Trying to optimize your website for search engines? Luckily, you have plenty of tools at your disposal.
For web-based businesses looking to rank higher in Google search results, your best plan of attack is to boost your search engine optimization (SEO) using meta tags.
In fact, meta tags are one of the fundamental building blocks of SEO.

What We’ll Cover:
- What are Google Meta Tags?
- Why Meta Tags Matter
- Best Practices for Google Meta Tags
Despite being a common term when considering how to develop a website and grow traffic, meta tags are often overlooked when discussing website optimization.
However, without it, today’s websites wouldn’t be properly indexed or displayed to users in search engines.
In this guide, we’ll be taking a closer look at what meta tags are, why you need them, and how they can help your company succeed.
What are Google Meta Tags?
The word “meta” is an abbreviation for metadata. Meta tags are essentially text within the code of a webpage that describes the contents of that page to search engines like Google, Bing, and Yahoo. This supplemental data includes information like page title, description, and content type.
Meta tags have left a conflicting legacy as many marketers in the past experimented with and manipulated search engine algorithms through keyword stuffing.
To combat this, Google altered their algorithm on how they manage and review meta tags.
Here are some examples of some of the most common meta tags used for SEO:
Title Tags: The title tag is perhaps the most important SEO component on a webpage. It’s what Google pays the most attention to when determining what your page is all about.
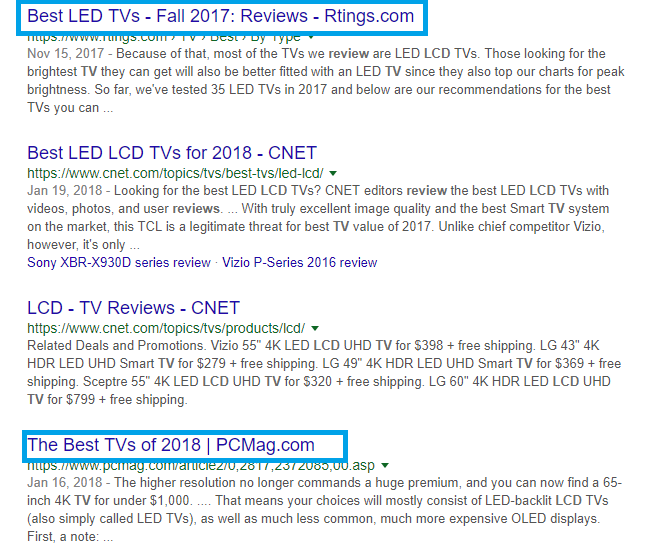
Your webpage’s title tag is what will appear in Google search results as a blue clickable hyperlink. You should think of the title tag as the chapter title in a book. A well-crafted title tag can help maximize clicks from the search engine results pages. That’s why it’s important to make sure each page’s title is unique, descriptive, and optimized for social sharing.
Meta Descriptions: Following title tags, the meta description is the subsequent most important meta tag. While meta descriptions don’t directly impact your search engine rankings, they are intended to help improve your click-through rates from the search engine results pages. That’s because the meta description is your “organic ad copy,” which is what generally shows up beneath the title tag as the snippet of preview text in the search results.

Meta Keywords: A series of keywords, separated by commas, meta keywords were once primary ranking factors. However, post-2009, this form of meta tag is no longer a factor in Google’s search engine algorithm.

Meta Robots: These tags can be useful under specific circumstances. The meta robots basically provide search engine spiders, including Google, with certain commands.
Put simply, you’re instructing the search engines with what to do with your pages:
- index/noindex: Tells the search engines if your page should be shown in search results or not.
- follow/nofollow: Tells the search engines what they should do with the links on your pages (whether they need to “follow” your links to the subsequent page or not).
- noarchive: Tells the search engines to not show a cached link to a webpage page in search results.
- nocache: Same as noarchive, but applies only to Internet Explorer and Firefox.
- nosnippet: Tells the search engines to not show a meta description or video preview for your page in search results.
- notranslate: Tells the search engine not to provide translations of this page in search results.
Schema: Schema is one of the more recent types of meta tag to come about. Schema is basically a type of markup that helps label various parts of a website so search engine algorithms can better understand what type of content is available on the site. There are a variety of schema that you can include on your website in order to help Google categorize your specific business, products, or other important information. If you’re a smaller business, the most key type of schema for local SEO is organization schema. In this schema, you need to list your business name, address, phone number, and other details.
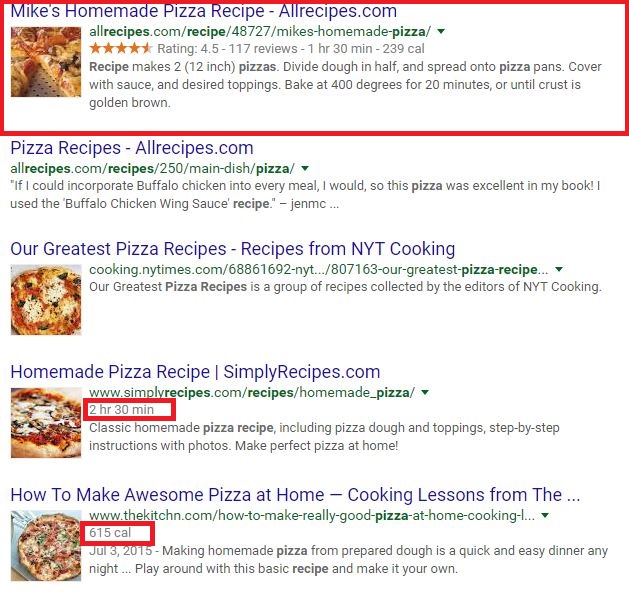
Why Google and Meta Tags Matter
Search engines place value on a positive user experience above all else, and that includes ensuring that your site can adequately satisfy a user’s query.
As mentioned previously, meta tags offer search engines a lot more details about your website, as well as the visitors who interact with your site in the search engine results pages.
Another key differentiator is that they can be optimized to bring to the forefront the most important elements of your content in a clear and concise way and make your website more noticeable in search results.
Best Practices for Google Meta Tags
As a marketer, you spend a considerable amount of time carefully crafting content for both your readers and your customers. But, you need to put just as much time and energy into creating meta tags for search engines. To help search engines like Google correctly identify and categorize your pages, be sure to keep the following tips in mind.
Best Practices for Title Meta Tags
- When it comes to title tags, less is more. Most search engines tend to cut off page titles that are too long. So, stick to a unique SEO title that falls within the range of 50-60 characters, including spaces.
- For your home page, start by using the name of your business. From there, you can start adding other data like your location or your product/service to fill in the remaining characters.
- For other pages on your site, be sure to use a title that is easily readable and fitting for the content on that page. Put yourself in the mindset of your customer. What would they search for?
- Incorporate the keyword in the title early on and avoid stuffing keywords.
Best Practices for Meta Descriptions
- Similar to title tags, search engines will usually cut off meta descriptions that are too long. Again, you want to keep it descriptive, but brief. In this case, you want to limit your description tag to 155 characters or less, including spaces.
- The description needs to expand upon the title of your page. Remember—this is your chance to really persuade someone to click through to your website and learn more.
- Try using keywords that you’re currently targeting and re-emphasize the keywords you have already used in your title. For example , if you sell pastries, be sure to use “pastries” in both your title and description tags. If you want to focus on “homemade pastries” or “gourmet pastries,” then use that particular verbiage.
Best Practices for Meta Robots
- One thing to watch out for with the meta robots tag is to not prevent any pages from getting indexed. For example, you might have a page that has a “noindex” tag that you want to get indexed. Feel free to use tools like Screaming Frog SEO Spider, which are designed to scan your website for incorrect noindex tags.
- Try not to use multiple meta tags as it may cause issues with the code.
- Since search engines can recognize attributes and values in uppercase and lowercase, go with lowercase. It will greatly improve code readability.
Best Practices for Schema
- As information and pages continue to change, be sure to update your schema accordingly. Going through a rebranding process? Update your schema. Are you repositioning a product in your market? Update your schema. It may be tempting to let schema updates fall by the wayside, but offering incorrect information for your product/service would be damaging to your business.
- org has a comprehensive list of some of the most common types of schema markup. Find the types that are best suited for your business and markup as much as you can.
- As noted in the disclaimer on Schema.org, “You should mark up only the content that is visible to people who visit the web page and not content in hidden div’s or other hidden page elements.”
Final Thoughts
When used in conjunction with other SEO marketing practices, meta tags can be a godsend for both search engines and searchers.
Not only do they help improve the user experience and the presentation of your business information, but it can lead to better search engine visibility and more site traffic.
If you haven’t already, it’s time to start incorporating meta tags into your SEO strategy and watch your rankings skyrocket!
FAQ
1. Does Google use keyword meta tags?
Since 2009, the keyword tag has proven to be no longer useful as so many individuals abused the feature via keyword stuffing and algorithmic manipulation.
As Google explains, “Our web search (the well-known search at Google.com that hundreds of millions of people use each day) disregards keyword meta tags completely. They simply don’t have any effect in our search ranking at present.”
2. Does Google use title tags?
Regarding meta tag optimization, Google will usually only display the initial 50–60 characters of a title tag. When titles are capped at 60 characters, roughly 90% of titles can be expected to display properly.
3. How many meta tags can I use?
There’s not exactly a limit on how many meta tags you can use. You can have as many as you prefer, but meta titles and meta descriptions are the two most important meta tags in the bunch.