In search engine optimization, you often run into really random technical issues. The reason is that you might have one piece of code telling the search engine one thing and another giving it a different direction. In so many cases, the search engine just gets confused and it limits the website from getting traffic.
One situation that has come up a few times in my career is having a client ask me if they should use rel canonical and no index no follow on the same page.
Should use rel canonical and no index no follow on the same page?
It is industry standard to use one or the other. Generally, best case is 301 redirect, next it is rel canonical, next it is no index and no follow and last it is robots.txt.
If Google crawls the no index and no follow first, the rel canonical may be ineffective. The purpose of the rel canonical is to pass the link weight on to the alternate version and tell Google that this is the correct version of the page for the index.
Here are the best articles on the topic.
- https://www.seroundtable.com/archives/020151.html
- https://productforums.google.com/forum/?hl=en#!category-topic/webmasters/crawling-indexing–ranking/0sqRrolO_Ss
- https://searchengineland.com/removing-urls-from-the-index-in-bulk-159646
- https://www.webmasterworld.com/google/4563444.htm
- https://googlewebmastercentral.blogspot.co.uk/2013/04/5-common-mistakes-with-relcanonical.html
Important points on rel canonical and no index no follow
This is taken directly from a webmaster thread commented on by Google’s Jon Mueller.
“This is definitely an interesting question :-). Before the rel=canonical link element was announced, using noindex robots meta tags was one way that webmasters were directing us towards canonicals, so this is certainly something we know and understand. However, with the coming of the rel=canonical link element, the optimal way of specifying a canonical is (apart from using a 301 redirect to the preferred URL) is to only use the rel=canonical link element.”
Although Google states this clearly, I have to say that the documentation is very sparse. Intuitively, I have always recommended one or the other. But it could be considered that having the no index no follow lower on the page might allow Google to find the rel canonical, rank the appropriate page and then find the no index no follow and confirm the drop of the page in the index. Because of this, I went straight to John Mueller at Google.
Question Asked Directly to Google
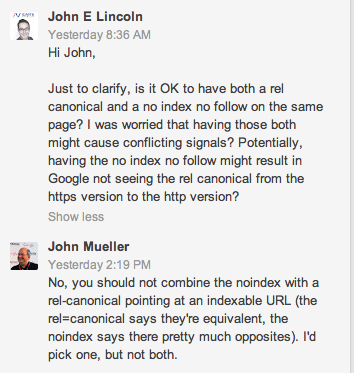
Noindex no follow rel canonical same page
It should be noted that no index and the Google URL removal tool are the only confirmed ways to completely remove a page from the index.
“The NOINDEX meta tag gives a good way — in fact, one of the only ways — to completely remove all traces of a site from Google (another way is our url removal tool). That’s incredibly useful for webmasters. The only corner case is that if Google sees a link to a page A but doesn’t actually crawl the page, we won’t know that page A has a NOINDEX tag and we might show the page as an uncrawled url. There’s an interesting remedy for that: currently, Google allows a NOINDEX directive in robots.txt and it will completely remove all matching site urls from Google. (That behavior could change based on this policy discussion, of course, which is why we haven’t talked about it much.).” Matt Cutt’s Google
It is important to point out that if you block your website with robots.txt Google cannot see a rel canonical or a no index tag.
Summary on rel canonical and no index no follow
I believe that Google stated it pretty clear. Use rel canonical or no index no follow, not both. So I sticking with that, and I think you should too.