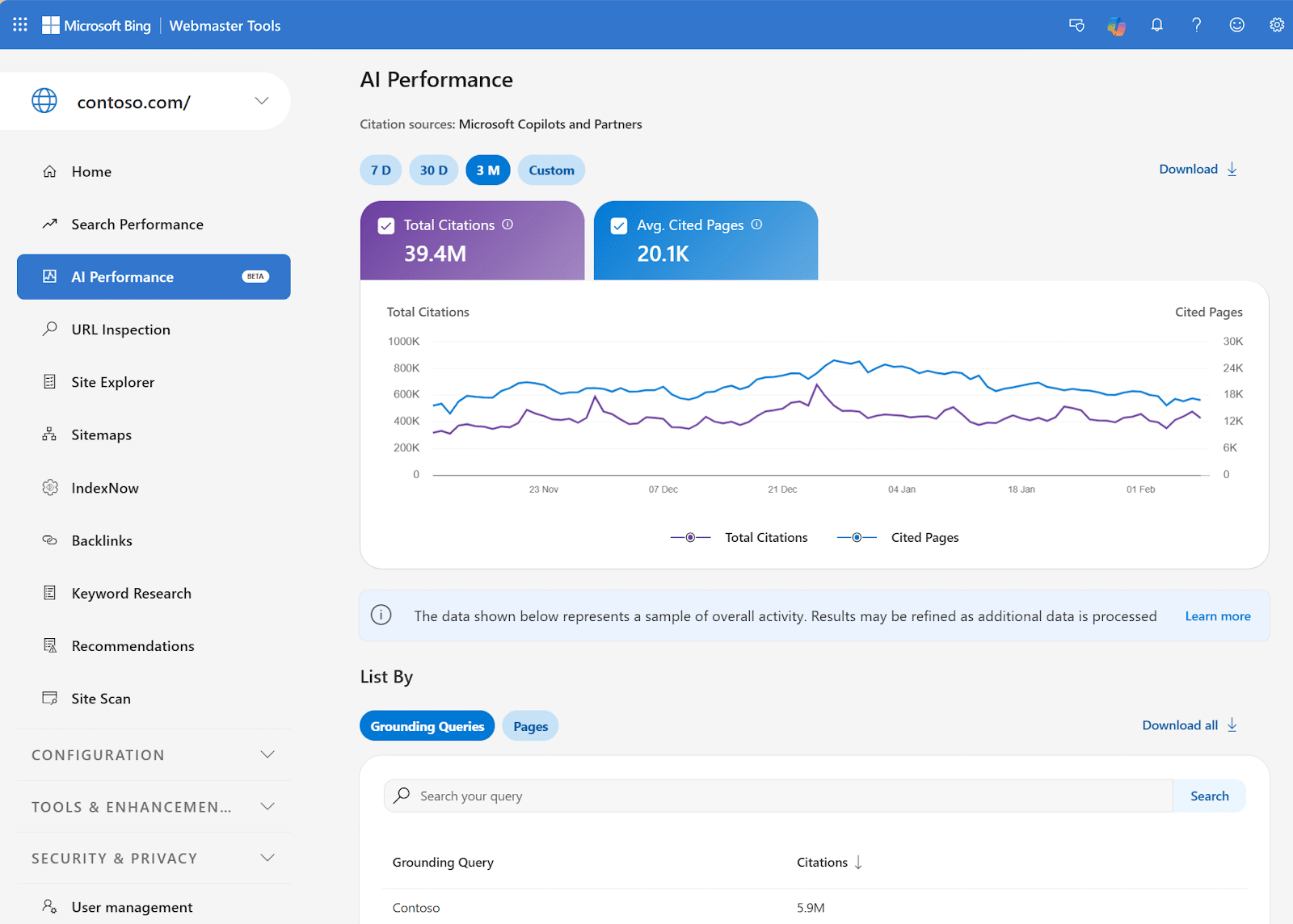
The new report will detail where and how often your content appeared across Microsoft Copilot, Bing’s AI summaries, and select partner integrations. The tool will show you:
- Which URLs were cited
- Which queries triggered those citations
- How citation activity changed over time
While these metrics only show citation frequency, Microsoft says it's working on expanding the tool to show ranking, prominence, and how a page contributed to a specific answer. Armed with this knowledge, content creators can be more specific in their content to provide the exact answers AI bots and human users are seeking.
10. Reddit to Expand AI Search Capabilities
Reddit announced strong fourth-quarter and full-year 2025 revenue, but the improvements appear to be continuing for the forum website.

With a record-breaking 471 million weekly active users, Reddit is looking to expand its hold on the search ecosystem with new AI-powered search tools.
In addition to its current tools and ad offerings, Reddit is working to integrate AI and new entry points into its search to increase search volume and queries per user. The platform is also working on enhancing its internal and external search displays.
2025 was the year for Reddit Ads. Could 2026 be even better?
Weekly Homework:
- Monitor your Google Analytics to see if your site is impacted by the February Core Update.
- Review the new updates to the Google Discover documents to ensure that your content is aligned with the new rules.
- Decide if advertising on ChatGPT is something your team wants to explore in the future.
- If you have been using Meta’s Recurring Marketing Messages API, make sure you have plans to support your marketing efforts without the feature.
- Explore TikTok’s new Local Feed opportunity and the enhanced Shops Promotion Program to see if either of the updates could be an opportunity to expand your brand’s reach.
- Check out your Bing Webmaster Reports to see if your content is gaining traction in the Microsoft AI ecosystem.
Digital Marketing News 1/31/2026 to 2/6/2026
This week: Firefox handed users full control over browser AI, Google cracked down on SEO shortcut listicles, and ChatGPT revealed a high-stakes, invite-only ad rollout.
Here's what happened this week in digital marketing:
1. Want to Block AI Features? Firefox Says Okay
AI usage in internet browsers has been a major topic of conversation, with some consumers fully on board and others highly annoyed. In a recent announcement, Mozilla shared that Firefox will soon let its users block all current and future AI features.

The announcement shared that “AI is changing the web, and people want very different things from it,” the company wrote in a blog post. “We’ve heard from many who want nothing to do with AI. We’ve also heard from others who want AI tools that are genuinely useful. Listening to our community, alongside our ongoing commitment to offer choice, led us to build AI controls.”
This opt-out opportunity will begin on February 24th, when Mozilla releases Firefox 148.
Why We Care: If other browsers follow suit, it could reshape AI search strategies and make traditional SEO strategies more valuable again.
2. SaaS Brands See 30-50% Visibility Drops on “Best Of” Listicles
Are you a big fan of “best of” listicles? Google might not be!
After the December 2025 core update, some well-known SaaS and B2B brands observed a 30-50% drop in organic visibility, particularly in blog, guide, and tutorial subfolders. The most common drops occurred on self-promotional listicles in which the publisher ranked itself first.
While this could change as volatility from the update levels out, it’s important to note that it may also indicate that Google is reevaluating how it treats “best” content.
The best way to get ahead of this? Don’t take SEO shortcuts. Ranking yourself first without any third-party testing or clear evidence of peer or consumer evaluation will fall short.
3. Google Says: 2 Mistakes Cause 75% of Crawling Issues
Every marketer wants to know how to improve Google's crawl of their site. In Google’s 2025 year-end report, Gary Illyes revealed that most crawling issues stem from two specific issues.

Here is what the report found:
- 50% come from faceted navigation, such as sites that create near-infinite URL combinations
- 25% come from action parameters
- 10% come from irrelevant parameters, such as session IDs, UTM tags, and other tracking parameters appended to URLs
- 5% come from problematic plugins or widgets
- 2% come from other “weird stuff,” such as double-encoded URLs and related edge cases
These are all pretty common mistakes, so be sure to check your site to see if you’re making them.
4. LinkedIn Offers Insight on AI Search Visibility
LinkedIn recently did an internal study on what drives visibility in AI-generated search results, and the results may be helpful for you – both on LinkedIn and off.

The results revealed that:
- Non-brand driven-traffic has dropped 60%
- Click-through rates have dropped
- Up to 60% of searches in the US/EU are zero-click
In a response to the results, LinkedIn is telling its users to:
- Focus on accessibility in their content
- Understand that early visibility compounds
- Keep publishing authoritative content to improve visibility
- Lean into cross-functional content
- Remain consistent with their content production
- Stay agile and continue to test and refine content strategies
- Keep a pulse on their industry
As LinkedIn says, “We are moving away from 'search, click, website' thinking toward a new model: Be seen, be mentioned, be considered, be chosen.”
You can read more about the findings and how you can adapt to them here.
5. WordPress Updates Guidelines to Counteract AI
Like many technology companies, WordPress is working to counter AI adoption. This week, it published new AI guidelines intended to encourage responsible use and prevent the internet from becoming AI slop.
While the guideline release goes into more specific detail, the five biggest takeaways include:
- Produce your own content. AI can help, but it shouldn’t be a contributor.
- Disclose meaningful AI assistance.
- All contributions must be compatible with GPLv2-or-later, including AI-assisted output.
- Non-code assets (docs, screenshots, images, and educational materials) also count.
- Choose quality over volume.
Basically, it’s what we’ve been saying all along: Use AI as a tool, but not as your total creative process.
You can catch up on all of the nitty-gritty details here
6. ChatGPT Advertisers Asked for $200k Spending Commitments
We reported last week that OpenAI will soon be adding ads to ChatGPT. This week, we know how much that will cost advertisers: $200,000 in early commitments.
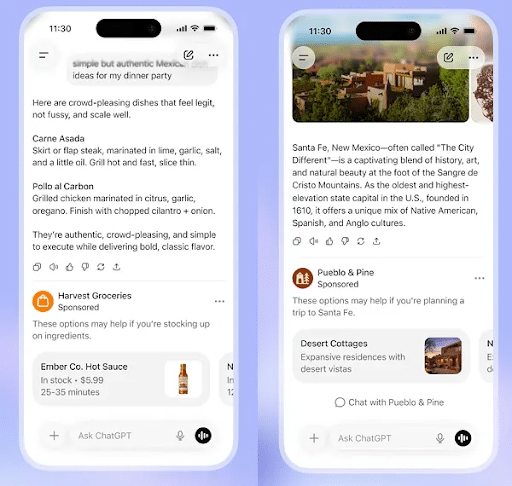
This is according to an AdWeek article, which reports that four brands said they were approached to join the tightly controlled beta test for ChatGPT ads and were offered a spot in exchange for future commitments of $200,000.
It’s still too soon to know exactly how ads on ChatGPT will play out, or whether they will become more affordable for brands unwilling to commit much of their marketing budget. But with so many people using ChatGPT, it’s still a good idea to keep your eye on the platform as a future marketing option.
7. TikTok Reaches 90 Million Daily Active Users
Last week, we reported that many US users were leaving TikTok in an apparent protest of the US ownership change. This week, the numbers show that many of those users came back.
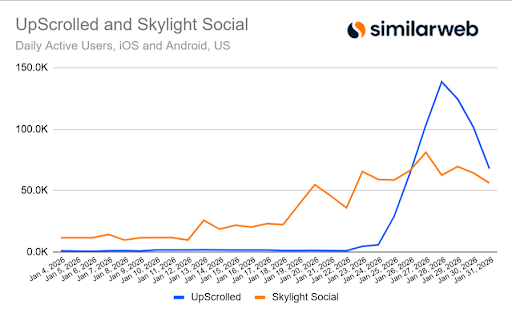
Typically, TikTok sees about 92 million daily users. After the announcement that the US deal was closed, it dropped to about 86 million daily users. While downloads of alternative apps like Skylight Social and Upscrolled took off.
In the days after that report, UpScrolled's active users have plummeted, and Skylight Social is also declining. On TikTok, however, metrics are improving, with the app recently reaching 90 million daily active users.
While it might be a good idea to still hold onto your brand’s handles on those alternative apps, it looks like TikTok might weather this storm and continue to be a key tool in the social media marketing toolbox.
8. X Is In Hot Water with French Authorities
X is in the news again – and not necessarily in a good way. French authorities reported that they have raided X's Paris offices as part of a year-long investigation into the social media platform.

According to Europol: “An investigation led by the French authorities is currently underway concerning the online platform X, in relation to the proliferation of illegal content, notably the production of deepfakes, child sexual abuse material, and content contesting crimes against humanity. The investigation is conducted by the Paris Public Prosecutor’s Office with the support of the French Gendarmerie’s cybercrime unit (UNCyber) and Europol.”
X issued a statement on their platform saying that the investigation is “politically motivated.”
France isn’t the only government taking a look at X. The U.K. Information Commissioner’s Office (ICO) also announced a formal investigation into the platform and its processing of data for the Gork AI chatbot on the same day as the Paris raid.
Why We Care: No matter how these situations play out, it’s a good reminder that, as marketers, we need to diversify our marketing efforts. While it’s good to stay current with popular apps, it’s even more important to have a content strategy with multiple touchpoints. This way, if you lose connection with one, you still have many other ways to reach your target audience.
9. The Winter Olympics Are Starting and Brands Are Ready
With the Winter Olympics starting this week, many brands are looking to make the most of this global event.
According to eMarketer:
- 67% of millennials say it's important or very important for brands to get involved with large cultural events like the Olympics or the Super Bowl
- Worldwide media ad spend will reach $1.15 trillion, a 10% increase over last year
- NBCUniversal will cash in the most, with the Olympics and the Super Bowl being held on the same Sunday for the first time in years
- US CTV Ad spend will reach $37.95 billion, a 14.5% increase
- YouTube is expected to see a boost in viewership, too, with 17% of all Summer Olympic watchers engaging with the event on the video platform
Why We Care: A lot of marketers will be looking to make a splash at this year’s Olympics. It could be an inspirational gold mind – or a stark reminder of what not to do.
10. Get Ready for Those Super Bowl Ads
Speaking of an inspirational gold mind, the Super Bowl is also coming up this weekend, and you know what that means: promotional content the internet will be talking about for days!

Everyone from Nerds to Squarespace is looking to make a splash during this year’s big game. If you’re more interested in the promotional content than who wins the Seahawks vs. Patriots showdown, you can follow along with what content is performing well (and which content isn’t!) on Marketing Dive’s Super Bowl 60 Ad Tracker.
Why We Care: No matter your industry, we can learn a lot about our target markets and overall consumer attitudes from how they react to Super Bowl ads. Which ones go viral and which ones flop could give some insight into how to run your own campaigns. And who knows, you might even get some inspiration!
Weekly Homework:
- Check your site rankings to see if you were negatively affected by Google’s December 2025 Core Update.
- Watch or listen to Google’s recent podcast to see if your site is making any of the most common crawling errors. If you are, log into the backend of your site and fix them!
- Read through LinkedIn’s findings on how to boost your visibility in an AI-driven world.
- Get ready to get inspired (or turned off) by big-name brands during the upcoming Winter Olympics and the Super Bowl.
- If X is a significant part of your marketing strategy, you might want to monitor its recent UK and France-related issues closely.
Digital Marketing News 1/24/2026 to 1/30/2026
This week: TikTok’s U.S. deal is done, Google search volumes fell nearly 20% year over year, and AI-driven traffic delivered massive gains across holiday shopping.
Here's what happened this week in digital marketing:
1. It’s Official: The TikTok Deal Is Done
A White House official confirmed this week that the US TikTok is finalized. TikTok’s new US operations will be run by Oracle, Silver Lake, and MGX, with ByteDance retaining just under 20% of the new organization.
In a statement, TikTok announced that it “will operate under defined safeguards that protect national security through comprehensive data protections, algorithm security, content moderation, and software assurances for U.S. users.”

Since the U.S. takeover, users have been seeing a pop-up with updates to TikTok’s Terms of Service and Privacy Policy. According to CBS News, the biggest change is that TikTok will now collect precise location data from users.
Why We Care: Although this ends the “will-they-won’t-they” game around the TikTok ban, it raises questions about how sustainable the app will be going forward. Under U.S. ownership, app deletions have increased 150%, with many users saying they aren’t fans of the forced sale. If the app continues to lose users, will it remain a primary marketing tool for brands?
2. 3 Apps Gain Attention After TikTok Deal
With some American users seeking alternatives to TikTok, three apps are benefiting from the exodus.

A sudden uptick in downloads hit these three apps this week:
- Upscrolled - an Instagram-style social platform
- Skylight - an open source TikTok alternative
- Yope - a visual messaging app popular with Australian teens
While it’s still way too early to tell if the US deal will affect TikTok’s sustainability, if you think your audience might be jumping ship, it might be a good idea to at least grab your brand’s handle on the up-and-coming apps.
3. Google Searches Fell Nearly 20% YOY
A new report from Search Engine Land says that U.S. Google searches are down almost 20% from this time last year.
While Google still accounts for a strong majority of search results, the report indicates a change may be coming. With fewer searches also comes fewer opportunities for clicks, ads, and traffic.
Search Engine Land maintains that this drop could be due to AI-powered answers and instant results because:
- Users are getting what they need with fewer searches and follow-ups
- Zero-click searches remain high
- Repeat searches and clicks within the Google ecosystem show minor changes
The study also showed that queries are getting longer, with most queries totalling between six and nine words. Additionally, very long searches of 15 words or more remain rare but are increasingly common. This indicates that users are becoming more comfortable searching for more complex questions.
According to Rand Fiskin, co-founder and CEO of SparkToro, “The big highlight here is the decline in # of Google searches/searcher from 2024–2025. It’s a nearly 20% decline in the US, though only 2–3% in the EU/UK. Other studies have shown that Google is sending less traffic than in years past, especially to the long-tail of the web, and I suspect that AI answers have dramatically altered the way many users engage with Google, answering their questions before they ever need to click on an organic result or perform a second/third/fourth search.”
You can download the full report here.
4. Google is Considering Letting Sites Opt Out of AI Search Features
If you aren’t a fan of generative AI search features, you might soon be able to opt out of letting it explore your website.
In a recent Google blog post, Ron Eden, Principal of Product Management, was quoted as saying: “Building on this framework, and working with the web ecosystem, we're now exploring updates to our controls to let sites specifically opt out of Search generative AI features. Our goal is to protect the helpfulness of Search for people who want information quickly, while also giving websites the right tools to manage their content. We look forward to engaging in the CMA’s process and will continue discussions with website owners and other stakeholders on this topic.”
A survey by Barry Schwarts on X showed that 1 in 3 publishers would opt to block Google’s AI search features.
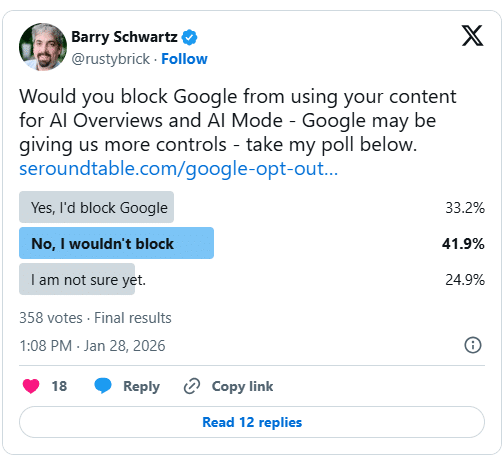
While no timeline or concrete guidance has been provided, if this happens, publishers will have greater control over where and when their content appears on the web.
5. AI Recommendation Lists Repeat Less Than 1% of the Time
A new study from SparkToro and Gumshoe.ai finds that AI-generated brand and product lists almost never repeat, even with identical prompts.
Key findings:
- Less than 1% of lists repeat exactly
- Rankings jump wildly, but intent survives (top brands appear frequently)
- Smaller markets show more consistency; larger markets are chaotic
Takeaway: Track visibility across multiple runs, not exact rank. AI outputs are random by design. Focus on brand presence, not position.
6. AI Local Visibility Is Up to 30x Harder Than Google
A new SOCi report shows that appearing in AI recommendations is far more difficult than ranking in Google’s local results.
Key findings from 2,751 multi-location brands:
- ChatGPT recommended 1.2% of locations, Gemini 11%, Perplexity 7.4%
- Google’s local 3-pack featured 35.9% of the same locations
- Fewer than half of top Google local performers appeared in AI recommendations
Industry highlights:
- Retail: Only 45% of top local brands carried over to AI
- Restaurants: Visibility clustered among leaders with strong ratings
- Financial services: Brands with poor ratings or incomplete profiles were often invisible
Download the full report here: The 2026 Local Visibility Index
7. Google Adds Data to Demand Gen Campaigns
Google recently announced new updates to its popular Demand Gen campaigns.

Among the updates, new features include:
- Attributed Brand Searches: shows the volume of branded searches your campaign drove on Google/YouTube to help you quantify your impact beyond core conversion goals
- Shoppable CTV: enables viewers to seamlessly browse and purchase products while watching YouTube ads on the big screen
- Travel Feeds: hotel advertisers can now connect their Hotel Center feed with their Demand Gen campaigns to populate dynamic ads
Explore all of the details of these exciting new opportunities here on the Google Ads & Commerce Blog.
8. Pinterest Adds Tool to Improve Media Management
If you’re one of the many brands on Pinterest, you’re going to love this recent announcement.
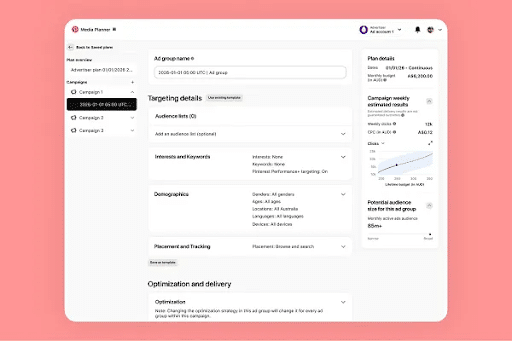
Thanks to the new Media Planner tool, managing campaigns just got easier. Now marketers can:
- Explore audiences, including high-value audience segments
- Estimate opportunities to see how much key awareness campaign metrics, including impressions, reach, frequency, and CPM, will cost you
- Narrow down cost estimates to specific countries
- Review different model scenarios to determine the right budget and media needed to accomplish your goals
Pinterest has long been a growing platform for brands and businesses. With access to new data and this new tool, it could climb higher on the must-have social media tool chart.
9. X Launches Paid Promotion Tags
Previously, if you were posting a paid promotion on X, you had to write it within the caption. This new feature will remove that requirement.

In a previous version of X’s rules, it stated that “Posts that are part of a Paid Partnership published as an organic Post must include clear and conspicuous language indicating the commercial nature of such content, like ‘Ad’ or ‘Promoted Content.’” Most creators would simply add a #ad hashtag to their captions.
Now, users will be able to click “content disclosure” and toggle on a notification indicating that it’s sponsored content.
This is all part of X’s bigger push to increase app usage, along with increasing creator payouts and offering a cash prize for the best-performing X article of the month.
10. Threads Ads Open to All Regions
If you’re an American Threads user, you might have noticed ads in your feed, but the ads were still pretty limited and not available globally. Meta announced this week that Threads Ads will now be available in all regions.
In the announcement, Meta said: “Beginning next week, we are expanding ads on Threads to users in all markets globally […] For advertisers, ads on Threads are an easy way to extend the reach of their existing Meta campaigns, automatically adding Threads placements to Advantage+ and manual campaigns. The familiar image, video, and carousel ad formats appear natively in the Threads feed, helping brands reach more people in more places across Meta’s family of apps.”
With over 150 million daily active users and 400 million monthly active users, Threads is quickly becoming a popular social media site – and a place where your ideal consumers could be hanging out.
11. The Numbers Are In: AI Changed Holiday Shopping
You might still be recovering from the holiday rush, but don’t let that keep you from exploring these recent sales numbers.
According to Adobe’s “Quarterly AI Traffic Report,” every single industry saw a huge increase in AI-driven traffic, with the biggest increases being in:
- Retail: 693%
- Travel: 539%
- Financial services: 266%
- Tech and software: 120%
- Media and entertainment: 92%
Conversion rates also rose, with AI-driven traffic outperforming non-AI-driven traffic. As with revenue, AI-driven traffic accounted for a 33% increase over non-AI-driven traffic.
The study also explored demographics, finding that states such as Virginia, Washington, New York, California, and Massachusetts are engaging with AI at twice the US average, while engagement in the South and Appalachia remains at the bottom.
Why We Care: If your target audience is using AI to discover products and services, you need to find a way to get your content mentioned on those platforms.
Weekly Homework:
- If you’re a TikTok user, monitor your metrics carefully to see if the new U.S. deal affects your audience.
- If you want to look outside of TikTok, claim your brand’s handle on the three most popular TikTok replacement apps.
- For Demand Gen users, don’t forget to check out the new tools to see if they could help improve your ROI.
- Download the State of Search report from Datos to see if the numbers are aligning with your brand’s forecast.
- If you’re a Pinterest user, be sure to check out the new tool to streamline your campaign creation.
- If word-based advertising is more your thing, check out the new opportunities on X and Threads.
Digital Marketing News 1/17/2026 to 1/23/2026
This week: Ethical concerns around AI agents intensify, new data confirms organic search is far from dead, and ChatGPT officially steps into the advertising arena.
Here's what happened this week in digital marketing:
1. ChatGPT Starts Testing Ads in the United States
ChatGPT is launching two new changes – one is ads for ChatGPT Free and ChatGPT Go users.
Ads will appear below responses and remain clearly labeled, so as not confuse searchers with actual responses. They will also not be shown to users under 18 and are not eligible to run near sensitive topics, such as:
- Physical health
- Mental health
- Politics
Any conversations about ads will not be shared with advertisers, and user data will not be sold.
The ad test launched alongside the U.S. launch of ChatGPT Go, the low-cost subscription tier at $8 a month. It includes greater access to GPT-5.2, more messages, more uploads, more opportunities to create images, and a longer memory.
Why We Care: With more and more people using ChatGPT, it could become valuable real estate for marketers across industries.
2. Google Gemini Rules Out Ads – For Now
ChatGPT might be the only AI tool with ads, at least for now. Google denied this week that it will be running ads on Gemini any time soon.
Originally mentioned in December, this sentiment was again echoed this week by Google DeepMind CEO Demis Hassabis at the World Economic Forum in Davos. At the same time, he shared that Google would rather focus on creating a more robust and capable assistant than on figuring out how to monetize it.
This comes on the heels of ChatGPT announcing it will begin showing ads on its platform. It’ll be interesting to see if the introduction of ads on ChatGPT influences usage on either app.
Why We Care: If you’ve been waiting for ads to come to AI chatbots, you might want to turn your attention to ChatGPT, instead of Google Gemini.
3. 71% of Marketers Say Ethical and Privacy Standards Need to Be Established for AI Agents
A new study published by eMarketer reveals the desire for higher ethical and privacy standards for AI agents.
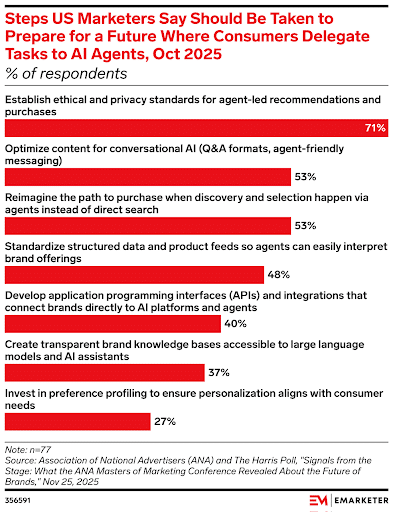
When asked about what needs to happen in order to prepare for a future where consumers delegate tasks to AI agents, the study revealed that:
- 71% think that ethical and privacy standards need to be established for AI agents
- 53% says they need to optimize their content for conversational AI
- 53% wants to reimagine the path to purchase when discovery and selection happen via agents instead of direct search
Marketers aren’t the only ones thinking about AI. Consumers are also incorporating AI into their daily lives, with 29% saying they have made a purchase solely based on an AI-generated response.
Why We Care: AI clearly isn’t going anywhere, and as marketers, we need to make the shifts necessary to adapt to new tools and grow with the industry.
4. Organic Traffic Is Only Down 2.5% YOY – Not the 25-60% Some Experts Had Claimed
We can finally put it to rest: SEO is not dead. New numbers show that organic search is only down 2.5% YOY, not the 25-60% some experts had predicted.
A new report from Similarweb revealed:
- Organic SEO traffic: -2.5% YoY
- Search engine traffic overall (2025): +0.4%
- Google traffic (2025): +0.8%
- Organic vs. paid clicks: ~90% organic, ~10% ads
- AI Overview CTR impact: -35% when present
- AI Overview prevalence: ~30% of SERPs
The numbers showed that AI Overviews affected organic traffic, but it didn’t completely take it over as previously predicted. AI Overviews appear in only about 30% of queries, mostly for informational questions.
You can learn more about the Similarweb report here.
5. Google Search Ad Clicks Hit 5 Year High
Google Search spending is up – but so are ad clicks.
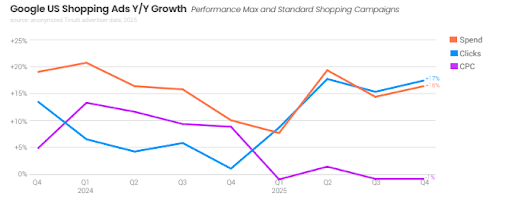
In a Q4 2025 report by Tinuiti, numbers showed:
- Spending rose 13% since Q4 2024
- PMax campaigns accounted for 62% of total Google Shopping spend
- Non-shopping inventory made up 39% of PMax spend
- YouTube video accounted for 13% of impressions outside of search
- Text ad clicks hit a 19-quarter high – growing 9% year over year
Google Ads weren’t the only ads that grew. Microsoft actually outperformed Google with a 16% year-over-year increase and 10% click growth.
You can learn more about Q4 2025 benchmarks for digital ads, including Google, Meta, Amazon, and more, by downloading Tinuiti’s report here.
6. TikTok Introduces More AI-Powered Tools for TikTok Shop
This week, TikTok launched new AI-powered tools to help TikTok Shop creators make more money and have greater influence.
Among the editions are:
- AI Fashion Video Maker - a new tool to make producing Shoppable Videos easier than ever
- AI Dubbing - a tool to automatically create scripts based on product details
- Customer Relationship Management tool - designed to help boost sales, increase loyalty, and retention
TikTok Shop has already proven successful for many brands, and the more tools and features they add, the more brands will be able to expand their reach and find success on the short-form video app.
Why We Care: TikTok is one of the fastest-growing apps, especially for ecommerce brands. If you’ve already added it to your marketing strategy, put checking out these tools on your to-do list.
7. TikTok Shares 2026 Marketing Trends
Speaking of TikTok, the social media app has some ideas for how 2026 will go for digital marketers.

The app says that there are 3 main emerging trends that digital marketers should pay attention to:
- Reali-Tea: telling real stories about real people
- Curiosity Detours: taking audiences to unexpected places
- Emotional ROI: tapping into audience emotions
The report explains why it considers these trends to be emerging and what marketers can do to capitalize on them. Learn more about the trends shaping the social media landscape by downloading the full report here.
8. Google Introduces New Budget Allocations for Ad Campaigns
Do you want to make the most out of your ad campaigns? Now you can! This week, Google announced the introduction of campaign total budgets for Search, Performance Max, and Shopping campaigns.

In the press release announcing the move, Google said: “Instead of making daily manual tweaks to keep pace, campaign total budgets optimize your spend, and aim to fully and effectively utilize your budget by your end date. Whether you’re running a 72-hour test or a month-long activation, you can launch with confidence knowing you won’t overspend or miss out on opportunities. Your campaign will stay on track for your budget goals without the need for daily maintenance.”
While this will reduce the time spent managing your account, it could lead to missed opportunities. For some brands, that might be the better choice.
9. More Creator Features Come to Instagram’s Edits
Instagram rolled out its very first update to its Edits app. The new features are designed to make using the app even easier.
The additions include:
- New video effects, including bounce, fisheye, and blackout
- The ability to add multiple takes of audio and video clips to your storyboard
- Adding interactive links as clickable overlays or more creative possibilities
- 10 new ideas shared weekly to inspire your content
Why We Care: If you’ve been using Edits to make your Instagram Reels, these new edits might make editing your brand’s videos even easier and more interactive.
10. Complex Queries Now Use Gemini 3 Pro
Google has been making many changes to its AI Mode lately. First, it announced AI Mode results in November, then added Gemini 3 Flash for AI Mode. Now, Google introduced Gemini 3 Pro to AI Overviews.
Google’s VP of Product, Robby Stein, said:
- Update: AI Overviews now tap into Gemini 3 Pro for complex topics.
- Behind the scenes, Search will intelligently route your toughest Qs to our frontier model (just like we do in AI Mode) while continuing to use faster models for simpler tasks.
- Live in English globally for Google AI Pro & Ultra subs.
Why We Care: This might make Google’s AI Overviews look different, but that’s because Google is improving its Gemini models and rolling those upgrades into Search, including AI Overviews and AI Mode.
Weekly Homework:
- Download the Similarweb report on paid ad benchmarks to see where your data measures up.
- Consider whether or not you’d like to be one of the first to test running ads on ChatGPT.
- If TikTok is part of your content marketing strategy, download the 2026 Marketing Trends Report. Explore where you can make tweaks to your strategy to align with upcoming trends.
- With Google Search Ad clicks and spending both up from last year, brainstorm ways that you can improve your paid search strategy.
Digital Marketing News 1/10/2026 to 1/16/2026
This week: Apple taps Google Gemini, Google launches AI-powered checkout, and LinkedIn dominates AI citations.
Here's what happened this week in digital marketing:
1. 54% of Millennials Use TikTok for Product Research
If you’re trying to reach millennials, TikTok may be the place to do it. In a new study by eMarketer, 54% of millennials use TikTok for product and company research.
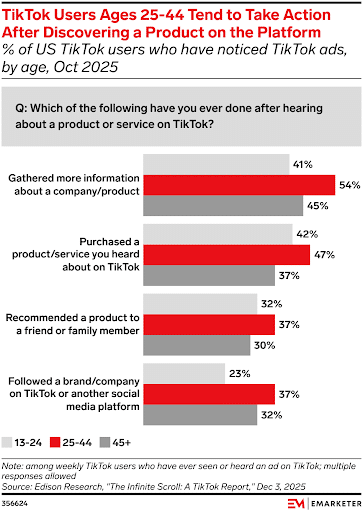
The study also found that a large share of consumers aged 13-24 and 45+ use TikTok for product research and discovery.
And it doesn’t stop at research and discovery. Many of those surveyed also reported either purchasing a product or service they heard about on TikTok or recommending the product to a friend or family member.
2. Apple & Google Announce AI Partnership
The race for the most popular AI model just got a little more interesting. This week, Apple announced that Google’s Gemini will power Apple’s Siri and Apple Intelligence.
The multi-year collaboration means that Gemini will be the foundation for all of Apple Intelligence’s next-generation devices. Currently, Apple integrates OpenAI’s ChatGPT into Siri and states that it will not make any further modifications to that agreement.
Why We Care: This is especially important for brands that want to show up in AI citations, especially for local and near me searches. If you want your brand to be featured, it’s more important than ever to get Gemini’s attention.
3. Google Announces Protocol for AI Mode Checkout
New protocols and features are coming to Google, specifically the AI Mode Checkout Protocol and a new Business Agent.

The first is the Universal Commerce Protocol (UCP). This upgrade establishes a common language for agents and systems to operate together across consumer surfaces, businesses, and payment providers. It was co-developed by industry leaders like Shopify, Etsy, and Wayfair, and has been endorsed by over 20 others, including American Express, Mastercard, and Stripe.
The new Business Agent will enable shoppers to chat with brands directly on the Search page. Users can use it as a virtual sales associate to answer product questions, as if it were the brand. The agent is already live for retailers including Lowe’s, Michaels, Reebok, and Poshmark. Other eligible US retailers can activate their brand agent inside their Merchant Center.
Google also rolled out Direct Offers, which is a new way to test ads in AI Mode. The pilot allows advertisers to present exclusive offers directly in AI Mode to shoppers who are ready to buy.
If you’re a product-based business that wants to grow on Google, it’s a good idea to check out these new features and learn how to use them to your advantage.
4. Reels Account for 50% of Time Spent on Instagram
A new study from Social Media Today highlights how much time people spend watching short-form content.
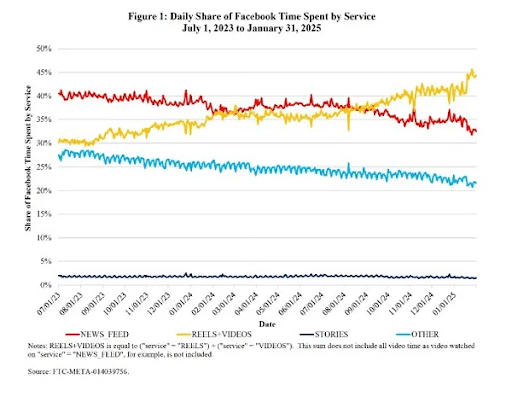
According to the data:
- 50% of the time spent on Instagram is spent watching Reels
- YouTube Shorts are viewed over 200 billion times per day
- Snapchat Spotlight clips views have increased by more than 300% since last year
- Users spend more time on TikTok than on any other social media platform
- Facebook’s primary engagement takes place on Reels
The article also revealed other marketing trends, including Reddit ads and Facebook offering an algorithm opt-out.
Get yourself ready for the upcoming changes and trends by reading the article here.
5. Google Ads Tests Prebuilt Campaigns
Want to jump into Google Ads but not sure where to start? Google’s new campaign set up is meant to reduce friction for new users.
Based on an existing campaign, advertisers can shorten the time to campaign launch prioritizing speed over manual set up.
While Google hasn’t officially announced this feature is here to stay, its fair to assume that this is either a test or a slow roll out of the new feature.
6. Want More AI Citations? Use LinkedIn Articles
According to a recent study, LinkedIn articles are taking over citations in AI responses.
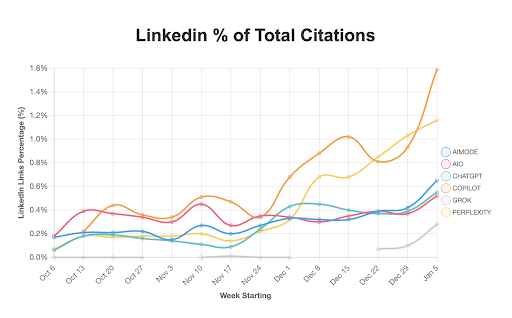
The study was cited as saying “Google search traffic to publishers declined globally by a third in the year to November […] Since May 2023, Google search referrals were down 21% globally, with Google Discover down 18% and all external referrals down 24%.”
The study also said that “data from Spotlight’s extensive database shows that ChatGPT cites LinkedIn 4.2 times more, Perplexity 5.7 times more, and the average across all LLMs is about 4 to 5 times the usual rate. Of the total 19,202 LinkedIn sources cited, over 15,000 come from LinkedIn Pulse articles specifically.”
Is this the year your business starts publishing more LinkedIn content?
7. Almost 30% of AI Overviews Cite YouTube Content
Speaking of appearing in AI Overviews and LLMs, if you aren’t creating YouTube content, you might want to. According to new studies, the video platform is a key source for AI Overview material.
YouTube has long been a popular site, but now that it’s averaging over 1 billion hours of watch time per day, it has overtaken traditional TV and become a key part of the marketing mix.
AI models and recommendation systems aren’t just learning from watch data. They’re also forming connections by monitoring how users bounce between long-form videos, short clips, live commentary, and companion apps on their phones.
If optimizing YouTube is on your 2026 to-do list, here are some things to focus on to get to the top:
- Intent-driven metadata.
- Structural optimization.
- Authority signaling.
- Strategic integration.
8. Instagram’s “Your Algorithm” Option Now Available to All English-Speaking Users
Last October, Instagram announced a new manual control option that would give users greater control over their Reels experience. This week, they announced that it is now available to all English-speaking users.
Instagram users can now select which topics they want to see more or less of. This can be highly helpful for marketers targeting specific audiences, especially when users have selected their topics as a “see more of” option.
One downside is that users must be proactive and select these options, which may not always occur. It is also possible that your Reels won’t reach the people you want because they’ve selected not to see your content.
9. TikTok is Expanding its Marketing Partners Program
TikTok announced a change to its Marketing Partners Program this week with a new “Channel Sales Partner” element.

This new feature connects prospective TikTok advertisers with better platform support aligned with their specific business requirements.
TikTok was quoted as saying, “More and more small and medium-sized businesses are turning to TikTok to drive real business results, from discovery through to leads, bookings, and sales. Sitting under the Marketing Technology badge, the Channel Sales Partner Program recognizes partners that meet TikTok’s technical, operational, and go-to-market standards while driving SMB adoption and investment through their platforms at scale.”
Why We Care: If 2026 is the year you grow your brand on TikTok, the addition of Channel Sales Partners is a great way to do it.
10. Google Launches A/B Testing for PMax Campaigns
Do you wish you could do more with your PMax campaigns? Now you can! This week, Google launched a new Beta that allows advertisers to A/B test asset sets.

Since Performance Max (PMax) campaigns generally rely on automation, enabling testing is a significant step forward. It gives advertisers greater control over asset-level performance without launching a new campaign.
You can learn more about this new feature and how to access it for your brand by reading the Google Blog.
11. Google Trends Explore Page is Getting a Major Update
Big news as Google announces it is integrating "Gemini capabilities to automatically identify and compare relevant trends for your area of interest," in Google Trends.
This new and improved Google Trends Explore page has a side panel that is powered by Gemini and meant to help users find even more search terms to explore.
The new “suggest search terms” button will ask Gemini to break out all related terms and compare them to each other. You’ll get a list of relevant terms as well as prompts to take you further into related trends.
Increase the depth of your searches with this tool today. Google Trends now assigns dedicated colors and icons to each search term to improve comprehension, allows you to add even more search terms and doubled the amount of rising queries that will show up in results.
Try it out today!
12. TikTok Phases Out Custom Identify Option for Advertisers
Speaking of TikTok, the social media platform also announced it will phase out its Custom Identity Option early this year.
When the change is complete, all advertisers will need a verified TikTok profile to continue running ads in the app. To help prepare for the switch, TikTok is advising advertisers to review the F.I.R.S.T. framework to avoid any pauses in their current marketing campaigns.

Once an advertiser completes the framework, they will be able to continue to use all of the TikTok ad tools and options, even after the Custom Identity Option is phased out.
In addition to aligning with the new system, TikTok says that following the F.I.R.S.T. framework could also help your bottom line. In the announcement, TikTok said that, “[a]ccording to backend tests, 59.3% of advertisers saw their cost per acquisition (CPA) decrease by at least 10% after linking accounts.”
A detailed guide to the new framework is available here.
Weekly Homework
- Brainstorm ways to improve your business’s chances of being noticed by Google’s Gemini. This will boost you in both the Google ecosystem and Apple Intelligence.
- If you’re a product-based business, explore the new features in Google’s AI Mode, specifically the Business Agent or Direct Offers.
- Read the 2026 trend report from Social Media Today to find ways to fill in the gaps in your current social media strategy.
- Consider whether LinkedIn articles could improve your chances of ending up in an AI citation.
- If you are using TikTok’s Custom Identity Option to run your ads, be sure to follow the F.I.R.S.T framework so your ads aren’t disrupted when the Custom Identity Option phases out.
Digital Marketing News 1/2/2026 to 1/9/2026
This week: Consumers increasingly trust AI over traditional search, Google’s December Core Update caused major SERP volatility, and Instagram is forcing brands to rethink discovery by limiting hashtag usage.
Here's what happened this week in digital marketing:
1. 60% of Consumers Say AI Delivers Better Answers than Traditional Search
A new study revealed insights marketers can use to get ahead in 2026.
Not only did more than one-third (37%) of consumers say they are turning to AI chatbots for search assistance instead of Google, but many also report search fatigue with traditional search methods. Some of the top frustrations include:
- 40% - Clicking through too many links
- 37% - Getting too many ads or sponsored results
- 33% - Difficulty getting a straight answer
- 28% - Receiving repetitive or low-quality information
Of those surveyed:
- 60% said AI delivers better answers
- 80% feel confident that AI is unbiased
Even with that level of confidence, 85% still double-check AI answers elsewhere.
While consumers may use AI for shopping assistance, the study also finds that traditional search engines remain the preferred option for searches on product reviews and pricing, news and recent events, images and videos, and health and medical information.
These insights are just the tip of the iceberg. Click here to download the entire 2026 AI and Search Behavior Study.
2. 40% of Marketers Are Using AI for Social Media Management
Wondering how other marketers are using AI in their content generation? A new study published by eMarketer offers insights for you.
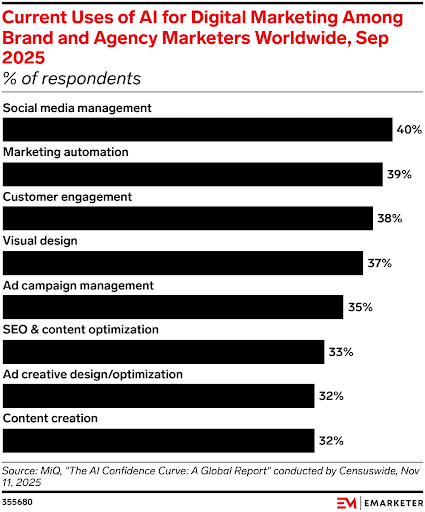
The study revealed that:
- 40% of marketers are using it for social media management
- 39% turn to AI for marketing automation
- 38% are using it for customer engagement
- 34% identify as intermediate-level users when it comes to AI marketing maturity
Have you heard of Rallio? It’s our AI-powered social media management tool that can help streamline your content generation and engagement strategies, allowing you to manage multiple social channels efficiently.
Rallio empowers brands, content suppliers, business owners, and employees to rally together and amplify their social media presence like never before, all in one social media platform.
3. Google’s December Core Update Produced A Lot of Volatility
Have you seen a lot of volatility in your SERP results? It could be due to Google’s December Core Update.
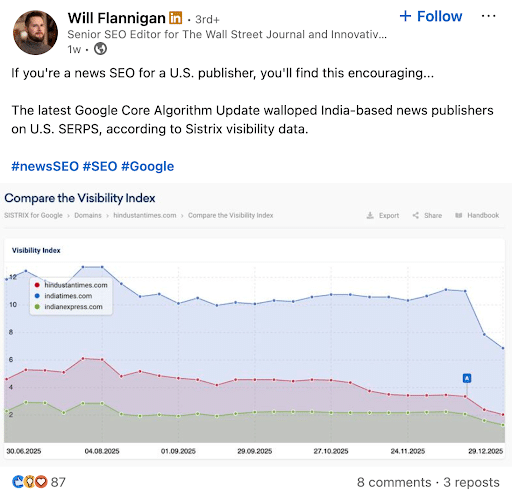
The update finished on December 29th, and here’s what changed:
- News publishers experienced volatility across Search, Discover, and Google News surfaces
- “Best of” round-up posts are no longer ranking as highly as before
- Brands and commercial sites with product authority are seeing higher rankings
- Specialized retailers and brands picked up traffic, while broader retailers lost some
- Specialized software sites also gained more traffic, specifically to landing pages and resource content
If you were affected, click here to read more about how the core updates work and what you can do to reclaim lost traffic.
4. Google Ads Upgrades Creator Partnerships
Google Ads’ Creator Partnerships recently got an upgrade with new search and management tools.

The new tools include:
- The ability to search for YouTube creators by keyword or channel handle
- A filter to break search results down by subscriber count, average views, location, and contact availability
- A centralized creator communication hub with direct email access built in
With creator-led campaigns expected to play a larger role in digital media in 2026, these new Creator Partnership updates arrive at the right time.
Click here to learn more about the new tools and how you can use them in your content this year.

5. Experts Say Content Curation is Vital to Keeping Consumers in 2026
According to a new study published by eMarketer, brands need to curate the right content and culture to retain their consumers in 2026.
Experts say that providing curated product selections is the key to strengthening loyalty, encouraging repeat purchases, attracting new customers, and improving the shopping experience.
This applies to both in-store and online shopping experiences, as 73% of Gen Z shoppers and 67% of millennials say social media is their primary source of information for discovering new products.
That doesn’t mean to push out more content. It simply means curating your content more effectively. In fact, less is more in 2026: 75% of shoppers say the ability to narrow choices strengthens their confidence in purchase decisions.
How will you curate a more customized context and environment to improve your consumer experience in 2026?
6. Max Campaigns Come to Reddit
Reddit spent 2025 going all in on its ad offerings. So far, 2026 seems to be continuing the trend.
The site recently introduced Max campaigns, a new automated campaign that offers a simplified setup, improved performance capabilities, and deeper audience insights.

Early reports say that this new format is proving successful. According to Reddit, Brooks Running saw a 37% decrease in cost per click and 27% more clicks over the course of a 21 day campaign using a beta version of their Max campaigns.
Jyoti Vaidee, VP of Ads Product at Reddit, said that, “[n]ew advertisers are coming to Reddit each day. Our goal is to make their experience as simple and insightful as possible. Max campaigns empower advertisers to launch high-performing ads in the right places on Reddit, while giving them insight into the audiences they’re reaching. We’re not just making ad management faster – we’re making it smarter and tailored to our community.”
For now, Max campaigns is still in a beta format for traffic and conversion campaigns for select advertisers. Reddit says it expects to roll out access to more advertisers over the next few months.
Reddit has been working hard to capture PPC revenue and this new format may help it achieve its lofty goals.
7. Instagram is Limiting Hashtag Usage
Are you a hashtag fan? You might have to adjust your strategy! In a new announcement, Instagram shared that it is now limiting hashtags to 5 per post.
The social media platform says that this comes from research that says “using fewer (up to 5) more targeted hashtags, rather than many generic ones, can improve both your content’s performance and people’s experience on Instagram.”

What This Means: For social media managers, it's time to ditch the generic hashtags and instead focus on being more intentional. Choose 5 specific and relevant hashtags to still encourage discovery of your posts, but lean into your caption writing to grab the attention of more users.
8. Google Adds Maps to Demand Gen Channel Controls
Listen up! Advertisers now have the opportunity to run Demand Gen campaigns on Google Maps. This changes the ad landscape by prioritizing intent-driven placements, giving advertisers even more control.
Think about the power of intent-driven placements. Advertisers should begin to tailor ads to local discovery and navigation when possible.
Get creative and start prioritizing location-centric ads today.
9. Instagram Shares 2026 Insights on Content
Adam Mosseri, Head of Instagram, recently shared some thoughts on the future of content, specifically on his app, where he says “authenticity is becoming infinitely reproducible.”
Some of his most important points include:
- AI is able to replicate anyone’s work
- AI content will soon be indistinguishable from human-generated content
- People connect more personally in DMs than on their Instagram feeds
- To help combat AI fakes, creators are producing less polished content
- Instagram is working to highlight AI through labeling, but it is becoming overwhelming
Mosseri also shared that Instagram is exploring ways to better identify who is behind each account, both to reduce misinformation and to detect AI-generated content.
It’s no secret that AI is being incorporated into every aspect of our lives, but do you agree that it will affect social media in the same ways that Mosseri is saying?
10. OpenAI is Reporting Looking to Buy Pinterest
OpenAI is always looking for ways to evolve, and this might mean purchasing Pinterest in the near-future.
According to an article in The Information, OpenAI is interested in the social media/search engine app to help it acquire more human-generated data, specifically around product searches. That information will help them turn ChatGPT into a more robust shopping tool and create additional ad-revenue opportunities.
With over 600 million monthly users, Pinterest collects substantial data that could be highly valuable to OpenAI.
If you’re one of the many brands that advertise on Pinterest, you should keep an eye on this potential merger. The acquisition could affect your 2026 strategy if it proceeds.
Weekly Homework:
- Download the AI and Search Behavior study to uncover valuable insights to help improve your SEO strategy.
- Analyze your SERP rankings to see if your site took a hit during Google’s December Core Update.
- Explore the new Creator Partnership tools to see how you can use them in your ad campaigns this year.
- Download HubSpot’s Reddit Guide and check out the new Reddit Max campaigns to see if advertising on Reddit makes sense for your social media and SEO strategies.
- Have your social media team review your upcoming and recently posted Instagram captions to ensure you’re using only 5 specific hashtags.
Digital Marketing News 12/13/2025 to 12/19/2025
This week: New data shows a surge in global internet and AI-driven traffic, Google’s December Core Update and what it means for faster ranking recovery, and major platform changes from Meta and Instagram that could affect link sharing, engagement, and visibility.
Here's what happened this week in digital marketing:
1. Global Internet Traffic Grew 19% in 2025
According to Cloudflare’s Year in Review, it’s been a busy year on the internet! Global internet traffic grew 19% this year, with significant growth starting in August.
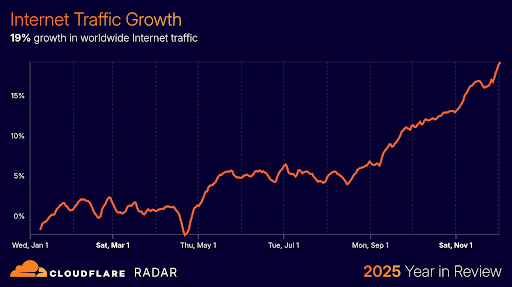
In a recent report, Cloudflare said Googlebot crawled 200 times more pages than other AI bots and crawlers. Other key findings include:
- Global internet traffic grew 19%
- Starlink traffic doubled, including in 20 new countries and regions
- Human-generated web traffic grew to 52%
- iOS devices were responsible for 35% of global mobile traffic
- Google is the top search engine, with Yandex, Bing, and DuckDuckGo following
- AI bots account for 4.2% of HTML requests
Cloudflare’s Year in Review includes a ton of other interesting findings in topics such as Traffic, AI, Adoption and Usage, Connectivity, and Security. Read it now for insights that could affect your marketing strategy moving into 2026.
2. Google’s December 2025 Core Update is Here
Google started rolling out its third core update of 2025 on December 11th.
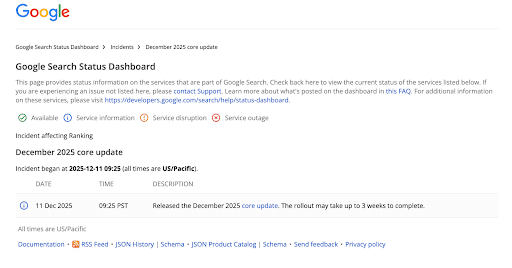
Before the rollout started, Google revised its core updates documentation to include this language on ongoing algorithm changes: “However, you don’t necessarily have to wait for a major core update to see the effect of your improvements. We’re continually making updates to our search algorithms, including smaller core updates. These updates are not announced because they aren’t widely noticeable, but they are another way that your content can see a rise in position (if you’ve made improvements).”
The roll-out is expected to take 3 weeks to complete. During that time, it’s likely that you’ll see some shake-ups in your SERP ranking and organic traffic.
3. Google Search Live Gets an Upgrade
Google updated Search Live this week with Gemini 2.5 Flash Native Audio, and it could cause some wrinkles in SEO.
According to Google, “When you go Live with Search, you can have a back-and-forth voice conversation in AI Mode to get real-time help and quickly find relevant sites across the web. And now, thanks to our latest Gemini model for native audio, the responses on Search Live will be more fluid and expressive than ever before.”
Updates include:
- Broader update to Gemini 2.5 Flash Native Audio across the Google ecosystem
- Improvements for Voice-Based Systems
- Smoother conversational translations
With this update, Google is one step closer to realizing its vision for voice search.
4. AI is Coming to Firefox … if You Want it To
Mozilla CEO announced this week that AI is coming to Firefox in 2026.
The last few years haven’t been easy for the company. It underwent a restructuring, laid off 30% of its employees, and discontinued advocacy and other global programs.
While they need to make a comeback and see the opportunity in AI, Anthony Enzor-Demeo, CEO of Mozilla Corporation, said in a blog post that: “People want software that is fast, modern, but also honest about what it does. They want to understand what’s happening and to have real choices. Mozilla and Firefox can be that choice.”
He also noted that, “AI should always be a choice — something people can easily turn off. People should know why a feature works the way it does and what value they get from it.”
This means that the company is introducing AI tools in its browser, but only if the user allows it. The goal is to keep up with technology without losing consumer trust.
It will be interesting to see how this plays out and if it helps Mozilla pull consumers back from other browsers that force its users to use AI.
5. YouTube Shorts Get Updates to Improve Engagement
YouTube released several new features this week, including comment sections and the ability to add Shorts ads to mobile web browsers.

The updates include:
- A comment section on Shorts Ads
- Links for branded content that bring clicks directly to the advertiser’s website
- Expansion to add Shorts Ads to mobile web browsers
According to Kantar research, YouTube Ads on Shorts increase purchase intent by 8.8% and drive 2.9x more consumer spending intent than other competitors. It’ll be interesting to see whether these news features increase those numbers and drive more traffic and sales.
6. Meta Tests Limiting Link Sharing for Business Profiles
Is your business profile verified on Meta? If it isn’t, you may have seen this interesting update this week.
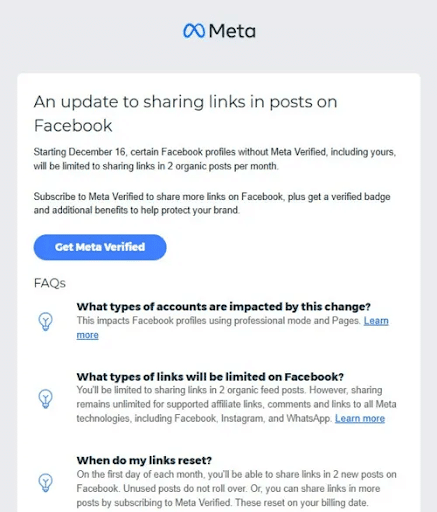
According to a new pop-up some accounts have received, “Starting December 16, certain Facebook profiles without Meta Verified, including yours, will be limited to sharing links in 2 organic posts per month. Subscribe to Meta Verified to share more links on Facebook, plus get a verified badge and additional benefits to help protect your brand.”
While this is still in beta, it could be a significant change for Meta in 2026. If you’re a business without a verified account and you post a lot of links, this could seriously affect your content strategy.
7. New Features Aim to Improve Creator Partnerships on Meta
This isn’t the only announcement Meta made this week. The social media platform also shared some updates to improve partnership opportunities for brands.
In the announcement, Meta shared new updates, including:
- More content types in the Partnership Ads Hub
- The ability to view performance insights
- A new Facebook Partnership Ads API
- Expanded creator eligibility for partnership ads, including professional mode profiles
- Simpler permissions to convert UGC into partnership ads
These updates could significantly improve how brands create and use UGC on Meta’s platforms.
8. US Users Can Now Control Their Reels Algorithm
Meta announced a soft launch in October, and now all US users have access to its “Your Algorithm” manual control option.
According to Meta’s Chris Cox, “We’re launching the ‘your algorithm’ tool on Reels today in the U.S. and will roll out soon to all English-speaking users — a big step towards a more controllable experience. We’ve done a bunch of work on the tech under the hood and we will continue to refine these tools, but already it’s quite powerful to steer your recommendations towards your specific interests.”
This could go one of two ways for advertisers. Either you’ll be able to reach more interested parties through topic buckets, or you’ll lose views on your Reels because people mark them as not interested.
9. Pinterest Shares 2026 Trend Predictions
Want to know what big trends are coming up in 2026? Pinterest might have the answer for you in its annual Pinterest Predicts report.

The annual list has been successful in the past, with 88% of its predictions coming to fruition.
In addition to the trend predictions, the report also includes a fun quiz to take to help you decide which trend is right for your brand.
Discover everything packed into the 24-page guide, including brand tips and advice, and how to incorporate them into your Pinterest strategy, by reading the full report here.
10. TikTok Deadline Is Extended Again
What’s going on with TikTok in the United States? No one knows.
Since a deal to sell the social media app did not close by the December 16th deadline, a new executive order extended the deadline to January 23, 2026.
The executive order stated: “A plan has been presented to me to undergo a qualified divestiture of TikTok’s United States operations, as outlined in a framework agreement. Under this Framework Agreement, TikTok’s United States application will be operated by a newly established joint venture based in the United States. It will be majority-owned and controlled by United States persons and will no longer be controlled by any foreign adversary, since ByteDance Ltd. and its affiliates will own less than 20 percent of the entity, with the remainder being held by certain investors.”
It is the same plan that was signed off on in September, but details of the deal are still up in the air.
For now, it is business as usual for TikTok, its advertisers, and its users.
11. Experts Predict a Volatile 2026 with Tighter Budgets and Reduced Headcounts
In a new article published by Marketing Dive, experts say B2C marketers will face several challenges in 2026, including price hikes and AI-driven privacy breaches.
In the article, stats are shared, including:
- 52% of industry executives predict tighter budgets
- 51% predict reduced headcounts
- 64% say 2026 will be more volatile than 2025
AI is contributing to these projections, with some experts forecasting a 20% increase in class action lawsuits driven by AI-driven data breaches.
Whether these predictions come true or not, it's important to consider them in your 2026 planning, especially if you’re in the B2C space.
Weekly Homework
- Get up-to-date on the state of the internet with Cloudflare’s Radar Year in Review.
- Keep an eye on your SERP ranking and organic traffic to see if your site is affected by Google’s December 2025 core update.
- Explore all of the updates to Meta’s Creator Partnership Ads Hub in the Ads Manager to see if any of them can improve your content strategy.
- If Reels are a big part of your social media strategy, be sure to monitor your views now that users can access the Your Algorithm tool. If you’re seeing a drop in views, try some new content strategies to help your audience mark you as interesting again.
- Download the annual Pinterest Predicts report to see what’s coming up for 2026 and how you can use these trends to improve your brand’s online presence.
Digital Marketing News 12/6/2025 to 12/12/2025
This week: AI-driven traffic surges 805%, TikTok drives explosive holiday revenue, and OpenAI halts ads amid overhaul.
Here's what happened this week in digital marketing:
1. AI Traffic to Websites on Black Friday Up 805% from 2024
Numbers are still coming in on Black Friday, but initial indications suggest e-commerce growth.

According to MarketingDive, initial numbers include:
- Adobe Analytics: e-commerce sales hit $11.8 billion, a 9.1% increase from 2024
- Salesforce: Online Black Friday sales grew to $18 billion, a 3% increase over last year
- Shopify: offline sales increased by 26% year over year
- AI traffic to US websites grew 805%
- AI leads were 38% more likely to convert
The biggest Black Friday winners: AI-driven traffic and retailers with exclusive store perks (like the Target Black Friday Tote and the Lowes Black Friday Bucket)
The biggest Black Friday losers: online order volume, flat online discounts, and short-term financing.
2. Black Friday to Cyber Monday: TikTok Sales Hit $500 Million
TikTok had a great Black Friday, sharing that it sold over $500 million in merchandise between Black Friday and Cyber Monday. This large sales number was accompanied by a nearly 50% increase in shoppers compared to 2024.

Last year, TikTok reported $100 million in sales on Black Friday alone, demonstrating how quickly the platform is growing.
In just four days, TikTok reported:
- 84% sales growth from last year
- Shoppers tuned into more than 760,000 livestreams
- Livestreams generated 1.6 billion views
eMarketer stated that it expects TikTok to generate over $15.82 billion in US retail ecommerce revenue alone this year, up over 108% from last year.
Love it or hate it, the truth is: TikTok is powerful.
3. TikTok Creator Ads Have a 70% Higher Click-through Rate than Non-Creator Ads
If you want to increase your sales, TikTok says you should lean into influencer partnerships.
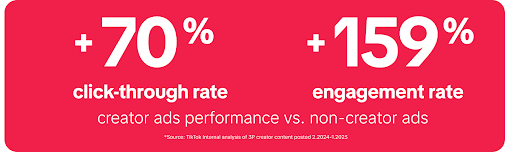
In a new blog, the social media platform shared that creator-led content is more successful than non-creator ads. When compared to non-creator ads, creator-led ads received:
- 70% higher click-through rate
- 159% higher engagement rate
When those ads are posted directly to the creator’s platform, rather than the advertiser’s account, they received:
- 59% higher engagement rate
- 16% higher six-second view-through rate
This shows that consumers are looking for real-life advice, especially from their favorite creators.
As you push through the holiday season and into 2026, attempt to create some relationships with creators in your industry or niche. They may become valuable advertising partners.
4. New ChatGPT Data Reveals Top 20 Factors that Influence ChatGPT Citations
Everyone wants to know how to get their content into ChatGPT citations and a new study from SE Ranking might have the answer.
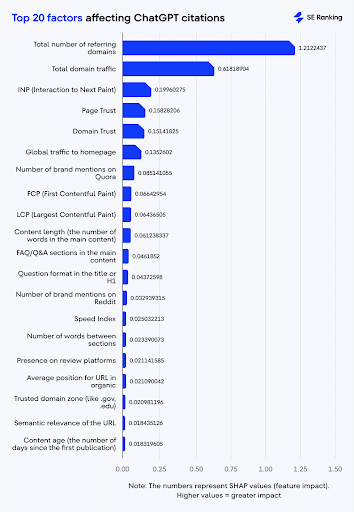
After analyzing 129,000 domains, they found that the number of referring domains was the single strongest predictor.
Other signals that made the list included:
- Domain traffic
- Content depth
- Structure
- Social signals
- Review platforms
- Technical performance
The authors were quoted as saying, “For smaller, less-established websites, engaging on Quora and Reddit offers a way to build authority and earn trust from ChatGPT, similar to what larger domains achieve through backlinks and high traffic.”
Why We Care: The study finds that many of the same things you’re probably already doing as a part of your SEO strategy are the things you should be doing if you want to appear in AI citations.
5. 45% of Consumers Are Turning to Online Reviews Before Making a Purchase
A recent report by DoubleVerify revealed some eye-opening statistics about the state of social media and online shopping.
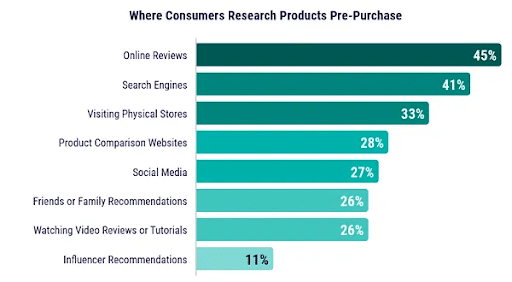
After looking at how consumers’ social media usage impacts their shopping and purchasing habits, the study found that:
- 45% of consumers look at online reviews before making a purchase
- 72% of consumers are on YouTube, followed by 69% on Facebook
- 31% said that social media influencers significantly impact their purchasing decisions
- 23% said they’ve made a purchase based on a positive comment on an influencer’s post
- 58% said they interact with influencers
- Most marketers use Instagram (96%), Facebook (96%), YouTube (94%), and TikTok (88%) to reach their target audience
If you’re interested in learning more about the study’s findings, as well as regional trends in marketing, download the full report here.
6. Google Launches “Partner Match” for YouTube Targeting
If you want to improve your YouTube targeting, you’re going to love this new tool from Google.

“Partner Match” lets you match third-party user data to signed-in YouTube accounts. With this data, advertisers can target the matches through Video Reach campaigns, Video Views campaigns, and Demand Gen campaigns (YouTube channel only).
Google says that this tool has two major benefits:
- You can use third-party partner data to improve your ad targeting.
- You can boost brand awareness and drive consideration to specific audience segments that you may not have reached before.
The tool was rolled out globally, with the exception of the UK, Switzerland, and the EEA.
If you’re a YouTube advertiser and you want to improve your targeting or reach new and relevant audiences, log in to your account and check out all that Partner Match has to offer.
7. ChatGPT Hits Pause on Ad Plans
We’ve previously reported that OpenAI was signaling that ChatGPT Ads could be coming, but a new internal memo obtained by The Wall Street Journal says otherwise.

In the memo, OpenAI SEO Sam Altman ordered a ChatGPT quality overhaul and pushed pause on any plans to develop advertising opportunities. The company wants to focus more on making ChatGPT better, faster, and “more intuitive and personal” before adding any advertisements.
This is due to several factors, including rising competition from Google and heavy financial strain on the company. The troubles are so bad that the internal memo called it a “Code Red.”
It probably didn’t help the “Code Red” panic feeling when ChatGPT went offline for thousands of users earlier this week.
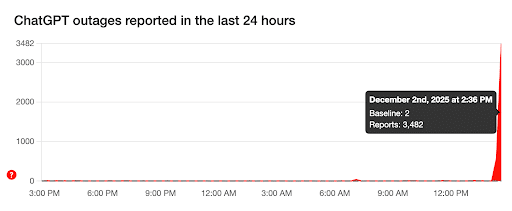
In addition to pausing work on advertising initiatives, OpenAI is also pausing work on AI health and shopping agents and a personal assistant called Pulse.
You can read the full company-wide memo here.
8. Bing Explains What Matters for AI Search Visibility
Do you want to increase your traffic from AI Search? Bing explains how to do it.
In a recent blog post, Bing explained that:
- AI repurposes your content into an easy-to-read summary with clickable links
- Your highest priority should be to create high-quality content
- Online publishers should also focus on these three signals: citations, impressions, and placement in AI answers
Bing was quoted as saying, “As AI-powered search reshapes how people explore information, more of the journey now happens inside the experience itself.”
Essentially, Bing is encouraging you to show up in review sites, build relationships, and try to get in front of customers as much as possible.
You can read the entire blog here.
9. Google Shares 2025 Year in Review
This week, Google released its 2025 Year in Review. It’s full of insights on everything from Performance Max to Demand Gen.

The biggest news?
- Ads in AI Overviews expanded.
- AI Mode opened a new mid-funnel inventory.
- Changes and improvements came to AI Max for Search, Smart Bidding Exploration, and Search Partner Network.
- Ads Advisor and Analytics Advisor also stepped up their guided support.
- YouTube, DemandGen, and PMax also grew substantially, thanks to additional support and features.
Here’s where Google is turning its attention to for 2026:
- Creating clearer consistency in AI Overviews
- Expanding customization settings and transparency in AI Max
- Improving Asset Studio and Meridian’s measurement tools.
Review all of the important 2025 insights here.
10. Apple Releases Top Downloaded App of 2025
What was the top downloaded app in 2025? Apple says – ChatGPT!
The top 10 free apps included:
- ChatGPT
- Threads
- TikTok – Videos, Shop & LIVE
- WhatsApp Messenger
- YouTube
- Google Maps
- Gmail – Email by Google
- Google Gemini
This is great news for digital marketers, since most of these apps, like ChatGPT, Threads, TikTok, Instagram, YouTube, and Google Maps, can be used to drive organic traffic your way.
Check out all of the other Top 10 lists, including Top Paid Apps, Top Free Games, and Top Free iPad Apps here.
11. Customize Your Instagram Recommendations
Tired of seeing content on a specific topic? Good news, Instagram allows you to modify the topics that are landing Reels in your feed.
Using the new tool Your Algorithm, the new Reels icon opens a list of topics Meta AI is recommending to you, based on your recent user behavior. From here, you can indicate which topics you’d like to see more or less of.
Instagram VP Tessa Lyons reveals, “We’re always trying to show people the best possible reels for them. I think we do a pretty good job today, but we don’t always get it right, and we know that people’s interests change. What we really want to do is give people control over the experience that they have on Instagram.”
We’re looking forward to seeing how this algorithm change affects Explore, the search tab and other areas besides Reels in the future.
12. Fresh Content or Evergreen? YouTube Shorts Report Reveals Shift
Should you post fresh content or stick with evergreen videos on your YouTube Shorts channel? A new study reveals that fresh might be the way to go.
Mario Joos, a strategist who works with MrBeast, Stokes Twins, and Alan’s Universe, first noticed the pattern after experiencing a broad dip in performance amongst his client portfolio. After analyzing data from channels with 100 million to one billion monthly views, he found that:
- Shorts older than 28-30 days now receive fewer impressions than the videos in a similar threshold did in mid-September.
- YouTube is pushing creators toward high-volume uploads over quality content
YouTube hasn’t confirmed any algorithm changes, other than to say that “recommendation systems are driving robust watch time growth and that the Gemini models are enabling further discovery improvement.”
However, if you publish Shorts, review your analytics to see whether your views decline after 30 days. If you’re noticing a sharp decline, too, you should consider this when planning your 2026 YouTube Shorts content strategy.
13. TikTok Wants to Enhance Connection with Shared Feed Options
Have you ever wanted to share a feed with your friends? With TikTok’s newest tool, now you can!
TikTok announced this week that its new Shared Feed option will go live. This new feed will be a combined stream of recommended content, based on shared interests.
In the press release, TikTok explained that “Shared Feed can help two people stay connected by surfacing new content tailored to both of their tastes, from sports to holiday winter activities and even their favorite fashion creators. Each day, friends and family members will find a curated selection of 15 videos in their private chat aligned with their interests.”
This could be an interesting feature for both users who want to stay connected with their favorite friends and family, and for marketers who want to expand their product reach among existing customers and fans.
14. LinkedIn Announces New Ad Tools to Reach Buyers Earlier in The Customer Journey
LinkedIn is committed to helping B2B marketers reach their potential customers quicker with smarter targeting and visibility through the following new features:
- Reserved Ads - Get prime placement in the LinkedIn feed for our Video, Thought Leader, Single Image and Document Ads.
- Ad Personalization - Messages will adjust automatically using profile data including name, title, industry, company, etc. to personalize messaging.
- AI-Powered Creative - Test multiple ad variations. Upload your text and assets and Ad Variants will generate new on-brand copy while Flexible Ad Creation will mix, match and optimize your assets.
Use these google to land at the top of your audience’s feed with personalized ads. Focus on AI to generate more variations, enable testing and allow you to optimize your content.
15. 2026 Content Strategy News: Mentions, Citations, and Clicks
Search Engine Land released its 2026 content strategy suggestions this week.
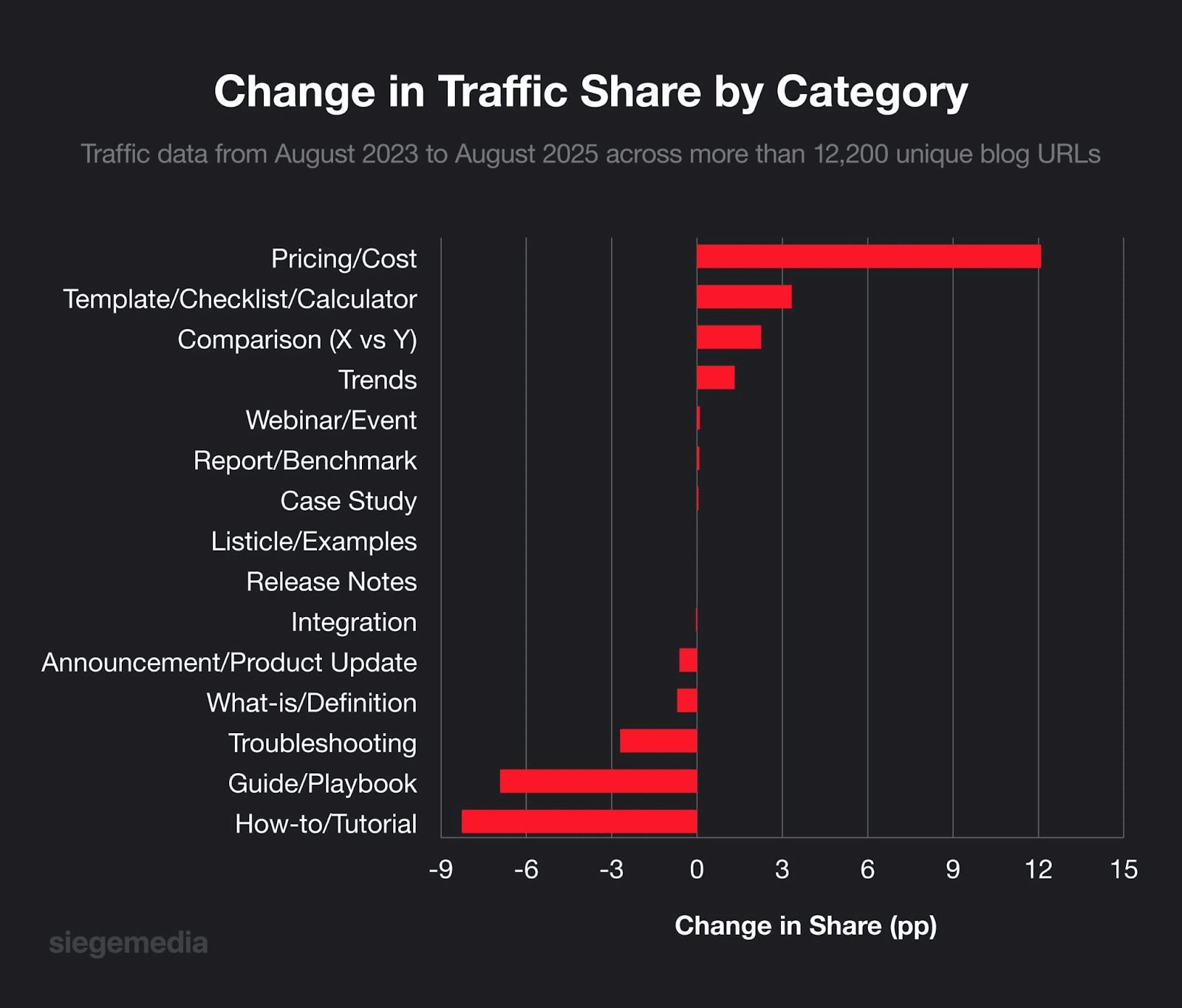
Topping the list was:
- Generating mentions, citations, and structured visibility signals from generative systems like ChatGPT, Gemini, Claude, and Perplexity
- More content on pricing and cost
- Less top-of-funnel guides and “how to” posts
- Focusing on TOFU content to generate interest at the awareness stage
By focusing on the top-of-funnel and less on the bottom-of-funnel, you’ll be able to grab more attention in the very beginning in 2026.
16. Google Year in Search 2025: What Tools Topped Trending Lists
In addition to releasing an overall Year in Review, Google also released a Year in Search with insights on AI tools and search trends that could impact your business.
Topping the list? AI tools like Gemini and DeepSeek. The results also showed that searches in the United States differ from those in the rest of the world. US trends tended to focus on entertainment and public policy.
You can check out all of the trending topics here. You can also break it down by region, as well as topics such as Trending, Entertainment, Sports, and more, so you can be sure to know exactly what is trending in your own industry and market.
Reviewing the Year in Search data and comparing it to your content calendar can reveal gaps or opportunities for you to update your content and generate more traffic.
17. SocialMediaToday Shares 4 Trends Shaping Social Media Marketing in 2026
A recent study published by SocialMediaToday and conducted by Meltwater News US shared four critical trends that will shape social media marketing in the upcoming year.
The study found that:
- Social SEO is the new top-of-funnel, with 24% of consumers preferring social media searches over Google
- Multi-platform engagement is critical
- Social customer care is a must-have for brands that want to build a strong reputation
- Reddit communities drive buying decisions
If you want to find social media success in 2026, you have to admit that what you did in 2020 might not work and instead pivot based on some of these findings.
You can discover more critical insights for 2026 by downloading the full report here.
18. New Agreement Between Publishers and Meta Aims to Improve AI Answers
Meta recently signed a new slate of deals with news publishers to improve AI-generated answers.

In the press release, Meta said: “We’re beginning to offer a wider variety of real-time content on Meta AI - from global, breaking news to entertainment, lifestyle stories, and more. When you ask Meta AI news-related questions, you’ll now receive information and links that draw from more diverse content sources to help you discover timely and relevant content tailored to your interests.”
The company also said, “These integrations will also facilitate easier access to information by linking out to articles, allowing you to visit these partners’ websites for more details while providing value to partners, enabling them to reach new audiences.”
Publications such as CNN, Fox News, Le Monde Group, People, Inc., and USA Today Co., Inc. have already signed on to the agreement.
19. Judge Limits Default Search Deals for Google
Judge Amit Mehta released a ruling late last week that could put an end to Google’s long-term pacts with Apple and Samsung.
The ruling imposed a one-year cap as a “hard-and-fast termination requirement” to enforce antitrust remedies he already rewarded in a previous 2024 ruling that found that Google had monopolized search and search ads.
Now, Google must cap its default search and AI app deals at one year, rather than the current long-term agreements.
This could open the door to a more fragmented search landscape that includes AI-powered rivals like OpenAI, Perplexity, or Microsoft.
Weekly Homework
- Explore all of the Year in Review data released by Google to learn more about the tech giant’s most successful releases, upgrades, and extensions. It will give you a clear understanding of what to expect in 2026, as well as introduce you to concepts from 2025 that you may have missed.
- Watch Google’s Year in Search video and highlight gaps or opportunities for your business in the trending search topics.
- Review your YouTube Shorts data to see if your evergreen content is still performing as well as it used to.
- Review Search Engine Land’s 2026 content strategy suggestions and brainstorm ways to fit them into your strategy.
- Get some inspiration from Marketing Dive’s list of top 2025 marketing campaigns.
Digital Marketing News 11/29/2025 to 12/5/2025
This week: AI drives record-breaking traffic, TikTok dominates $500M holiday sales, and OpenAI freezes ads amid a company-wide “Code Red.”
Here's what happened this week in digital marketing:

1. AI Traffic to Websites on Black Friday Up 805% from 2024
Numbers are still coming in on Black Friday, but initial indications suggest e-commerce growth.
According to MarketingDive, initial numbers include:
- Adobe Analytics: e-commerce sales hit $11.8 billion, a 9.1% increase from 2024
- Salesforce: Online Black Friday sales grew to $18 billion, a 3% increase over last year
- Shopify: offline sales increased by 26% year over year
- AI traffic to US websites grew 805%
- AI leads were 38% more likely to convert
The biggest Black Friday winners: AI-driven traffic and retailers with exclusive store perks (like the Target Black Friday Tote and the Lowes Black Friday Bucket)
The biggest Black Friday losers: online order volume, flat online discounts, and short-term financing.
2. Black Friday to Cyber Monday: TikTok Sales Hit $500 Million
TikTok had a great Black Friday, sharing that it sold over $500 million in merchandise between Black Friday and Cyber Monday. This large sales number was accompanied by a nearly 50% increase in shoppers compared to 2024.
Last year, TikTok reported $100 million in sales on Black Friday alone, demonstrating how quickly the platform is growing.
In just four days, TikTok reported:
- 84% sales growth from last year
- Shoppers tuned into more than 760,000 livestreams
- Livestreams generated 1.6 billion views
eMarketer stated that it expects TikTok to generate over $15.82 billion in US retail ecommerce revenue alone this year, up over 108% from last year.
Love it or hate it, the truth is: TikTok is powerful.
3. TikTok Creator Ads Have a 70% Higher Click-through Rate than Non-Creator Ads
If you want to increase your sales, TikTok says you should lean into influencer partnerships.
In a new blog, the social media platform shared that creator-led content is more successful than non-creator ads. When compared to non-creator ads, creator-led ads received:
- 70% higher click-through rate
- 159% higher engagement rate
When those ads are posted directly to the creator’s platform, rather than the advertiser’s account, they received:
- 59% higher engagement rate
- 16% higher six-second view-through rate
This shows that consumers are looking for real-life advice, especially from their favorite creators.
As you push through the holiday season and into 2026, attempt to create some relationships with creators in your industry or niche. They may become valuable advertising partners.
4. New ChatGPT Data Reveals Top 20 Factors that Influence ChatGPT Citations
Everyone wants to know how to get their content into ChatGPT citations and a new study from SE Ranking might have the answer.
After analyzing 129,000 domains, they found that the number of referring domains was the single strongest predictor.
Other signals that made the list included:
- Domain traffic
- Content depth
- Structure
- Social signals
- Review platforms
- Technical performance
The authors were quoted as saying, “For smaller, less-established websites, engaging on Quora and Reddit offers a way to build authority and earn trust from ChatGPT, similar to what larger domains achieve through backlinks and high traffic.”
Why We Care: The study finds that many of the same things you’re probably already doing as a part of your SEO strategy are the things you should be doing if you want to appear in AI citations.
5. 45% of Consumers Are Turning to Online Reviews Before Making a Purchase
A recent report by DoubleVerify revealed some eye-opening statistics about the state of social media and online shopping.
After looking at how consumers’ social media usage impacts their shopping and purchasing habits, the study found that:
- 45% of consumers look at online reviews before making a purchase
- 72% of consumers are on YouTube, followed by 69% on Facebook
- 31% said that social media influencers significantly impact their purchasing decisions
- 23% said they’ve made a purchase based on a positive comment on an influencer’s post
- 58% said they interact with influencers
- Most marketers use Instagram (96%), Facebook (96%), YouTube (94%), and TikTok (88%) to reach their target audience
If you’re interested in learning more about the study’s findings, as well as regional trends in marketing, download the full report here.
6. Google Launches “Partner Match” for YouTube Targeting
If you want to improve your YouTube targeting, you’re going to love this new tool from Google.
“Partner Match” lets you match third-party user data to signed-in YouTube accounts. With this data, advertisers can target the matches through Video Reach campaigns, Video Views campaigns, and Demand Gen campaigns (YouTube channel only).
Google says that this tool has two major benefits:
- You can use third-party partner data to improve your ad targeting.
- You can boost brand awareness and drive consideration to specific audience segments that you may not have reached before.
The tool was rolled out globally, with the exception of the UK, Switzerland, and the EEA.
If you’re a YouTube advertiser and you want to improve your targeting or reach new and relevant audiences, log in to your account and check out all that Partner Match has to offer.
7. Google Tests New Website Optimizer Tool
Partner Match isn’t the only new Google tool on the block. The internet giant is also testing a Website Optimizer tool.
Website Optimizer seems to be a reinvention of the previous Google Optimize tool. Its goal is to improve A/B testing right inside your Google Analytics 4 platform.
Here are the details:
- Google Ads access and GA4 admin permissions are required
- If you don’t have a GA4 property, it will create one.
- The tool will run directly through Google Ads, streamlining setup and putting all tools in one place.
While this is still in the very early stages of testing, it could help advertisers find a more integrated way to test and improve website performance, directly in the GA4 dashboard.
8. Simplify Your Holiday Shopping with ChatGPT
OpenAI recently rolled out a new feature that will create personalized buyer’s guides for users.

The new feature works differently from typical ChatGPT responses. To access personalized lists, users can describe what they need, include budget and preferences, and receive a fully optimized shopping guide.
The feature is available on mobile and web for all users on the Free, Go, Plus, and Pro plans. From now until the end of the holiday season, OpenAI is offering nearly unlimited usage of this new shopping experience.
Why We Care: As marketers, we all know that showing up during the holiday season is essential. Getting your brand featured in one of these holiday shopping guides could boost your sales.
9. ChatGPT Hits Pause on Ad Plans
We’ve previously reported that OpenAI was signaling that ChatGPT Ads could be coming, but a new internal memo obtained by The Wall Street Journal says otherwise.
In the memo, OpenAI SEO Sam Altman ordered a ChatGPT quality overhaul and pushed pause on any plans to develop advertising opportunities. The company wants to focus more on making ChatGPT better, faster, and “more intuitive and personal” before adding any advertisements.
This is due to several factors, including rising competition from Google and heavy financial strain on the company. The troubles are so bad that the internal memo called it a “Code Red.”
It probably didn’t help the “Code Red” panic feeling when ChatGPT went offline for thousands of users earlier this week.
In addition to pausing work on advertising initiatives, OpenAI is also pausing work on AI health and shopping agents and a personal assistant called Pulse.
You can read the full company-wide memo here.
10. Bing Explains What Matters for AI Search Visibility
Do you want to increase your traffic from AI Search? Bing explains how to do it.
In a recent blog post, Bing explained that:
- AI repurposes your content into an easy-to-read summary with clickable links
- Your highest priority should be to create high-quality content
- Online publishers should also focus on these three signals: citations, impressions, and placement in AI answers
Bing was quoted as saying, “As AI-powered search reshapes how people explore information, more of the journey now happens inside the experience itself.”
Essentially, Bing is encouraging you to show up in review sites, build relationships, and try to get in front of customers as much as possible.
You can read the entire blog here.
11. TikTok Ban Update: Deadline is Expiring Soon
It’s almost the end of 2025, and the TikTok ban still hasn’t been enforced. With the fourth extended deadline coming up on December 16th, many people are wondering what will happen.

Back in October, U.S. Treasury Secretary Scott Bessent was quoted as saying, “We finalized the TikTok agreement in terms of getting Chinese approval, and I would expect that would go forward in the coming weeks and months, and we’ll finally see a resolution to that.”
However, with the deadline approaching and no deal having been announced, marketers and consumers alike are wondering if Americans will be bringing TikTok into 2026.
Is no news good news? We’ll find out in the next week or so.
Weekly Homework:
- Review your Black Friday through Cyber Monday sales to see if your successes were aligned with the general ecommerce data.
- Brainstorm ways your brand can take advantage of the powerhouse success of TikTok and TikTok creators.
- Review AI traffic data from ChatGPT and Bing to see which strategies can help you find your way into more AI citations.
- Set up Google’s Partner Match tool to improve your YouTube targeting.
- Table any plans you might have had for ChatGPT Ads.
- Keep an eye on the upcoming TikTok ban deadline to see if you should include the short-form video app in your 2026 marketing or remove it from your plans.
Digital Marketing News 11/15/2025 to 11/21/2025
This week: AI citations vary dramatically, Cloudflare outage risks rankings, and Adobe acquires Semrush powerhouse.
Here's what happened this week in digital marketing:
1. New Report: Comparing Google Rankings to AI Citations
A new report produced by an SEO software company analyzed 18k+ queries and matched them using semantic similarity scoring across OpenAI’s GPT, Google Gemini and Perplexity, against traditional Google search results.
Here were some of the main findings:
- Perplexity showed a median domain overlap of 25-30% with Google results
- It shared about 43% of the domains it cited with Google, which makes sense since it is a live web retrieval tool.
- ChatGPT showed a median domain overlap of 10-15% with Google results
- It shared about 21% of its cited domains with Google
- Gemini showed a median domain overlap of just 4% with Google results
This report supports the fact that different AI systems interpret and value pages across the web in different ways. In this case, Perplexity actively searches the web for it to function, so its citation patterns are more similar to traditional search rankings.
2. Cloudflare Crashes Internet: How It Could Affect You Long After the Outage
A Cloudflare outage affected pretty much everyone this week, and if you’ve been on the receiving end of the burst of 5xx errors, you’ll need to pay attention to your crawl behavior in the upcoming weeks.
Here’s why: If Googlebot crawled your page during the outage and recorded a 5xx response, it will affect your ranking. Since Search Console is not updated in real-time, this means you might not see the dip in crawl activity or spike in server errors until a few days later.
If this happens, don’t panic. Instead:
- Record the timing and add an annotation to your analytics that this happened because of the Cloudflare outage.
- Keep an eye on your server logs, and if it returns to your baseline in a few days, you can mark it up as a contained event.
- Do not hit “Validate Fix” in the Search Console immediately. Wait at least 24 hours to see if the problem resolves itself before adding additional check failures to your reporting.
Let this remind you that where you show up in the SERP depends as much on server reliability as it does relevance. While Cloudflare is generally reliable, if you’re seeing decreases in your ranking, it could be due to an unreliable tool in your tech stack.
Action Item: Keep an eye on your crawl, error, and conversion metrics. If the situation isn’t resolved in a few days, it’s time to review your tech stack for issues.
3. Adobe Acquires Semrush
Announced earlier this week, Adobe will acquire Semrush, valued at $1.9 billion early in 2026 as long as it is approved by all necessary stakeholders.
Best known for its search marketing capabilities, Semrush has a wide variety of tools wrapped up into an all-in-one platform, offering keyword research, site audits, competitive intelligence, brand visibility, and tools that monitor how brands are referenced in large language models and traditional searches.
What else comes with this acquisition? Semrush’s recent deals include SEO assets Backlinko and publisher Third Door Media. The plan is to integrate Semrush and tools into Adobe products like Adobe Experience Manager and Adobe Analytics.
Stay tuned for more updates and what this will mean for marketers everywhere.
4. Google Improves Suspension Accuracy and Appeal Turnaround Times
If you’ve ever been hit with a Google suspension, you know how frustrating it can be to wait for your account to be reviewed. Google has heard you and is speeding up the process. They also announced an improved method to stop incorrect advertiser suspensions in the first place.

Over the past few months, Google has been working out the new process. They’ve focused on making the policies clearer. They also deployed AI to enhance their detection processes and rolled out a new and more effective review process for appeals.
So far, the results have been impressive:
- Over 80% reduction in incorrect account suspensions
- 70% faster response time to advertiser suspension appeals
- 99% of appeals are resolved within 24 hours
This is fantastic news for Google and advertisers alike!
5. Google Rolls Out New AI Tools to Improve Shopping
Just in time for the holiday season, Google rolled out new AI-powered tools to help make shopping easier.
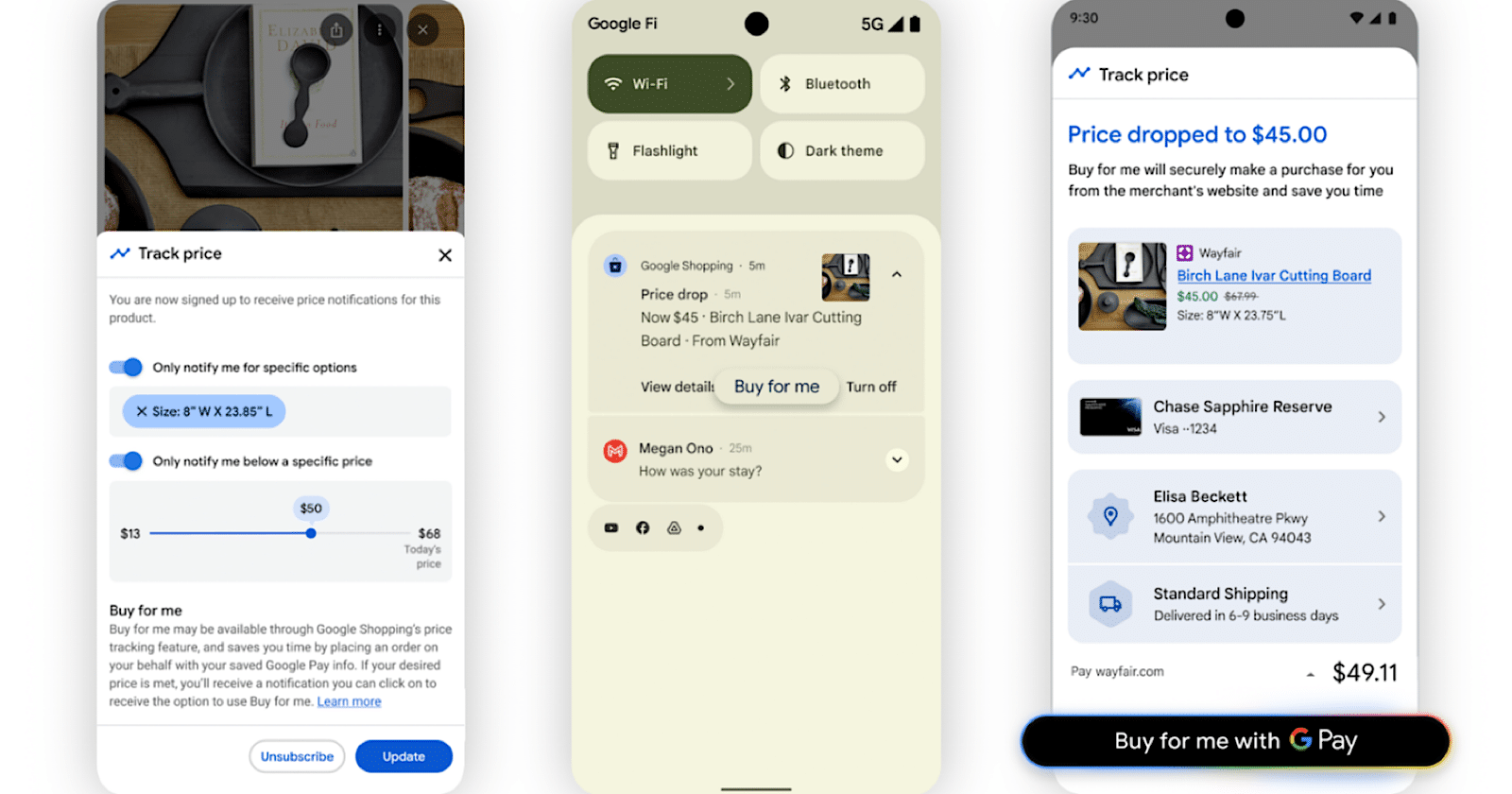
The new tools enable:
- Conversational shopping searches in AI Mode
- The ability to track prices and complete purchases through AI agents
- An AI-powered calling feature that will call local stores to ask questions and check stock
Local calling is currently only available for a limited set of shopping categories, but is expected to roll out to more stores over time.
The other AI tools are focused on the US market. Google is still working on broader merchant eligibility and expanding the functionality to an international market in the future.
6. Google Drops New Demand Gen Tools
AI Mode and Shopping aren’t the only Google products getting a boost. The tech giant also dropped some new features for Demand Gen Ads.

Since the beginning of 2025, Demand Gen users have seen an average 20% increase in conversions and conversion values, and these new tools aim to increase that average further.
The new features include:
- AI Image Enhancements: automatically create and optimize images
- Video Enhancements: automatically create video variations to improve performance amongst screens and attention spans
- Asset Uplift A/B Experiments: the ability to run creative tests on your content to leverage your best-performing assets
- Brand Suitability Controls for YouTube Feed and Discover: new controls for YouTube Home Feed, Watch Next, and Discover
If you’re a Demand Gen user, you should check out these tools to see how they can improve your holiday campaigns.
7. Study Reveals Insights into AI Overview Keywords
A new Brightedge study revealed valuable insights into AI Overview keywords.
The study revealed that Google retained only 30% of AI Overviews at its peak. The categories with the highest retention rates included:
- Grocery: 56%
- TV & Home Theater: 43%
- Small Kitchen Appliances: 37%
The categories with the lowest retention included:
- Furniture: 3%
- Home: 7%
- Apparel: 23%
If you’re trying to claim a spot in those lower categories, it could be harder because they have a higher turnover rate. Things that worked for the higher retention categories included comparison content, specifications, and “how to” content.
The biggest takeaway? Research queries win and transactional queries lose. When creating content, make sure you’re crafting it to answer questions rather than to sell immediately.
Why We Care: If you want your content to end up in a Google AI Overview, you have to create content that the algorithm is looking for. Studies like these pull the curtain back to give us valuable insight into what is working and what isn’t.
8. Gemini 3 Powers AI Mode
Gemini 3 is now available in AI Mode for subscribers within the US.
In the content of search it was designed for state-of-the-art reasoning and multimodal understanding. That means this new model should be able to explain advanced concepts, work through more complex questions and offer support to searches that have interactive visuals.
AI mode will return your results in a responsive layout, delivering images, tables, grids and other structured elements when necessary to provide users with a clear answer to their search.
Additionally, Google will be able to access more pages per question when scanning the internet for answers with a new deeper query fan-out. This matters to marketers because it could change which sites receive links or citations, and overall will impact the way results show up.
9. TikTok’s Major Holiday Shopping Push
Everyone is pushing sales at this time of year, but TikTok is raising the bar with new TikTok Shop Partners (TSP) incentives.

New incentives circulating include:
- Daily GMV Incentive Program: TSPs can receive cash incentives between $5,000 and $20,000 based on the amount of GMV growth between October 1 and December 31
- Onboard and Upgrade Incentives: TSPs can earn up to $10,000 in cash for upgrading through the TSP rankings
- Vertical Creator Incubation Incentive: TSPs can earn between $1,000 and $10,000 per creator when they successfully incubate TikTok’s target list creators
- Affiliate Service Incentive: Incentives between $1,000 and $5,000 in ad credits for increasing rank
There are also a variety of Black Friday/Cyber Monday challenges where creators and TSPs can earn between $2,000 and $25,000 in cash.
TikTok is also offering fully-funded and partially-funded coupons and discounts that cover all or part of a brand’s marketing costs, as well as invitation-only flash sales.
Why We Care: With many consumers turning to social media like TikTok to influence their holiday shopping, now is an excellent time for brands to zero in on these TikTok challenges to both sell their products and earn valuable incentives for using the platform to do so.
10. TikTok Launches Holiday Campaign Hub
Speaking of TikTok, the digital platform recently launched a Holiday Hub to help brands make the most of their holiday campaigns.

The guide helps advertisers learn more about how to use TikTok ads, as well as how to use the app to gain traction and raise brand awareness for your business.
In the guide, TikTok claims that:
- 3 in 4 users say they are likely to buy from a brand they’ve seen on TikTok Shop
- 88% of small businesses that use TikTok Shop say it made them sell more products
- 80% of users took an action after seeing holiday content on TikTok
The bottom line? TikTok is one of the best platforms to get your products in front of the right people, so don’t miss your chance to make this your best holiday season ever.
11. X Shares Holiday Advertising Tips in Hopes of Winning Back Advertisers
X wants to get a part of your holiday advertising puzzle! The social media platform updated its Holiday Marketing Hub with some tips on how to improve your X ROI.

The platform noted that:
- 1 in 3 X users will plan before shopping
- 39% find inspiration in X ads
- 69% of X users will spend more this year than last year
The biggest takeaways include:
- The best performing ads are between 50-100 characters.
- Ads should create urgency, but still maintain authenticity.
- Provide only one exit point to keep your message laser-focused.
- Use a clear call-to-action.
- Lead with your logo and front-load messaging.
- Caption everything!
Read all of the data, insights, and tips X has to offer on how to improve the ROI of your ads on X here.
12. Consumers Now Prefer Traditional Content Over genAI Content
A recent eMarketer study shows that AI-generated content is losing steam with audiences.
The study revealed that:
- 32% said that AI has negatively impacted the creator economy, up from 18% in 2023
- 41% said that AI has improved the diversity of creator content, up from 35% in 2023
- 32% said that AI has positively impacted the creator economy, down from 34% in 2023
Perhaps most shocking, though, was that 26% of those surveyed preferred genAI content to traditional content. This is down 34% from the 60% who said they liked genAI content over traditional content.
Could we be seeing a balance between AI and human-generated content emerging?
Weekly Homework
- Keep an eye on your crawl, error, and conversion metrics to see if your SERP ranking will be affected by this week’s Cloudflare outage. If the situation isn’t resolved in a few days, it’s time to review your tech stack for issues.
- Download and review Brightedge’s Google AI Overview report to see how you can use content to increase your brand’s odds of ending up in the popular SERP position.
- Download TikTok’s Holiday Marketing Hub for valuable ideas on how to increase your sales on social media.
- Brainstorm ways to use TikTok Shop to increase the amount of sales you make this holiday season, while also tapping into valuable TSP cash and ad credit incentive opportunities.
- If you want to advertise on X, or improve your existing campaigns, check out the platform’s new Holiday Marketing Hub for valuable data and tips.
- Evaluate your Demand Gen Google Ads to see how the new AI tools could help you improve your campaigns.
Digital Marketing News 11/8/2025 to 11/14/2025
This week: Reddit shoppers research earlier, ChatGPT may get PPC ads, TikTok partners with iHeartMedia.
Here's what happened this week in digital marketing:
1. US Ecommerce Sales Up 8.2% in October
If you’re like any other marketer, you are probably firming in Black Friday/Cyber Monday mode. While much of the early reporting indicated signs of a declining holiday season, the reports from October are somewhat hopeful.
According to Adobe Analytics:
- Amazon’s Prime Big Deal Days brought in $9.1 billion from US shoppers in 2 days
- Those two days showed a 7.3% YoY increase
- October’s overall online sales rose 8.2% YoY to $88.7 billion
- Sales from social media sites grew 28%
- Purchases driven by influencers and affiliates were up 15% from last year
These findings align with the National Retail Federation’s forecast of a historically strong holiday sales season. The NRF predicts that sales will rise between 3.7% and 4.2% from last year, putting total retail sales between $1,012.2 billion and $1,017.1 billion once all is said and done.
Biggest Takeaway: Consumers are leaning into social media and influencer marketing, so be sure to add that to your holiday sales strategy, if you haven’t already.
2. Reddit: 79% of Americans Are Researching More Before Shopping
Reddit released new tips for brands that want to go big this holiday season, and the biggest takeaway? Consumers aren’t waiting for Black Friday to start buying presents.

In the report, Reddit was quoted as saying, “[t]his year, shoppers aren’t waiting for Black Friday or Cyber Monday. With prices fluctuating and inventory unpredictable, they’re starting earlier to feel in control. Unlike previous years, they’re not impulse buying - 79% of Americans plan to research more before purchasing, comparing products, reading reviews, and seeking genuine recommendations from real people.”
Reddit also notes that, “[i]n the days leading up to Prime Day, Reddit communities were buzzing with shopping strategies, deal comparisons, and wish lists. During the event itself, views of Prime Day conversations exploded - skyrocketing more than 150x and peaking on day two as Redditors shared their best finds in real time.”
The top gift categories being researched on Reddit included:
- Gaming
- Electronics
- Apparel and accessories
- Media and entertainment
- Beauty and personal care
You can read more of Reddit’s findings and tips here.
Why We Care: If shoppers are starting now, brands should, too. With so many people turning to Reddit for their pre-purchase research, you need to consider how to get your brand involved in those discussions. Focusing on relevant keywords and topics could help your Reddit Ads, as well as organic Reddit discussion threads.
3. Reddit Launches New Interactive Ad Options
Reddit has been making some big moves in the PPC space. This month, they introduced interactive ads.
In a press release, Reddit explained that, “Interactive Ads are a Reddit-unique ad unit that lets brands build custom, interactive ad experiences directly for Reddit’s 100,000+ communities – inviting redditors to play, participate, and explore directly within the ad itself. Interactive Ad units range from fully bespoke campaigns and creative activations to low-lift, high-impact, repeatable templates like countdowns, quizzes, dynamic reveals, and trivia, offering flexibility based on creative goals and investment needs.”
Whether these ads are successful or not still remains to be seen, but with 116 million active daily users who spend 24 minutes a day in the app, they might be worth considering.
4. PPC Ads Could Be Coming to ChatGPT
Even though OpenAI’s founder, Sam Altman, had previously stated that he wasn’t a fan of ads on ChatGPT, he has recently expressed a change in opinion.
When asked about his willingness to add PPC ads to the platform, Altman said, “there’s a kind of ad that I think would be really bad… There are kinds of ads that I think would be very good or pretty good to do. I expect it’s something we’ll try at some point. I do not think it is our biggest revenue opportunity.”
With ChatGPT gaining more attention as a search engine, the addition of PPC ads could be a game-changer for brands, especially those that are already appearing in ChatGPT results.
While the development of these ads seems to be a way out, Altman's change in stance on allowing ads on the platform at all is a good sign for marketers desperate to reach AI users and new audiences.
5. TikTok and iHeartMedia Partnership Aims to Help Creators and Brands Improve Audio
TikTok recently announced a high-profile partnership with iHeartMedia. This partnership aims to help TikTok creators expand into audio formats, including podcasts, radios, and live events.

The partnership introduces the TikTok Podcast Network, with up to 25 newly created TikTok creator podcasts, as well as TikTok Radio, and iHeartRadio + TikTok Live Events, similar to the heavily attended iHeartRadio Music Festival and the iHeartRadio Jingle Ball.
In the press release, TikTok was quoted as saying, “iHeartMedia, the leading audio company in America, and TikTok, the world’s leading destination for short-form mobile video, today announced a groundbreaking, multiplatform partnership that will bring TikTok creators into iHeart’s ecosystem. This collaboration includes the launch of the TikTok Podcast Network, which will feature up to 25 new podcasts hosted by TikTok creators, as well as a national broadcast and digital radio station, and a series of live event integrations.”
Why We Care: This is an incredible opportunity for brands with podcasts and audio offerings to expand their content on the wide-reaching app. Even if your brand doesn’t have a podcast, getting your product or service featured on the brand-new TikTok Podcast Network, on TikTok Radio, or at an iHeartRadio live event could help expose your brand to a whole new audience that was previously unreachable.
6. TikTok Expands Access to Bulletin Boards Feature
Speaking of TikTok, the short-form video app also recently expanded access to its newest feature: Bulletin Boards.
First tested back in June, Bulletin Boards have become an easy way for brands to connect with their audiences, boost engagement, and generate loyalty. Many brands, including People Magazine, have found success with this one-to-many messaging option, using it to share text, images, and video updates in concise, direct-to-consumer messages.
Follow these steps to access your TikTok Bulletin Board:
- In the TikTok app, tap Inbox at the bottom. From here, if you receive a banner notifying you about bulletin boards, tap “Try it” to get started.
- Tap the “Chat” button at the top.
- Tap “Create a bulletin board.”
- Turn the “Show on profile” setting on or off to change the visibility of your bulletin board.
- Tap “Create” to open your bulletin board.
You can use it as a way to keep your audience engaged with key events or updates, which could be critical to your holiday season sales.
7. Negative Google Ad Scams Are On The Rise: Here’s What to Do
Have you been targeted by a negative review extortion scam? If so, you’re not alone. Google says that they’re becoming so popular that they needed to launch a new form solely to keep track of them.
The scam involves a sudden increase in 1-star or 2-star reviews on a business’s Google Business Profile, followed by a demand for money to remove the fraudulent reviews.
If this happens to you, don’t panic. Follow these tips from Google:
- Do not engage or pay the posters.
- Do not try to resolve it yourself.
- Gather all evidence immediately, including screenshots.
- Report all communication and evidence directly to Google using the newly launched form.
While this scam is disheartening, especially during this time of year, some businesses are reporting success with the form. One business noted on a Local Search Forum that all 11 fraudulent reviews were removed in a little over 24 hours after they used the form to report it to Google.
8. Stagwell & Palantir: A New AI-Powered Marketing Platform Is Coming
If you’ve been looking for a new tool to help you identify, segment, and understand your target audiences, this new tool from Stagwell and Palantir might be what you’ve been looking for.
The partnership was announced earlier this year, and reportedly, the tool is getting closer to release. In a joint press release, the tech brands said that they are “already seeing client adoption of its early MVP model in the United States through Stagwell's leading media company Assembly. Stagwell plans to roll out the offering to the broader network and clients on an opt-in basis in the coming months.”
The tool, reportedly called the Audience Creative and Optimization System, is designed to help large enterprises go through “tens of millions of records to identify, segment, and understand audiences for improved brand strategies and optimized ROI.” Stagwell says that one key aspect that sets their tool apart from others is the “use of differential privacy technology to protect data.”
If you’re a large enterprise that is getting stuck in the mud of analyzing millions of pieces of marketing data, this new tool could be a lifesaver.
9. Google Ads Asset-Level Reporting to Display Campaigns
Do you want to dive deeper into your Google Ads Display Campaigns? Thanks to the newest update, you can!
Just this week, Google rolled out asset-level reporting for Display campaigns. This a big step toward moving Display Ad visibility closer to the visibility already available for Performance Max campaigns.
The new updates will allow Google Ads users to:
- Compare performance of each creative asset.
- View when assets were last updated to track iteration history.
- Decide which assets to keep, refresh, or remove based on data.
You can learn more about this Google Display Ads update here.
10. Brand Inclusions Appear in Standard Shopping Campaigns
*Cue Mariah Carey’s voice* It’s time!
Google finally introduces brand inclusion controls to give advertisers management of which brands can appear in their shopping ads.
This long-awaited feature lets advertisers add or remove brand lists within the ad group targeting in both PMax and Standard Shopping campaigns. This update allows brands to protect their budgets, eliminating wasted ad spend on unwanted traffic.
Advertisers gain control and efficiency over Standard Shopping ads, instead of relying on automated campaign types. Gain control and efficiency for powerful upgrade in advertising.
11. Google Launches Ads Advisor and Analytics Advisor to Global Users
Google is launching new Ads tools left and right. This time, it’s Ads Advisor and Analytics Advisor.
Built on Gemini, Ads Advisor can:
- Generate recommendations to improve ads
- Directly apply recommended changes (with user approval)
- Analyze and adjust things like target ROAS, bids, and budgets
- Implement focused sitelink extensions
- Diagnose performance shifts and propose fixes
- Flag policy violations and suggest edits to copy, keywords, and headlines to remove the violations

Also built using Gemini, Analytics Advisor offers a conversational experience that delivers specific metrics, generates visualizations, and provides valuable insights.
These new tools will be available for English-language Google Ads and Google Analytics accounts in early December. To access them, simply log in to your account and use the in-product advisor interface.
12. Google Simplifies Search Results
Google is cleaning up its search results and removing support for certain structured data types in Search Console and its API starting January 2026. The goal: a simpler, more focused search experience.
For SEOs, that means auditing your structured data now. Check if your schema or reports depend on data types being phased out.
Why We Care: Technical SEO is shifting toward quality over quantity. SEOs must focus on clear, useful markup that enhances user understanding, not just rich results.
Weekly Homework:
- With more and more signals that consumers are trusting social media and influencer campaigns to help them make informed purchases, consider different ways you can add these strategies to your holiday sales campaigns.
- Read the Reddit holiday tips to see how you can boost the conversation around your brand this season.
- If Reddit Ads are part of your content marketing strategy, consider exploring how the new interactive ad feature can boost engagement with your target audience.
- Between the partnership with iHeartMedia and the expansion of Bulletin Boards, there are new ways to boost your engagement and reach on TikTok. Check out each new tool to see how you can use it to your brand’s advantage.
- Keep your eyes peeled for fraudulent reviews on your Google Business Profile. If you are a victim of the extortion scam, use the newly-launched form to report it to Google